
Raku RSS Feeds (individual feeds | subscribe to all via Atom)
Elizabeth Mattijsen (Libera: lizmat #raku) / 2026-07-30T19:55:27After having done the Rakudo Weekly for a year, Steve Roe indicated that they needed a break from doing the Rakudo Weekly, and from Raku more generally. I would like to thank Steve for their work on the Rakudo Weekly and the Raku Advent Calendar, for the (re-)design of the raku.org and raku.foundation websites, and for the many modules they’ve added to the Raku ecosystem.
This also means that yours truly will be taking over doing the Rakudo Weekly again, at least until someone else will stand up to do this. It isn’t that hard to do, really. So please leave a comment if you’re interested in taking over this important and well liked community service!
Here we go for a packed 3-week Rakudo Weekly!
In the blog post Governance and The Raku Foundation the Executive Board of the Raku Foundation describes their plans on forming a Supervisory Board, thematic working groups (such as for the already existing Documentation, Infrastructure and Marketing working groups, and a new CRA working group), and more formal committees (such as the already existing Raku Steering Council, Community Affairs Team, and the new CVE Numbering Authority).
And on the note of the Cyber Resiliency Act, the EU Commission has just published new guidance to support timely Cyber Resilience Act implementation, a must read if you care about CRA.
Please support the Raku Foundation financially: all donations are welcome, however small or large they may be! and if you want to keep up-to-date on Raku Foundation developments, make sure you register your interest!
Andrew Shitov has been flying a lot under the Raku radar the past years (due to Covid and war), but has come back with a vengeance. So they deserve a Playground, rather than a Corner!
First of all, they completed the Complete Raku Course grant, now visible at course.raku.org! Andrew, being a prolific writer about the Raku Programming Language, also made all of their books available in an online format, such as:
But that’s not all: after writing a book about creating a compiler, they decided to create a Raku compiler in C++, called Raku++ (/r/rakulang comments). If you’re interested in finding out about the “how”, check out Raku++: The Long Read!
Building on Raku++ Andrew also implemented raku.online, an interactive browser-based playground for Raku introduced in the Raku in a Browser blog post.
To top it all off (at least for now), they started a series of blog posts highlighting unique features of the Raku Programming Language, with the first installment: Raku: a Language Where 0.1 + 0.2 is 0.3.
So, lot’s of kudos to Andrew!
Andrew Shitov was not the only one creating an online Raku experience! Fernando Correa de Oliveira also created one, using the Rakudo compiler in the background: Raku Playground!
Tim Nelson has suggested there is a need for an (additional) web site for the Raku Community, tentatively called “involvement.raku.org”. They’ve made a mock-up of it and are inviting you to comment on the concept (and to checkout inspiration from earlier blog posts: Pathways of Entry and Involvement and Troupes).
Anton Antonov wrote a blog post about recent developments regarding the Jacobian Conjecture and used Raku to create another counter-example in Jacobian conjecture counterexample by LLM.
John Haltiwanger has also been flying under the Raku radar the past months, but has been working on the Raku Intellij plugin. This has resulted in a 2026.2-beta.4 release in which we see the return of the entire (passing) test suite, and many other improvements with the highlighter and the text formatter. And crucially, the ability to actually open .rakumod files!
Weekly Challenge #384 is available for your perusal (as are Weekly Challenges #382 and #383).
Too many developments in the past 3 weeks, especially in RakuAST to provide a good overview for. The good news is that there is now a Rakudo 2026.07 release with the RakuAST approaching parity with the legacy backend, thanks to the work of Nick Logan using data from ecosystem module failures when running with RakuAST activated.
One nice feature that wasn’t really mentioned in the Rakudo 2026.07 announcement, were the general GDB plugin improvements for low-level (core) debugging, contributed by Timo Paulssen. Exciting stuff!
Developments since the 2026.07 release:
Wow, 3 weeks packed with big developments: some very nice, and some not so nice.
Please keep staying safe and healthy, and keep up the good work! Even after week 79 of hopefully only 209.
Meanwhile, still: Слава Україні! Героям слава!
If you like what I’m doing, committing to a small sponsorship would mean a great deal!
The Jacobian conjecture was (very) recently disproved by a counterexample found by Anthropic’s Fable 5. [MS1]. This blog post (notebook) demonstrates that counterexample using some of the built-in Raku functions and dedicated packages that facilitate symbolic computations, like “CortexJS”, [AAp1], “LaTeX::Grammar”, [AAp2], “Proc::ZMQed”, [AAp3], and “WWW::WolframAlpha”, [AAp4]. We implement and use a simple, guided, brute force Raku workflow to find three different points which the counterexample polynomial 3-dimensional (3D) transformation maps into the same 3D point.
In the comments of this X-post (and New Scientist article, [MS1]) it is pointed out that the counterexample found using Anthropic’s Fable 5 Large Language Model (LLM).
Remark: The points found in this notebook are different than those in the X-post .
In this section we provide a theoretical formulation of the Jacobian conjecture. For more a mathematically elaborated formulation see the Wikipedia article “Jacobian conjecture”, [Wk1].
Suppose u and v are polynomials of the variables x and y. Consider the 2-dimensional (2D) transformation (i.e., a vector valued function) F(x, y) := (u[x, y], v[x, y]). The Jacobian conjectures says that if the Jacobian determinant:
J = (∂u/∂x)(∂v/∂y) – (∂u/∂y)(∂v/∂x)
is a non-zero constant, then there must exist another pair of polynomials that invert transformation with the polynomials in u and v.
Below we show that the conjecture is not true using the 3D transformation polynomials proclaimed in this X post, [MS1].
Remark: This notebook is the Raku version of the Wolfram Language (WL) notebook “Jacobian conjecture counterexample by LLM”, [AAn1].
Remark: The Wolfram Desktop or Wolfram Engine is installed then the WL symbolic computations can be done via Raku-chatbook’s bash magic cell using wolframscript.
Here are the packages used in this notebook:
use CortexJS;use LaTeX::Grammar;use Proc::ZMQed;use WWW::WolframAlpha;use Data::TypeSystem;
Remark: The package “WWW::WolframAlpha” is available in any Raku-chatbook session, [AA1].
Here we define a sub to render matrices and vectors via LaTeX in Markdown magic cells of Raku-chatbook:
sub latex-matrix(@data) { ['$$', '\\begin{bmatrix}', @data.map({ $_».subst('$',:g).join(' & ') }).join(' \\\\' ~ "\n"), '\\end{bmatrix}', '$$'].join("\n")}
In this section the Anthropic’s Fable 5 found counterexample is exemplified using corresponding definitions and invocations.
Definition of the counterexample polynomial mapping as a list of LaTeX strings:
#%markdownmy @poly-map = '(1 + x y)^3 z + y^2 (1 + x y) (4 + 3 x y)', 'y + 3 x (1 + x y)^2 z + 3 x y^2 (4 + 3 x y)', '2 x - 3 x^2 y - x^3 z';latex-matrix(@poly-map)
The Jacobian matrix:
#%markdownmy @jacobian-matrix=cross(@poly-map, <x y z>).map({ 'D_' ~ $_.tail ~ '{' ~ $_.head ~ '}' }).map({ $_ ==> parse-latex() ==> evaluate() ==> to-latex() }).rotor(3);latex-matrix(@jacobian-matrix)
The Jacobian matrix — via wolframscript and the Wolfram Function Repository (WFR) entry JacobianMatrix):
#% markdownmy $proc = run 'wolframscript', '-code', "ResourceFunction[\"JacobianMatrix\"][{"\{@poly-map.join(', ')\}"}, \{x, y, z\}]//Simplify//Flatten", :out;my $res = $proc.out.slurp(:close);latex-matrix($res.split(/<[{},]>/, :skip-empty)».trim.rotor(3))
The determinant is a constant:
'\\det' ~ latex-matrix(@jacobian-matrix).lines[1 .. *-2].join("\n")==> parse-latex()==> evaluate()==> simplify()
# -2
We can directly find the determinant via WFR’s JacobianDeterminant:
#% markdownmy $proc = run 'wolframscript', '-code', "ResourceFunction[\"JacobianDeterminant\"][{"\{@poly-map.join(', ')\}"}, \{x, y, z\}]", :out;my $res = $proc.out.slurp(:close);
Here we verify that the expressions of the Jacobian matrix computed with “CortexJS” are the same as the ones computed with Wolfram Language:
my @cortex-js-exprs = @jacobian-matrix.flat(:hammer).map({ latex-interpret($_.trim.substr(1, $_.chars-2), actions => 'WL') });my $proc = run 'wolframscript', '-code', "Simplify[ResourceFunction[\"JacobianMatrix\"][{"\{@poly-map.join(', ')\}"}, \{x, y, z\}] - Partition[\{{@cortex-js-exprs.join(', ')}\},3]]", :out;my $res = $proc.out.slurp(:close);
# {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}
In the Wolfram notebook “Jacobian conjecture counterexample by LLM”, [AAn1], the Wolfram Language FindInstance was use to find points for which the polynomial map gives the same result. I.e.,
pi := (xi, yi, zi), i ∈ [1,2,3] ∧ pi ≠ pj ∧ i ≠ j.
In this section with Raku we do a more exhaustive point search using the results in [AAn1] as guidance.
Searching all three points is too slow. We use a two-stage computation: we find first a solution with two different points, then we find a third point that is different that previously found two.
Define a function that computes the polynomial mapping using the LaTeX strings of the (symbolic) definition above:
use MONKEY-SEE-NO-EVAL;my $poly-map-expr = '[' ~ @poly-map.map({ latex-interpret($_, actions => 'RakuAST').DEPARSE.subst('x', '$x', :g).subst('y', '$y', :g).subst('z', '$z', :g) }).join(', ') ~ ']';my &poly-map = EVAL('sub ($x, $y, $z) {' ~ $poly-map-expr ~ '}');
Verify definition of &poly-map:
&poly-map(1.1, 0.2, 1/2)
# [1.135332 3.27098 0.8085]
Search grid:
my $b = 6;#my @grid3d = (-$b, -$b + 1 ... $b) X (-$b, -$b + 1/2 ... $b) X (-$b, -$b + 1/100 ... $b);my @zs = (([\+] -1/36 xx 2_000).reverse, [\+] 1/36 xx 2_000).flat.grep(-$b ≤ * ≤ $b);#my @grid3d = (-$b, -$b + 1 ... $b) X (-1, -1/2, 0, 1/2, 1) X @zs;my @grid3d = (-$b, 0, $b) X (-1, -1/2, 0, 1/2, 1) X @zs;say @grid3d.elems;
# 6480
deduce-type(@grid3d):tally
# Tuple([Tuple([Atom((Int)), Atom((Int)), Atom((Rat))]) => 3888, Tuple([Atom((Int)), Atom((Rat)), Atom((Rat))]) => 2592], 6480)
Pre-compute polynomial mapping values:
my %poly-map-values = @grid3d.race(:4degree).map({ $_.Str => &poly-map(|$_) });%poly-map-values.elems
# 6480
Search for two point mapped into one:
my $k = 0;my $degree = 4;my @found;@grid3d.race(:$degree, batch => ceiling(@grid3d.elems / $degree)).map( -> @p { my @mp = |%poly-map-values{@p.Str}; if $k %% 500 { say (:$k) } $k++; for @grid3d -> @candidate { my @mpc = |%poly-map-values{@candidate.Str}; if (@mpc <<->> @mp)».abs.max ≤ 0.0001 && @p ne @candidate { @found.push( %(:@p, :@candidate, :@mp) ); say @found.tail; } }});@found.elems# ≈90 minutes
# k => 0# k => 0# k => 0# k => 0# {candidate => (-6 0 0.055556), mp => [0.055556 -1 0], p => (6 -0.5 0.305556)}# {candidate => (0 -1 -3.944444), mp => [0.055556 -1 0], p => (6 -0.5 0.305556)}# k => 500# k => 500# k => 1000# k => 1000# k => 1000# {candidate => (6 0.5 -0.194444), mp => [0.555556 3 0], p => (-6 1 0.555556)}# k => 1500# k => 2000# k => 2000# {candidate => (-6 0.5 0.305556), mp => [0.055556 1 0], p => (6 0 0.055556)}# {candidate => (0 1 -3.944444), mp => [0.055556 1 0], p => (6 0 0.055556)}# {candidate => (-6 0 0.055556), mp => [0.055556 -1 0], p => (0 -1 -3.944444)}# {candidate => (6 -0.5 0.305556), mp => [0.055556 -1 0], p => (0 -1 -3.944444)}# {candidate => (6 -1 0.555556), mp => [0.555556 -3 0], p => (-6 -0.5 -0.194444)}# k => 2500# {candidate => (-6 0.5 0.305556), mp => [0.055556 1 0], p => (0 1 -3.944444)}# {candidate => (6 0 0.055556), mp => [0.055556 1 0], p => (0 1 -3.944444)}# k => 3000# k => 3500# {candidate => (-6 1 0.555556), mp => [0.555556 3 0], p => (6 0.5 -0.194444)}# k => 4000# {candidate => (0 -1 -3.944444), mp => [0.055556 -1 0], p => (-6 0 0.055556)}# {candidate => (6 -0.5 0.305556), mp => [0.055556 -1 0], p => (-6 0 0.055556)}# k => 4500# k => 5000# {candidate => (-6 -0.5 -0.194444), mp => [0.555556 -3 0], p => (6 -1 0.555556)}# k => 5500# k => 6000# {candidate => (0 1 -3.944444), mp => [0.055556 1 0], p => (-6 0.5 0.305556)}# {candidate => (6 0 0.055556), mp => [0.055556 1 0], p => (-6 0.5 0.305556)}
# 16
Direct assignment — for faster setup of (consecutive, repeated) experiments:
sink my @found = {:candidate($(-6, 0, <1/18>)), :mp($[<1/18>, -1.0, 0.0]), :p($(6, -0.5, <11/36>))}, {:candidate($(0, -1, <-71/18>)), :mp($[<1/18>, -1.0, 0.0]), :p($(6, -0.5, <11/36>))}, {:candidate($(6, 0.5, <-7/36>)), :mp($[<5/9>, 3.0, 0.0]), :p($(-6, 1, <5/9>))}, {:candidate($(-6, 0.5, <11/36>)), :mp($[<1/18>, 1.0, 0.0]), :p($(6, 0, <1/18>))}, {:candidate($(0, 1, <-71/18>)), :mp($[<1/18>, 1.0, 0.0]), :p($(6, 0, <1/18>))}, {:candidate($(-6, 0, <1/18>)), :mp($[<1/18>, -1.0, 0.0]), :p($(0, -1, <-71/18>))}, {:candidate($(6, -0.5, <11/36>)), :mp($[<1/18>, -1.0, 0.0]), :p($(0, -1, <-71/18>))}, {:candidate($(6, -1, <5/9>)), :mp($[<5/9>, -3.0, 0.0]), :p($(-6, -0.5, <-7/36>))}, {:candidate($(-6, 0.5, <11/36>)), :mp($[<1/18>, 1.0, 0.0]), :p($(0, 1, <-71/18>))}, {:candidate($(6, 0, <1/18>)), :mp($[<1/18>, 1.0, 0.0]), :p($(0, 1, <-71/18>))}, {:candidate($(-6, 1, <5/9>)), :mp($[<5/9>, 3.0, 0.0]), :p($(6, 0.5, <-7/36>))}, {:candidate($(0, -1, <-71/18>)), :mp($[<1/18>, -1.0, 0.0]), :p($(-6, 0, <1/18>))}, {:candidate($(6, -0.5, <11/36>)), :mp($[<1/18>, -1.0, 0.0]), :p($(-6, 0, <1/18>))}, {:candidate($(-6, -0.5, <-7/36>)), :mp($[<5/9>, -3.0, 0.0]), :p($(6, -1, <5/9>))}, {:candidate($(0, 1, <-71/18>)), :mp($[<1/18>, 1.0, 0.0]), :p($(-6, 0.5, <11/36>))}, {:candidate($(6, 0, <1/18>)), :mp($[<1/18>, 1.0, 0.0]), :p($(-6, 0.5, <11/36>))};
Here we find all records for the gathered co-domain points and keeping the groups with more than three different points:
my %classes = @found.classify(*<mp>.Str).grep(*.value.elems ≥ 3).sort(*.key);deduce-type(%classes)
# Struct([0.055556 -1 0, 0.055556 1 0], [Array, Array])
Combine the points of each record group into one array of unique points:
my @point-groups = %classes.values.map({ $_.map(*<p candidate>).map(*.Slip).unique(with => {(@^a <<->> @^b)».abs.max ≤ 0.0001}) });@point-groups».elems
# (3 3)
Check the polynomial mapping gives the same co-domain point per group:
@point-groups.map(*.map({ &poly-map(|$_) })).map({ [eqv] $_})
# (True True)
[AA1] Anton Antonov, “Chatbook New Magic Cells”, (2024), RakuForPrediction at WordPress.
[MS1] Matthew Sparkes, “AI’s solution to 87-year-old riddle takes mathematicians by surprise”, (2026), New Scientist.
[MW1] MathWorld entry, “Jacobian conjecture”.
[Wk1] Wikipedia entry, “Jacobian conjecture”.
[AAn1] Anton Antonov, “Jacobian conjecture counterexample by LLM”, (2026), Wolfram Community.
[AAp1] Anton Antonov, “CortexJS”, (2026), GitHub/antononcube.
[AAp2] Anton Antonov, “LaTeX::Grammar”, (2026), GitHub/antononcube.
[AAp3] Anton Antonov, “Proc::ZMQed”, (2022), GitHub/antononcube.
[AAp4] Anton Antonov, “WWW::WolframAlpha”, (2024), GitHub/antononcube.
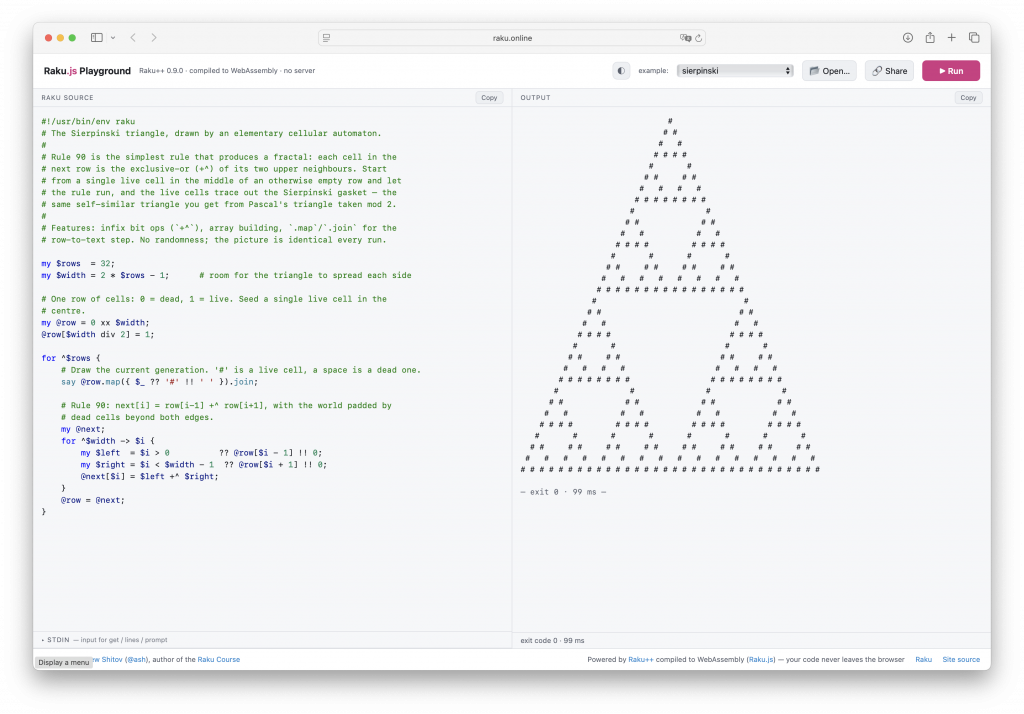
Raku is a rich programming language; it took years to design and implement. That’s why running it in a browser seems an ambitious goal. Nevertheless, that’s mostly possible. Meet raku.online — a fully standalone Raku++ engine called Raku.js running in a browser.
There are three main panels here: source code on the left, output panel on the right (both STDOUT and STDERR), and the input (STDIN) if needed below.
There are also a number of pre-defined examples that you can choose from to get familiar with Raku.js. For some of the examples, you can choose one of a few inputs to see how the program works in more detail.
Among the examples on offer are most of the Raku programs from the examples directory of the Raku++ repository. These include some programs to manipulate strings and numbers, regex and grammar programs, sleep sort, and—of course!—mandel.raku, the program from the Parrot era to draw the fractal.
Of course, Raku.js can execute not only the programs from the pre-defined list, but also programs that you can type yourself in the browser. As it is executed in the browser under the browser’s JavaScript engine, there are some limitations — for example, network connections, concurrency, and the recursion depth (while Raku++ does not limit you, for Raku.js its maximum is about 200 levels deep).
One of the particularly interesting features of Raku is Grammars (which are the next-level regular expressions, or regexes, if you haven’t hear of them yet). Grammars combined with the so-called actions allow you to parse text, and in particular, parse and execute programs in other programming languages.
That’s why the site demonstrates two interpreters of a couple of very different languages: Scheme and Forth. Here, you can run the interpreter written in Raku to run a program in Scheme or Forth, supplied in the STDIN window below the source code.
Enjoying Lisp/Scheme and Forth? Let’s push further and run a JavaScript and TypeScript interpreter. Right, it is written in Raku and is executed in the browser as a JavaScript program.
Want more? Run Perl in a browser under Raku.js running with JavaScript!
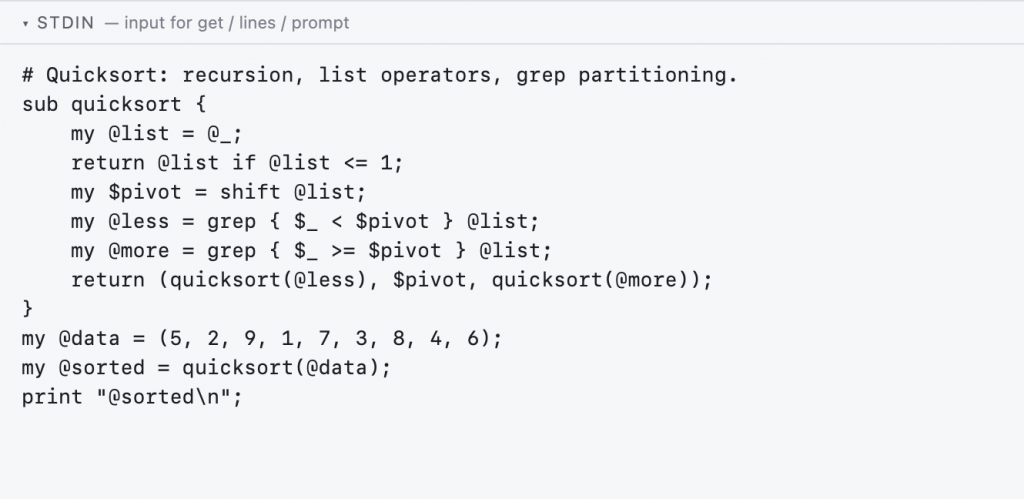
The JS/TS and Perl interpreters are 1500-2000-line Raku programs employing Raku Grammars. You can find more such showcases that Raku++ can execute in the showcase directory in the repository. It’s difficult to believe that such a chain — Raku in a browser parsing JavaScript — needs only about 300 milliseconds to run a FizzBuzz program.
[Update: Python too!]
Raku.js is Raku++ that is compiled to WebAssembly. If you are curious, examine the raku.online source repository to see the structure. The compiler behaves as the current version of Raku++ itself (with some obvious limitations mentioned above).
What you may find quite practical is that you can use Raku.js to run the Raku examples on your own sites. Here’s an example of a possible implementation of factorial in Raku:
sub postfix:<!>($n) {
[*] 1..$n
}
say 5!;
Just click the Run button and you get the immediate answer. No remote server is involved here: everything happens in your browser right now.
I used this feature to embed runnable code blocks into the new part of my Raku Course, which (the part) will be published soon [Update: published]. There are 50 mid-size exercises there, all with in-browser-runnable code blocks.
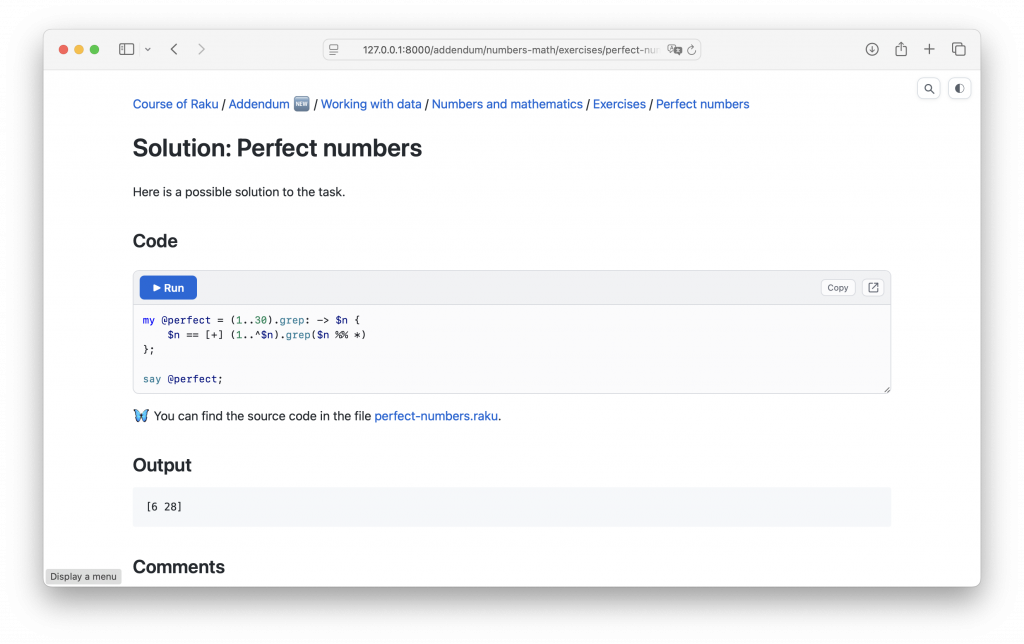
So, enjoy raku.online!
Programming languages are fascinating. Even if you think that these are the last days when you need to write code yourself, that only gives you more time to enjoy the beauty.
In this article I would like to showcase some of the small but astonishing features of Raku. Even if you never had a chance to install a compiler on your machine, you can run all the examples below in the online Raku playground straight away.
It is an obvious equation when written on paper, but when you employ floating-point arithmetic, you get a collection of various answers – the price of the trade-off between speed, compactness, and exactness.
In Raku, 0.1 + 0.2 equals 0.3 exactly:
say 0.1 + 0.2 == 0.3; # True
Run it in the online playground to confirm. In the rest of the article, the Raku code snippets are rendered inside the playground blocks. All you need is to press the Run button and see the magic. You can also navigate to the playground to play more on a bigger screen.
Similarly, 0.1 + 0.2 - 0.3 is an exact zero.
All this is possible as Raku treats these numbers as belonging to the Rat (rational) type of numbers. 0.1 is a fraction 1/10. 0.2 is the same as 1/5. And while say 1/3 does print a rounded 0.333333, that is only the display: underneath lives the exact ⅓, with the numerator and the denominator in easy reach:
say ⅓.numerator; # 1 say ⅓.denominator; # 3
And yes, Unicode fractions are understood, together with any kind of digits:
say ⅷ + ٣; # 11
The ⅷ here is a single Unicode character – the small Roman numeral eight – and ٣ is the Arabic-Indic digit three, the everyday three for hundreds of millions of people. Raku reads both as the numbers they are.
Raise a number to a power the way your maths teacher wrote it:
say 2⁵; # 32 say 5² + 12² == 13²; # True
The second line is the 5–12–13 Pythagorean triple, checked in one readable line.
An integer in Raku is as long as it needs to be. There is no 64-bit cliff to fall off, no special “big integer” import – the numbers simply grow:
say 2¹⁰⁰; # 1267650600228229401496703205376 say 10¹⁸ × 10¹⁸; # 1 followed by 36 zeroes say [*] 1 .. 100;
The square brackets in the last line are the reduction meta-operator: [*] places * between all the numbers of the range, so you get the factorial of 100 – all 158 digits of it:
93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000Number theory is on board too:
say 97.is-prime; # True say (2¹²⁷ − 1).is-prime; # True
The second number is a Mersenne prime of 39 digits, tested as casually as the small one. Notice the minus sign in 2¹²⁷ − 1: it is not the ASCII hyphen but the true Unicode minus, and Raku is perfectly happy with either.
Superscripts are not the only notation rescued from the maths textbook. The multiplication and division signs, and the comparison signs with the slash already crossed through, are all ordinary Raku operators:
say 7 × 6; # 42 say 10 ÷ 4; # 2.5 say 1 ≤ 2 ≤ 3; # True say 2 ≠ 3; # True
× and ÷ are the real multiplication and division operators (the ASCII * and / work too, of course). Comparisons chain the way they do in mathematics: 1 ≤ 2 ≤ 3 is a single condition, not a syntax error. And 10 ÷ 4 is the familiar Rat story again – the exact fraction 5/2, whose decimal display 2.5 this time needs no rounding at all.
Chaining also combines with the reduction meta-operator you met at the factorial: put ≤ between the square brackets, and [≤] chains it across every neighbouring pair of a list – a ready-made test that the list is sorted:
say [≤] 1, 2, 5, 9; # True say [≤] 3, 1, 2; # False
The constants you know from school are predefined:
say π; # 3.141592653589793 say τ == 2 × π; # True
(Type pi and tau if the Greek letters are far from your keyboard.) Infinity is a value in its own right: you can compare things with it, and you can build a range of all positive integers and politely take the first five:
say ∞ > 10¹⁰⁰; # True say (1 .. ∞)[^5]; # (1 2 3 4 5)
The range is lazy, so nobody attempts to materialise the rest of it.
Floats did not go anywhere – you ask for them with scientific notation:
say 0.1e0 + 0.2e0; # 0.30000000000000004
0.1e0 is a Num, an honest IEEE double, and with it comes the famous constant from the beginning of this article. Floats remain the right tool for physics and simulations; Raku simply refuses to make them the default meaning of a decimal literal.
Every example above runs in the raku.online playground, which is powered by Raku++, an independent implementation of Raku compiled to WebAssembly – the interpreter works entirely in your browser page. The reference implementation of the language is Rakudo, and everything shown here prints exactly the same on both.
The next article in this series opens the second cabinet of curiosities: Unicode – strings that count a seven-codepoint emoji as one character, a variable named $Δ, and a file called café-☕.txt.
How a from-scratch Raku compiler in C++ went from an empty directory to ~82% of the official test suite — plus a native code generator, a self-hosting toolchain, and a browser playground — in under three weeks.
This is the long version of the story. The short version lives in the announcement; the disciplined version lives in docs/dev/JOURNEY.md, which records the method rather than the narrative. This document is the narrative: what happened, in what order, what each round cost and returned, and why the numbers moved the way they did.
I have been following Raku since it was Perl 6, and more than once over the years I tried to write a compiler for it. Every attempt stalled the same way. Raku is a large language — you start with say "Hello" and within an evening you are staring at grammars, junctions, multi-dispatch and the number tower, and you quietly close the editor. The conclusion was always the same: this is too much for one person.
What changed is not the language. It is that today we have a new kind of helper. The whole of Raku++ was written without me typing a single line of its C++. I described what I wanted, I ran the tests, I pointed at what was broken, and the code appeared. The role a human plays in this is different from the old one — you are a director and a reviewer, not a typist — but it is a real role, and the project is the argument that it works.
The goal, from the first day, was simple and concrete: a Raku compiler that is fast and useful — one that starts instantly and that you would actually reach for. Not a research prototype, not a proof of concept. Something you run. Work began roughly a week before the repository’s first commit, which landed on 2 July 2026; the earliest commits are already a working tree-walking interpreter rather than a first sketch.
There is a working rule underneath the whole project — Rakudo is the reference, not the source — but it is worth being precise about how it came to be. It was not a principle we declared on day one. It was simply what happened: we never needed to open Rakudo’s code, so we didn’t. Only later did we understand why that was the right way to work, and articulate it as a rule. We treat Rakudo as the north star for behaviour — the answer to “is this really Raku?” — but we never ported a structure or copied an algorithm from it. Raku++ is clean-room: a hand-written lexer, a recursive-descent parser with a Pratt expression core, and a tree-walking evaluator, all grown from nothing.
That independence is only possible because Raku has an executable specification. The motto we kept returning to —
Any compiler that can run Roast can be called a Raku compiler.
— means “correct” was never “what Rakudo’s source does.” It was two things we could look at without ever reading Rakudo: Roast, the official test suite (~1,464 .t files of runnable spec), and docs.raku.org, the prose. Between them they are the language, described independently of any one runtime.
The earliest work was the core MVP: enough of S02–S04 plus the Test module to make Roast files run at all. A Roast file that emits 1..40 but scores 12/40 is a shopping list — it tells you exactly which twenty-eight things Raku expects next. A file that produces no output at all is usually one parse error away from unlocking a whole cluster.
By 5 July the thing was coherent enough to tag v0.1.0, and it fully passed 252 of 1,464 Roast files. “Fully passes” is the strict bar: every single assertion in the file must be green, or the file does not count. That number — a few hundred whole files — was the baseline everything else is measured against.
Then the loop began in earnest, and it never really stopped:
HyperWhatever, dispatch and list correctness: 252 → 255.is native C FFI through dlsym, no libffi) and book-gap fixes pushed to 300 (131,320 / 189,081).Around here we forced ourselves to be honest about what “coverage” means, and it is worth dwelling on, because it is easy to get wrong.
There are two entirely different questions hiding behind “how much of Raku does it do,” and conflating them flatters you.
File coverage — how many whole Roast files pass every assertion — is the harsh one. One stray failure in a 200-assertion file zeroes the whole file. This number sat around 17% early on and is ~30% now (440 of 1,464 files). It is a coverage figure: how much of the suite is completely conquered.
Per-test rate — of every individual test the suite declares, how many pass — is the fair one for “correctness on what runs.” This is the headline: ~82%, or roughly 159,000 of ~194,000 declared tests.
The subtlety we documented in docs/COUNTING.md is that the denominator is not fixed. “Declared” means every test any file tries to run, including files that abort before emitting a single result — we recover their planned count from the source and count all of it as failing. The better the compiler gets, the more files run far enough to declare more tests, so the denominator grows with coverage. Our passing count reads as ~82% against our own recovered denominator, but only ~77% against the suite’s full declared total. We chose to headline the number that is, if anything, slightly unflattering. In the docs the rule is fixed: report raw numbers, quote both figures, never boast.
The per-test rate itself climbed in visible steps. On 9 July the honest all-declared figure was about 57%. Unicode collation (below) moved it to ~80.6%. sprintf corner cases took it to 80.8%. The course and challenge rounds carried it to ~82%.
The rounds above skip over the machinery each one demanded. A few pieces were disproportionately hard and disproportionately important.
The number tower. Raku promises that 0.1 + 0.2 == 0.3 is True, because its decimals are exact rationals, not floats. That means a hand-rolled arbitrary-precision BigInt (base 1e9, with a long long fast path) and an exact Rat sitting underneath every arithmetic operation. A Rat whose denominator overflows 64 bits degrades to Num the way Raku specifies — a subtlety that only surfaced when a Mandelbrot render started producing slightly wrong pixels.
Unicode, done properly. This became the single strongest area of the whole project. Grapheme-correct strings (UAX #29), the four normalization forms (NFC/NFD/NFKC/NFKD), character names and properties — all generated from the Unicode Character Database, upgraded to UCD 17.0. Then UCA collation from DUCET 17.0: all 8,271 collation conformance tests pass. .chars counting graphemes rather than codepoints is the kind of thing that is invisible until it is wrong, and Raku is one of the few languages that insists on getting it right.
The regex engine. Not a wrapper around a library — a from-scratch recursive-descent regex parser feeding a continuation-passing backtracking matcher, in src/Regex.{h,cpp}. Grammars are built on top of it. Later it had to grow runtime interpolation — lexical :my variables set mid-match and used later as pattern atoms, code assertions evaluated against the live match — to parse real-world YAML.
From interpreter to compiler. The project was always “interpret today, grow a backend later,” and the backend arrived. The key insight is a restraint: Raku++ deliberately does not implement the grammar-mutating parts of Raku — no custom slangs, no parse-time operator definitions. That restraint has a payoff — if the parse tree cannot change at runtime, it can be turned into C++ at build time. So rakupp grew four ways to run a program:
rakupp program.raku # interpret (default)
rakupp --bundle program.raku -o program # embed source + interpreter
rakupp --aot program.raku -o program # parse ahead, embed the AST
rakupp --exe program.raku -o program # transpile to C++, compile native
Getting --exe to real readiness was a refactor as much as a feature: moving compiled subs off fixed C++ parameters onto a uniform ValueList calling convention, so named parameters, optionals, defaults, slurpies, and multi dispatch all compile natively. The compiler is validated not against Roast but by parity: compile a program, run it, run the same program under the interpreter, assert identical output. The interpreter is the oracle for the compiler. An -O flag forwards optimization down to the generated binary.
Self-hosting. A milestone that felt better than its size warranted: the harness that runs Roast, tools/run-roast.raku, is itself written in Raku and executed by rakupp. The tool that measures the compiler runs on the compiler.
By mid-July, Roast was giving diminishing returns per hour — not because the compiler was done, but because Roast tests the language in the small. It isolates features. Real programs exercise a dozen modules resolving each other, a database driver, industrial-volume string munging — things a spec suite simply does not reach. So we opened a second front: run real Raku software and fix whatever breaks.
covid.observer — a substantial Raku web-stats generator — was the first. Getting it to compile forced heredocs, quote-aware regex lexing, literal multi parameters, hash-vs-block disambiguation. Getting it to run against a live MySQL database (through a small pure-Raku shim that shells out to the mysql client) forced real module loading, use lib, feed operators, hyper method calls, and enough of the object model to hold a dozen CovidObserver::* modules at once. It now runs end-to-end and writes real HTML.
The Complete Course of the Raku Programming Language — the book-length course, ~1,500 pages — was the second, and it went much deeper. Its site generator is written in Raku, and its table of contents is read through YAMLish, an indentation-sensitive YAML grammar that exercises nearly every advanced regex feature at once. Making that grammar parse is what drove the runtime-interpolating matcher mentioned above.
The lesson of this front is that a feature can be “done” by Roast’s lights and still be quietly wrong in a way only a real program reveals. Numeric context on an array, nested hash access, variable pair-keys — all “passing” in Roast while producing wrong output in real code.
Then a sharper idea. The course does not just have a generator — it is made of Raku. Every one of its pages is full of fenced code blocks, each a small, complete, idiomatic Raku program that a human wrote to teach something. That is a test corpus of a kind Roast is not: idiomatic rather than minimal.
So we extracted every fenced block from the English pages plus the exercise files and ran each one under both engines — rakupp and Rakudo — with stdin closed and a timeout, and diffed the output. 3,068 comparisons. Blocks that don’t run under Rakudo (theory fragments, output samples) were discarded; so were nondeterministic ones. What remained were 148 real divergences where rakupp and Rakudo genuinely disagreed.
We fixed them in two rounds — containers and binding, list/Seq typing, associative gists, junction gists, numeric coercions, quoting adverbs, regex and grammar corners — and drove the number of genuine divergences from 148 down to 14. The full ledger is in docs/dev/COURSE-DIVERGENCES.md. Every one of those was a bug that neither Roast nor the two big projects had caught, because nobody had written that idiom before in a form we tested.
If the course is a corpus, The Weekly Challenge (PWC/TWC) is a firehose. Years of participants’ solutions — thousands of small, real, wildly varied Raku programs, written by many hands with many styles. We ran 10,428 solutions through the same both-engines-and-diff sweep.
Only about 6,800 of those are actually comparable — the rest are skipped because Rakudo itself cannot run them headlessly (missing arguments, modules, or input), times out, or is nondeterministic. Of the comparable set, the first pass found 2,663 — 39% — producing byte-identical output to Rakudo. Then fifteen fix batches, each targeting a cluster the diff exposed:
Any single-item semantics.ff flip-flop, post-GLR map.tr/// returning a StrDistance.min/max flattening, is rw loop parameters, rotor pairs.@w»[0], »++), string-as-one-item indexing.sub USAGE, CLI allomorphs, and $*USAGE byte-identical to Rakudo’s generated usage text.(“Post-GLR” refers to the Great List Refactor, the 2015 redesign of how Raku lists, arrays, and sequences flatten and containerize. Its most visible rule is that map and friends keep each block’s result as a single element — only an explicit Slip splices into the surrounding list — and that bare comma-lists are immutable Lists while @-sigil variables are mutable Arrays. Matching those semantics exactly was a recurring theme across the list-typing fixes here and in the course round.)
The identical count climbed to 4,056 — 60% of the comparable programs — and is still moving. Every batch passes a zero-regression Roast gate before it counts, so the two fronts reinforce each other: the Roast standing rose from 433 to 440 fully passing files across these same batches. Each batch is a progression row in docs/dev/PWC-DIVERGENCES.md.
What the ledger surfaced late is a leverage insight worth keeping: the remaining mismatches are not evenly spread. Six prolific authors account for about half of them, because each reuses one personal template across hundreds of solutions — so fixing one recurring shape corpus-wide clears files by the hundred, not one at a time. That is the shape of the work now.
The pattern across all three fronts — Roast, real projects, and the two corpora — is that each has a blind spot the others cover. Roast misses what isn’t in the passing set. Real projects miss what they happen not to use. The corpora find the idioms nobody isolated. Running all of them, and trusting whichever is currently pointing at a problem, is what kept the work honest.
The goal is 100% of Roast. It is the right goal because Roast is the definition — passing all of it is exactly what it means to be a complete Raku. And it is hard for reasons that are structural, not incidental:
--exe possible by their absence, and re-introducing them without giving up ahead-of-time compilation is a genuine design problem, not a day’s work.Where the frontier sits today is grammars in the large: turning a parsed YAML match tree into data through action methods and a second schema grammar — a fresh set of small gaps, peeled one at a time, which is how everything else here got built.
Somewhere in the middle of all this, the compiler stopped being a thing we tested and became a thing we used.
I have been proofreading the course — a separate story — which means running its generator again and again, hundreds of times. The generator is Raku. So it runs on rakupp, in production, regenerating the real site. And this is where the performance work stopped being an abstraction. Rakudo starts in roughly 150 ms; rakupp starts in about 12. On a single run that is nothing. On the two-hundredth run of an edit-regenerate-look loop, it is the difference between a tool that interrupts your thinking and one that doesn’t.
One piece of that pipeline deserves its own mention. The course renders its code blocks with Pygments, a Python highlighter that, like almost all highlighters, works by lexing — it matches words against patterns. That is fine until a class has a method called role, at which point Pygments paints role as a keyword, because lexically it cannot tell a method name from a language keyword. But rakupp parses, so it knows the difference structurally. rakupp --highlight emits the exact same CSS classes Pygments does — the course’s stylesheet works unchanged — but assigns them correctly, and does it in ~13 ms where the Python tool took ~110. It is a drop-in replacement that is simply more right, and it removes a Python dependency from a project whose whole premise is depending on no one else’s implementation.
The idea arrived the way the good ones do — obvious in hindsight. The course teaches Raku. It is full of runnable examples. What if the reader could run them, right there on the page, with no server and no round-trip?
The interpreter is portable C++ with no dependencies. That is exactly the shape of thing that compiles to WebAssembly. So rakujs/ builds the same src/ interpreter — not a reimplementation, the identical C++ — with Emscripten, into a .wasm module that runs Raku entirely in the browser. Semantics are identical to native rakupp and therefore to what Roast validates, because it is rakupp. Nothing in src/ was modified; the WASM build is purely additive — a thin entry point exporting rakupp_run(src), a build script, and a self-contained editor.
It has its own constraints. Emscripten’s -fwasm-exceptions is still uneven across browsers, so the build ships classic -fexceptions; the interpreter leans on C++ exceptions for control flow (every return, next, last), so this matters. The browser stack is shallower than a native one, so deep recursion is capped around a couple hundred frames. The WASM runs in a Web Worker so the UI stays responsive — a live spinner, streaming output, a working Stop button — and the whole thing is built at -Oz for size.
The result is the playground, live at course.raku.org/playground: an editor with the example programs, syntax highlighting, a theme switcher shared with the course, and Raku running in the tab. A from-scratch Raku, written in C++ in under three weeks, executing in a browser with no server behind it.
Among the two dozen programs in examples/ is mandel.raku — the Mandelbrot set rendered in ASCII, the same demo that shipped with Parrot two decades ago. Back then a fractal crawling down the terminal was the thing you showed people to prove a new language was real.
I put it back in, and the first run was slow — noticeably slower than Rakudo. That was useful: it pointed straight at a real engine problem. Every arithmetic operation on an exact Rat was re-reducing the fraction (a GCD normalization) even when nothing needed it, so a program doing millions of Rat operations paid for it millions of times. Removing the redundant re-reduction — and letting a Rat whose denominator grows past 64 bits degrade to Num the way Raku specifies — turned the render fast, and sped up everything else that leans on rationals at the same time. Same maths, same fractal, now in a blink. That — more than any percentage in any table — is what made this project worth doing. It brings back the taste of a fast computer that answers you the instant you press Enter, the way computers felt when they were small and programs were instant and start-up time was a concept you never had to think about.
None of this came from a wishlist. It came from a loop that has not changed since the first week:
Find the failing thing — in Roast, in a real program, in the docs, in a corpus. Understand what Raku actually means, from the spec and the prose, never from Rakudo’s insides. Make the smallest change that is right, not merely one that turns a test green. Run the whole suite and diff the set. Keep the fixes that are correct even when the count dips. Write down what was non-obvious.
Run that loop patiently enough, with a helper that never tires of it, and you find out how far a clean, dependency-free C++ implementation of Raku can get on its own.
The answer, so far, is: further than I would have believed three weeks ago.
Sources, releases, and full documentation: github.com/ash/rakupp.
I have been following the development of the Raku programming language since the very beginning. It was Perl 6 for many years, and I had a dream to start using it in real projects. Honestly, I could, to some extent.
The timeline for the last 20+ years was not linear at all, and had its own unexpected changes. After a hope with a quick Parrot, there was an unbelievably powerful Pugs and a few other projects. It was Rakudo that carried the language forward and became its leading implementation. It’s a massive project with great Raku coverage.
I always wanted to create a Raku compiler myself. Over the years, I made a few half-serious attempts, but as the language is indeed huge, I soon understood it was not feasible. After the rename, around 2020, I thought we could approach some Big Tech companies to ask them to make an industrial compiler for us. Actually, I discovered recently, that I even talked to ActiveState at some point much earlier, when it was still Perl 6.
The reality is if you want to have a compiler, the only option is to make it yourself. OK, today, we have great friends and helpers, AI.
And here, let me present my brand new Raku compiler, Raku++.
It is now available for macOS, Linux, and Windows as binaries of the release 0.5.1, and of course you can compile it from source. The code is written in C++.
The compiler in its current state covers about 82% of the Roast test suite, which is the official test suite for Raku as a programming language. Inside the repository, there are some tools, which are written in Raku and can be executed by Raku++ itself. I also applied the compiler to my fully Raku-based projects, Covid.observer and The Complete Course of the Raku Programming Language. Both of them have generator tools, written in Raku. And as I am working on proofreading the Course at the moment (that’s the topic of a separate announcement), I’ve been running the generator tools again and again. The fact that Raku++ is so fast helps a lot.
I would not copy-n-paste the documentation here, but I’d like to highlight a few most important things about Raku++.
-O optimising option for the compiler.rakupp (that’s the name of the executable file of Raku++), you feel the spirit of real programming and working with a fast and responsive computer, as it should be. You press Enter and get the result immediately.Explore the documentation in the repository, it’s an enjoyable read.
On a separate nostalgic note, I revived the mandel.p6 program, the one that was shipped with Parrot and printed the Mandelbrot fractal in the console. Here it is again on new ground:
................::::::::::::::::::::::::::::::::::::::::::::...............
...........::::::::::::::::::::::::::::::::::::::::::::::::::::::..........
........::::::::::::::::::::::::::::::::::,,,,,,,:::::::::::::::::::.......
.....:::::::::::::::::::::::::::::,,,,,,,,,,,,,,,,,,,,,,:::::::::::::::....
...::::::::::::::::::::::::::,,,,,,,,,,,,;;;!:H!!;;;,,,,,,,,:::::::::::::..
:::::::::::::::::::::::::,,,,,,,,,,,,,;;;;!!/>&*|& !;;;,,,,,,,:::::::::::::
::::::::::::::::::::::,,,,,,,,,,,,,;;;;;!!//)|.*#|>/!;;;;;,,,,,,:::::::::::
::::::::::::::::::,,,,,,,,,,,,;;;;;;!!!!//>|: !:|//!!;;;;;,,,,,:::::::::
:::::::::::::::,,,,,,,,,,;;;;;;;!!/>>I>>)||I# H&))>////*!;;,,,,::::::::
::::::::::,,,,,,,,,,;;;;;;;;;!!!!/>H: #| IH&*I#/;;,,,,:::::::
::::::,,,,,,,,,;;;;;!!!!!!!!!!//>|.H: #I>!!;;,,,,::::::
:::,,,,,,,,,;;;;!/||>///>>///>>)|H %|&/;;,,,,,:::::
:,,,,,,,,;;;;;!!//)& :;I*,H#&||&/ *)/!;;,,,,,::::
,,,,,,;;;;;!!!//>)IH:, ## #&!!;;,,,,,::::
,;;;;!!!!!///>)H%.** * )/!;;;,,,,,::::
&)/!!;;;,,,,,::::
,;;;;!!!!!///>)H%.** * )/!;;;,,,,,::::
,,,,,,;;;;;!!!//>)IH:, ## #&!!;;,,,,,::::
:,,,,,,,,;;;;;!!//)& :;I*,H#&||&/ *)/!;;,,,,,::::
:::,,,,,,,,,;;;;!/||>///>>///>>)|H %|&/;;,,,,,:::::
::::::,,,,,,,,,;;;;;!!!!!!!!!!//>|.H: #I>!!;;,,,,::::::
::::::::::,,,,,,,,,,;;;;;;;;;!!!!/>H: #| IH&*I#/;;,,,,:::::::
:::::::::::::::,,,,,,,,,,;;;;;;;!!/>>I>>)||I# H&))>////*!;;,,,,::::::::
::::::::::::::::::,,,,,,,,,,,,;;;;;;!!!!//>|: !:|//!!;;;;;,,,,,:::::::::
::::::::::::::::::::::,,,,,,,,,,,,,;;;;;!!//)|.*#|>/!;;;;;,,,,,,:::::::::::
:::::::::::::::::::::::::,,,,,,,,,,,,,;;;;!!/>&*|& !;;;,,,,,,,:::::::::::::
...::::::::::::::::::::::::::,,,,,,,,,,,,;;;!:H!!;;;,,,,,,,,:::::::::::::..
.....:::::::::::::::::::::::::::::,,,,,,,,,,,,,,,,,,,,,,:::::::::::::::....
........::::::::::::::::::::::::::::::::::,,,,,,,:::::::::::::::::::.......
...........::::::::::::::::::::::::::::::::::::::::::::::::::::::..........
So, enjoy Raku++: https://github.com/ash/rakupp
(from an original draft by Richard Hainsworth)
Establishing the Raku Foundation as a legal entity is just the first step in creating an organization dedicated to supporting the Raku Programming Language, that fits into the free-wheeling world of open source software development.
This article is about some of the challenges being faced by the group of volunteers attempting to do this.
We live in a world that is very suspicious about the motivations of others, requiring transparency about all decisions. But this world is also populated by people who want the maximum freedom for themselves.
At the same time, the new European Union's law on Cyber Resilience looks as if it will create a new space for Free and Open Source developers by establishing a new sort of agency called an Open Source Steward.
The Raku Foundation is being set up - in part - to take advantage of this new law, and to provide Raku developers the legal space in which they can contribute to FOSS projects that could be used by corporate entities in their commercial offerings. But this also means that The Raku Foundation must have its legal status defined and its corporate governance structures need to be clear and understood.
The Raku Foundation was established in the Netherlands, and so it has to be compliant with the laws of the Netherlands. In practice, this means that The Raku Foundation must have an Executive Board from the very start.
Dutch foundations may also have a Supervisory Board which can appoint and remove members of the Executive Board. In order to maximize transparency and the involvement of the Raku Community, such a Supervisory Board will be created with an election by the registered members of the Raku Community.
The way in which members will be registered, the elections conducted and the term Supervisory Board members will serve, will be set out in the Regulations. These Regulations are currently being finalised and will be made public as soon as possible.
In summary the Executive Board will be the main operational decision-maker, but the members of the Executive Board will be responsible to the Supervisory Board, which will be elected by the members of the Raku community.
The Raku Foundation already has some specialised needs, such as the development and maintenance of the Raku Programming Language web sites, the continuing development of the Raku Programming Language, and managing the marketing process.
Since the time that what is now the Raku Programming Language began to be developed, progress came about as enthusiastic volunteers worked on the projects they found interesting. This self-organising way of doing things needs to be preserved.
In general decisions are reached by consensus, usually by developers implementing things in a concrete way, and then others offering opinions and tweaks. The least amount of formality is better.
But there have also been times when the Raku Community has needed an official voice or group that can speak on behalf of the whole community. Since such a group is speaking and acting for the whole community, such a group needs to be bound by formal rules.
So The Raku Foundation needs both informal self-organising groups, and formal rule-based groups. The Executive Board has decided to call these two types of groups Committees and Working Groups.
A Committee, such as the Community Affairs Team, will be:
Note that even though Committee members will be appointed by the Executive Board, the decision on which Raku Community members will be appointed, may well be following an advise by the Supervisory Board, or even an election of some sort.
A Working Group will
To be able to do this work, The Raku Foundation needs donations. Please consider giving a donation!
When a number of highly motivated individuals work together with little organizational structure, some conflicts will undoubtably form. In addition, some decisions may have profound financial or long-term effects and reasonable people will disagree about the right way to proceed.
In such cases, it will be for the Executive Board to resolve the conflicts, and/or to choose one of the possible courses of action.
Over the years, a number of de-facto working groups have formed. Some of them are more actve than others, and the amount of activity varies depending on the availability of the volunteers.
It is the Executive Board's intent to let all of these existing structures continue to exist as is. An overview of these structures:
The people taking care of the documentation of the Raku Programming Language, specifically the documentation repository and the documentation website.
The people taking care of keeping a lot of the Raku online services alive and kicking (such as https://raku.org).
The Marketing Working Group has been largely dormant for the past 5 years or so. Fortunately some people have come forward to revive this working group to provide new marketing materials.
Since the Raku Steering Council in its current form was originally created after an election, it feels like the Raku Steering Council should be considered a Committee rather than a Working Group in the future.
The Community Affairs Team was originally created by the Raku Steering Council. It feels like this should also become a Committee rather than a Working Group in the future.
Some new structures will need to be created.
The Raku Programming Language will need to set up its own
CVE Numbering Authority for all of the core components of the currently only full implementation of the Raku Programming Language (MoarVM / NQP / Rakudo).
Since this involves trust, both from within the Raku Community, but also from the general Open Source security community, this will most likely need be a Committee.
More people will need to become up-to-date on the developments with regards to the Cyber Resilience Act and its effects on the Raku Programming Language.
There's plenty of work to be done!
If you consider yourself part of the Raku Community, or would like to be involved now or in the future, please register your interest so that we will be able to contact you in the (near) future!
Anyone with an active interest in the success of Raku is welcome to Register their interest in membership of The Raku Foundation community – details of participation are being thrashed out by the newly appointed Executive Board and will be communicated in due course. [If you are reading the weekly, then this means you. -Ed.]
Foundations can only exist by your support!
Some do this by their work on the development of the Raku Programming Language or the development of the Raku Ecosystem, or by using the Raku Programming Language for their projects. Another way to support the Raku Programming Language is to support the Raku Foundation financially: keeping the Raku infrastructure up and running also requires financial resources! Click here to donate.
Damian Conway proclaims:- TRF Lives! – a thoughtful piece (geddit?) by one of the progenitors of Raku that strikes a good balance with the perl heritage and the path forward.
Last month saw the official announcement of The Raku Foundation, including an invitation to every member of the global Raku community to register their interest in the organization and become members, with the right to vote on its leadership, policies, and activities. Once again, I would encourage everyone who loves Raku to do exactly that…
Tim Nelson says OK, Qwiratry 0.0.4 is out  https://raku.land/zef:wayland/Qwiratry
https://raku.land/zef:wayland/Qwiratry
A Raku architecture for declarative queries and flexible data walking, suitable for trees, tables, relational structures, logic-programming environments, and anything reasonably structured and traversable.
Greg Donald on Shipping My First Raku App Page
I just released behave.dev into production. It’s the homepage for BDD::Behave, my behavior-driven testing framework for Raku. It’s the first Raku application I’ve ever pushed to production. I’ve been deploying web apps since 1996, so the moving parts of putting a process behind a reverse proxy on a Linux box are familiar territory. What I had to figure out this time was where the Raku-shaped pieces slot into that picture, and which of my usual configuration patterns transfered cleanly.
Weekly Challenge #381 is available for your critique.
Thanks to all those connected to the Raku project for registering your interest at https://raku.foundation – if you haven’t done that yet, please do and make your voice heard. Even nicer would be a small donation.
Please keep staying safe and healthy, and keep up the good work! Even after week 76 of hopefully only 209.
~librasteve
Anyone with an active interest in the success of Raku is welcome to Register their interest in membership of The Raku Foundation community – details of participation are being thrashed out by the newly appointed Executive Board and will be communicated in due course.
On behalf of the Rakudo development team, I’m happy to announce the June 2026 release of Rakudo #194. Rakudo is an implementation of the Raku language.
Editor’s note: Last time I thought 52 RakuAST items was a lot – this time there are 83!!! Rather than list them all here, I provide a screengrab in fine print – go to https://rakudo.org/post/announce-rakudo-release-2026.06 for a proper review. RakuAST work is on fire!

The following people contributed to this release:
Nick Logan, Elizabeth Mattijsen, Will Coleda, Timo Paulssen, Daniel Green, Patrick Böker, comborico1611, raiph, rir
I resumed the Slangify posts with one showing the Restaurant Booking LLM workflow.
Ralph Muschall shared their Gotoh (advanced string comparison) algorithm implemented in Raku. This is a string comparison algorithm that counts matches/mismatches as well as deletions/insertions (with affine penalty), all four weights are real numbers (the first one is usually positive, the others are negative).
Weekly Challenge #380 is available for your progression.
This week, the IRC #raku-beginner channel picked up an excellent question. In trying to answer it, I took a deep dive into routine list and learned a lot. Thanks to Time Melon for their curiousity.
The challenge was:
Why does list(Seq(1,2,3)) NOT return a List?
(In fact, it returns a Seq).
TLDR; routine list does its best to give you a listy thing since that is what you have requested, usually that’s something of type List, but here Seq is considered listy enough to suffice.
The docs explain best:
Although the Seq class does provide some positional subscripting, it does not provide the full interface of Positional, so an @-sigiled variable may not be bound to a Seq, and trying to do so will yield an error. This is because the Seq does not keep values around after you have used them. This is useful behavior if you have a very long sequence, as you may want to throw values away after using them, so that your program does not fill up memory.
It is possible to hide a Seq inside a List, which will still be lazy, but will remember old values. This is done by calling the .list method. Since this List fully supports Positional, you may bind it directly to an @-sigiled variable.
And the docs example captures it neatly:
my @s := (loop { 42.say }).list;
repl;
@s[2]; # says 42 three times
@s[1]; # does not say anything
@s[4]; # says 42 two more times
Yeah – takes some getting the head round it. But worth the effort to fully appreciate the power of List and Seq types.
[I have inserted the repl line here since that gave me a better feel for what was going on. If you go say @s[2] again then you get True since that is the value returned by the loop {}]
The docs have a few things to say about Lists in general and routine list if you would like to read further:
And note that list() (the subroutine form) and .list (the method form) are not to be confused with .List which is a coercion method that tries to convert your item to a List type (as are all Title Case built-in methods).
Your contribution is welcome, please make a gist and share via the #raku channel on IRC or Discord.
OMG – the RakuAST commits are on fire. I note that the RakuAST testing is now moving out to “Blin” which is a test jig that applies new Rakudo builds to a set of Raku modules – so testing against eco-system code.
A double crop of new and updated Raku modules this week since we had to skip last week.
The European heatwave this week had temperatures are high as 37ºC. [I am not going to translate this into ºF so that the Americans don’t mock us.]
Keep up the great work! And Keepeth thy cooleth. Even after week 74 of hopefully only 209.
~librasteve
Image: Het Torentje van Drienerlo (the ‘Little Tower of Drienerlo’) a 1979 artwork by Dutch artist Wim T. Schippers. This file is licensed under the Creative Commons Attribution 2.0 Netherlands license.
TPRC is happening very soon! If you haven’t registered, it’s not too late! We’d still love to see you in Greenville SC [USA] June 25-29; check out https://tprc.us/ for all the info. If you ARE coming, we can’t wait to see you! Join us for an arrival dinner on Thursday evening, June 25. We will meet in the lobby at 5:15 and walk to Chuy’s just across the parking lot.
We need Lightning Talks! We hope you are planning to join the fun. Go ahead and submit your lightning talk on the website. We will also accept lightning talk submissions after the conference begins, so go ahead and make your plan! We need volunteers! If you can help with set-up or registration desk, or any other tasks, please check in with us in the Palmetto room any time beginning Thursday, and we will be grateful to put your hands and mind to work!
And, for those of you who can’t come, we will miss you! Watch for our videos on our YouTube channel at https://youtube.com/@YAPCNA/videos/ once the conference is over.
Anyone with an active interest in the success of Raku is welcome to Register their interest in membership of The Raku Foundation community – details of participation are being thrashed out by the newly appointed Executive Board and will be communicated in due course. [If you are reading the weekly, then this means you. -Ed.]
Rocky Linux has adopted Raku Sparky This guide explains how to install, configure, and run Sparky, so you can run the Rocky Linux Testing Team’s automated use-case tests against Rocky Linux. Checkout the Rocky docs for details…
Why Sparky and Sparrow for Rocky Linux testing?
The goal for testing is to have more test coverage of common use cases that the Rocky Testing Team can verify on new Rocky Linux releases (both major and point releases). Additionally, there are two other goals:
The Venn diagram overlap of OpenQA, Kickstart tests, and Sparky is fairly minimal. While the Testing Team had hopes to integrate most of the documentation into OpenQA or the Kickstart tests, the process was becoming complicated. Sparky provides an automation framework tool that is much easier for the Rocky Linux Community to contribute to.
Ralf Muschall has written some code to Decompose an integer into prime factors using Lenstra’s algorithm on Edwards curves
Weekly Challenge #379 is available for your appraisal.
In the last weeks TnT, we have looked at the . (dot) and ! (exclamation) twigils. Here’s a reminder using the . to make a class attribute $.name with read-write access:
class Person {
has $.name is rw;
}
my $p = Person.new;
$p.name = 'Alice';
say $p.name; # Alice
Then we showed how you can roll your own set /get accessors with multi s to get encapsulation with nearly that behaviour:
class Person {
has $!name;
multi method name { $!name }
multi method name($x) { $!name = $x }
}
my $p = Person.new;
$p.name: 'Alice';
say $p.name; # Alice
But note we had to alter $p.name= to $p.name: (the = assignment became : method call syntax with an argument) – what if you want exactly that assignment behaviour and you want encapsulation with custom accessors. If you really want to contort Raku OO like that, then use the underlying Proxy class to add FETCH/STORE:
class Person {
has $!name;
method name() is rw {
Proxy.new(
FETCH => { $!name },
STORE => -> $, $val { $!name = $val },
)
}
}
my $p = Person.new;
$p.name = 'Alice';
say $p.name; # Alice
As with everything in Raku, you can always dig deeper and find a way!
Your contribution is welcome, please make a gist and share via the #raku channel on IRC or Discord.
Thanks to all those connected to the Raku project for registering your interest at https://raku.foundation – if you haven’t done that yet, please do and make your voice heard.
Please keep staying safe and healthy, and keep up the good work! Even after week 73 of hopefully only 209.
~librasteve
Today, Elizabeth Mattijsen announced the formation of The Raku Foundation in a blog post A Year Later: a TRF!
It is going to take a little time for the Executive Board to put in place the registration of Raku community members and procedures consistent with the legal requirements in the Netherlands so that members will be able to democratically participate in the decision-making.
Raku contributors (of all kinds) will shortly be invited to join the membership. You are most welcome and kindly encouraged to register your interest at https://raku.foundation.
Since the formation of The Raku Foundation is such a big step forward for the community, I would like to take the opportunity to reproduce here some of lizmat’s words first published a year ago that outline the need for this and started the process:
The Raku Programming Language was originally started as the next version of the Perl Programming Language (then at version 5.6.0, now at 5.40.2). Unfortunately the implementation of this next version took much longer than expected. In the eyes of many Perl users the new version also changed the character of the language, which caused a rift in the Perl community.
When in late 2015 the initial release of what was then called “Perl6” came out, the rift only deepened: not wanting to relinquish the “Perl6” nomer was felt by many in the Perl community as name squatting. In late 2019 the name squatting issue was resolved by changing the name of “Perl6” to the “Raku Programming Language”.
Open source projects that exist beyond the scope of their original developer need to have a way to be represented, and usually also a way to finance vital project infrastructure: technical infrastructure (such as providing websites and testing services), as well as organisational infrastructure (such as regular user events, Code of Conduct -both online and at events-, and project course decisions) and developmental support (such as grants).
Because of Raku’s historical roots, this has been taken care of (or was sponsored by) Yet Another Society (or YAS, to most better known as “TPF” or “The Perl Foundation”). After the name change of the language, YAS acquired a new alias: “The Perl and Raku Foundation” (or short: TPRF). But it has always felt like a remnant of historical connection that Raku had with Perl, rather than something that was a natural result of the developing situation.
Keeping an Open Source foundation running requires volunteers willing to spend a sizeable amount of their free time on foundation matters. And it requires a source of funds to keep the foundation in working order.
Historically YAS has received funding from many sources. Initially to support just Perl, later this was separated into support for Perl 5 and what was to be Perl 6. Over the years it has become more difficult for YAS to obtain funding. And has not received much funding for what is now Raku: there are probably many reasons for that, one of them being that Raku as a separate target for funding is not very visible on the foundation’s website.
Now, more than five years after the name change, it feels like a good time for the Raku community to be standing on its own feet, without support by YAS. After several weeks of discussing this with several people involved in YAS and the Raku Community, I hereby announce the intent to set up a completely separate Raku Foundation, based in Europe, but global in reach.
This would allow YAS to be fully focussing on the one programming language that instigated the creation of the foundation: Perl. And it would allow the Raku Community to be served by a foundation that is solely dedicated to the Raku Programming Language.
See the original post for more.
Weekly Challenge #378 is available for your scrutiny.
Last week we looked at the . (dot) and ! (exclamation) twigils and their use in Raku class attribute has declarations.
Something easily overlooked is the similarity between self. and $. method call syntax. In fact $. is just another way of writing self. .
Consider this example, self. is used as the invocant to call the accessor for $.name and to call the meta-method .^name (the caret denotes that we are asking something about the class, in this case, the class name):
class Person {
has $.name;
method type-check {
"{self.name} is {self.^name}"
}
}
class Celebrity is Person {
method name { callsame.uc }
}
my $a = Celebrity.new(name => 'Larry');
say $a.name; # LARRY
say $a.type-check; # LARRY is Celebrity
In the example callsame.uc is saying “if you are a Celebrity, then apply the upper case .uc method to .name“. Since we are using self, and Celebrity inherits from Person then the child object method is called first and callsame then dispatches to the parent method. A typical method override.
In Raku we can rewrite the same code, using the $. syntax like this:
class Person {
has $.name;
method type-check { "$.name is $.^name" }
}
class Celebrity is Person {
method name { callsame.uc }
}
my $a = Celebrity.new(name => 'Larry');
say $a.name; # LARRY
say $a.type-check; # LARRY is Celebrity
Note:
$.name variant is more natural to access the attributeself.name – the inheritance and dispatcher logic plays nicely$. is a good syntax for non-attributed method calls too$. (and $!) play nice with string interpolation too, no extra curly {} linenoise needed Your contribution is welcome, please make a gist and share via the #raku channel on IRC or Discord.
Massive achievement by Liz and the newly appointed Executive Board. I enjoyed helping out with the new site and (since I am the author of the Air module) it nice to hear that Air and the HARC Stack framework is living up to the design goal:
And the most fun part: the whole website (from my point of view) is all just Raku code!
Please keep staying safe and healthy, and keep up the good work! Even after week 72 of hopefully only 209.
~librasteve
Almost a year later to the day that I posted Towards a Raku Foundation I'm glad to announce there is now The Raku Foundation in its bootstrapping phase: https://raku.foundation.
The problem solving issue has been closed, and now the real work can begin.
I hope that this blog post shows the process that we've been through in starting the Raku Foundation. And that lessons can be learned from it for other Open Source communities wanting to follow a similar path.
Many discussions were had about the Articles Of Association, and it took a long time to get to an agreement. And then finally when there was an agreement, it was time to find a notary willing to notarize the Articles of Association.
The first hurdle was that the Articles Of Association were wrought in English. Dutch law doesn't allow any official papers to be in any other language than Dutch. So a translation would have to be made. Fortunately, yours truly is pretty versed in both languages, and Google Translate can help a lot with the initial work on a proper translation.
The second hurdle was finding board members. I wanted to make sure that the initial Executive Board members would have a (long) experience with the Raku Programming Language, and where geographically / culturally and age as diverse as possible. Apart from yours truly obviously, I was very glad to be able to find Patrick Böker (Germany, patrickb), Bruce Gray (USA, Util), Richard Hainsworth (UK, finanalyst) and Tadeusz Sośnierz (Poland, tadzik) willing to stick out their necks to become officially registered board members of the Raku Foundation. They all have many years of supporting what is now the Raku Programming Language under their belt!
Yes, I would have loved to see an even more diverse board. This is definitely a goal the Raku Foundation will pursue!
The third hurdle was finding a notary. A notary willing to notarize the founding of a "stichting" (Dutch word for "foundation") of which 4 of the 5 prospective board members were not able to attend any official notarizing meeting in person. Cheap online notaries only offered standard services: our Articles of Association were definitely not standard.
Then it turns out that Dutch notaries are very busy and are effectively able to pick the kind of easy / profitable work they want. Of the 8 notaries I contacted, only 2 actually replied within a day: and they both declined. Chasing after the initial email contact by phone, I found Noto Notarissen in Maastricht willing to take on our request: first possible in person meeting was 3 weeks after that.
The fourth hurdle was Napoleon Bonaparte. Say what? Well, yeah, in a way. What I hadn't realized was that Dutch law (as most current European laws) was heavily influenced by the Code Civil. This contrary to the UK and USA, which is mostly based on common English law.
In short: Dutch law (influenced by the Code Civil) is very strict on what the Articles of Association should contain, to ensure the legality of operation of the foundation. Whereas English / American law is more like: anything goes, will figure out the legality of its operation if and when it is needed.
Which basicaly meant that we were trying to put a round peg into a square hole. So it was really like "Notary says no!".
The notary was willing to provide a version of the Articles of Association that they would find acceptable, based on the Articles of Association that we provided. This took another few weeks of back-and-forth in Dutch, which was followed up by discussions of the translation between the prospective board members in English. In the end an agreement was reached, which you can now read as the official Artcles of Association (Statuten - Dutch version).
Normally if a notary notarizes a deed, all the people affected by the deed are present in person. This was not really an option for us: it would be pretty expensive (both as an intrusion of personal life, as well as financially) to get all board members in one place at one time for a ceremony that would take half an hour max.
The alternative was that each prospective board member would need to find a local notary (acceptable by our notary) and have them create an affidavit of the willingness of the person to be a board member. This would mean a financial burden on the prospective board members, and a big hassle.
So the notary suggested to just start the foundation with yours truly as the only board member, and then register the other board members with the Chamber of Commerce (CoC) as you normally would when board members are added (or removed). This appeared as an acceptable alternative to the prospective board, as it would mean being able to actually start with the foundation sooner rather than later.
On April 30th the ceremony happened, where the notary basically read the Articles of Association back to me (which I had been working on for quite some time already) making sure I knew what I was getting into. And the CoC confirmed the notarization on May 1st.
My first step after that, was getting a bank account for the foundation. Since I have been a customer of the Rabobank for 30+ years, and was already accredited with them, it felt like a natural thing to open a bank account with them for the Foundation. Also because their app has been really offering a lot of choices and capabilities that have made my life easier with banking.
Alas, opening a bank account with Rabobank for a foundation with a single board member was a giant RED flag for them: they would only consider opening a bank account for a foundation that had more than one board member registered.
Since I already had procured all of the prospective board members personal info, and the CoC has a pretty nice interactive website, it looked like it would be a piece of cake getting the board members registered.
Well, it would have been if the board members had been Dutch citizens and/or living in the Netherlands.
But no worries, the website allows you to produce a PDF that I could email to the board members, to have them sign that, scan it, email back to me, and then bring to the CoC (they only really take real paperwork). You can just snail-mail them the stuff, but because I wanted to be sure all was in order, I wanted a person of the CoC have a look at it before it getting processed.
It was a good thing I did: the initial version of the papers, was not acceptable.
A scan of a signature was not acceptable. This meant that board members had to snail-mail me the paper with their signature on it, which would mean additional delay.
The proof of address must be from an official source, in Dutch, English, French or German, and less than a month old. A bank statement didn't cut it. The Dutch CoC apparently assumes that the rest of the world is as well organized and registered as the Netherlands. Which isn't the case.
Germany proved to be easiest. The UK apparently doesn't have a governmental agency that keeps addresses: they do keep births and deaths, but not addresses. Fortunately, an election had just been in Wales, so it turned out that the invitation to vote was acceptable as a recent proof of address.
That means that Patrick and Richard are now officially registered.
For Bruce obtaining an acceptable proof of address was also difficult, but hopefully that's been sorted now (still being processed by CoC). For Tadeusz getting a non-Polish official proof of address was also not simple. But that paperwork is now underway to me (because that paper also has to be wet-signed by me before it gets processed).
Apparently starting a not-for-profit foundation with non-Dutch board members attempting to get funding from all over the world, raises a number of flags. This means that the Rabobank is currently performing an official investigation into the board members and the Raku Foundation, to determine what we want to do is legit or not.
The Rabobank also wants to be sure that the foundation is indeed not-for-profit.
This means we still don't have a bank account yet :-(
There are basically two entities in the Netherlands that can confirm your foundation is indeed not-for-profit: ANBI (Algemeen Nut Beogende Instelling, aka Public Benefit Organization).
The ANBI status is basically the Dutch IRS (Belastingdienst) registering that you applied for not-for-profit status. It has some prerequisites that I think we can all meet, once all board members have been officially registered.
And CBF (Centraal Bureau Fondsenwerving, aka Central Bureau for Fundraising). This entity is much more strict: one of their prerequisites is to have a yearly overview of all finances of the foundation. As we don't actually have a bank account yet, and we only (barely) exist for 6 weeks, this cannot be achieved before 2027.
So it appears we have a chicken-and-egg situation. Fortunately, the CBF has sent me an official denial of getting not-for-profit status solely on the fact that we don't have any financial accounting yet.
And then we needed a web-site. Steve Roe (the maker of the new raku.org website) was willing to set up a framework for that. The board has taken him up on this offer, and yours truly was able to build on that quite easily, for instance by adding the 2026 Policy Plan. And the most fun part: the whole website (from my point of view) is all just Raku code!
And the Raku Infra Team++ was able to quickly set up the website!
In the current geopolitical climate it felt inappropriate to store information pertaining to the foundation on a non-European site. Therefore we chose Codeberg as the place for our publicly available information.
We're live! Phew!
The coming weeks will see statements about interaction with current bodies, specifically TPRF (The Perl And Raku Foundation), and the RSC (Raku Steering Council).
We want to know about you! Historically, what is now the Raku Community has been a very loosley knit world-wide group of people interested in what now is the Raku Programming Language. We want to get a better view of the size of that community, and the needs of Raku Community members.
So please, make yourself known to us by entering your name and email address (and nick, if you will) on the Welcome page. This data will be handled according to the GDPR (an official statement by the Foundation on that will be added soon).
Hope to hear from you soon!
In the last two weeks there were quite a lot of discussions, posts, and articles about an OpenAI’s model disproving a conjecture by Paul Erdős, [OAI1]. Erdős posed the following unit distance problem in 1946:
What is the maximum number u(n) of unit-distance pairs (edges in the unit distance graph) determined by n points in the Euclidean plane?
Here are key elements of the original conjecture:
In graph-theoretic terms, this concerns the maximum edge density in a unit distance graph embeddable in the plane. The square lattice provided the foundational example for believing the exponent was close to 1.
This conjecture was widely believed for decades (with the square grid seen as the model for maximal constructions), but it was disproved in 2026 by an OpenAI model using algebraic or number-theoretic constructions that achieve a polynomial improvement (higher density than any square-grid-based approach).
For small n, other structures (e.g., triangular lattices or algebraic configurations like Moser spindles/rings) can be denser, but Erdős’ original asymptotic thinking centered on the square grid.
This is closely related to (but distinct from) the chromatic number of the plane (Hadwiger-Nelson problem), which also involves unit distance graphs.
Remark: Here is the K2,3 graph (which is a complete bipartite graph):
#% htmlGraph::Complete.new([2,3]).dot(vertex-shape => 'point'):svg

The OpenAI-vs-Erdős discussions “triggered” a particular path of learning-by-doing activities for me, which is outlined here:
powers-representations in “Math::NumberTheory”, [AAp2]This, second blog post (notebook) is the 13-th point of the list above — it shows how to make unit distance graphs using 2D lattices generated with complex number operations. (The first blog post is “Erdős unit distance conjecture examples — Part 1: Leaper graphs”, [AA1].)
use Math::NumberTheory;use Math::NumberTheory::Utilities;use Math::Nearest;use Math::DistanceFunctions;use NativeCall;use NativeHelpers::Array;use Data::Reshapers;use Graphviz::DOT::Chessboard;use NativeCall;
#%javascriptrequire.config({ paths: { d3: 'https://d3js.org/d3.v7.min'}});require(['d3'], function(d3) { console.log(d3);});
#%jsjs-d3-list-line-plot(10.rand xx 30, background => 'none')
my $title-color = 'Ivory';my $stroke-color = 'SlateGray';my $tooltip-color = 'LightBlue';my $tooltip-background-color = 'none';my $background = '#1F1F1F';my $color-scheme = 'schemeTableau10';my $edge-thickness = 3;my $vertex-size = 3;
It has been observed that highly dense unit distance graphs can be made over Morse lattices, [PE1]. Morse lattices can be defined as additive subgroups of the complex numbers, ℂ, that are isomorphic to ℤ⁴.
Here we define a function that computes the edges of a Morse lattice graph:
sub unit-distance-graph-edges(Numeric:D $alpha, Int:D $m) { my $omega = -0.5 + $alpha * 1i; my @r = (-$m ... $m); my @pt = do gather { for @r -> $a { for @r -> $b { for @r -> $c { for @r -> $d { my $p = $a + $b * 1i + $c * $omega + $d * 1i * $omega; take [$p.re, $p.im] } } } } } @pt = @pt.map({ copy-to-carray($_, num64) }); my &nf = nearest(@pt); my %conn; for @pt.kv -> $k, $p { my @neighbors = &nf($p, (Whatever, 1.1)); %conn{$k} = @neighbors.grep({ abs(1 - euclidean-distance($_, $p)) ≤ 1e-5 }); } %conn = %conn.grep(*.value.elems); my @edges = %conn.kv.map( -> $k, @v { @v.map({ [@pt[$k.Int], $_].sort }) }).flat(1)».Array.unique; my @vertices = flatten(@edges, 1).unique; my %vertex-coords = @vertices.kv.map( -> $k, $v { $k.Str => $v }); my %vertex-index = %vertex-coords.map({ $_.value => $_.key }); @edges = @edges.map({ [%vertex-index{$_[0]}, %vertex-index{$_[1]}] }); return %(:@edges, vertex-coordinates => %vertex-coords, :%vertex-index);}
Compute the graph with particular parameters:
my %res = unit-distance-graph-edges(sqrt(3)/2, 3);deduce-type(%res)
# Struct([edges, vertex-coordinates, vertex-index], [Array, Hash, Hash])
Here we get graph’s vertex coordinates and plot them:
#%jsmy @points = |%res<vertex-coordinates>.values;js-d3-list-plot( @points».Array, point-size => 3, background => 'none', :700width, :700height, :!axes, :$title-color, title => "Number of points : {@points.elems}")

The obtained graphs are clearly with non-uniform distribution of the points. This prompts us to analyze the vertex degrees. Here we make the graph object:
my $g = Graph.new(edges => %res<edges>, vertex-coordinates => %res<vertex-coordinates>)
# Graph(vertexes => 2401, edges => 11760, directed => False)
Here is a tally of the vertex degrees:
tally($g.vertex-degree)
# {10 => 1000, 12 => 625, 4 => 4, 5 => 8, 6 => 84, 7 => 80, 8 => 500, 9 => 100}
And here is the vertex degrees distribution:
#% jsjs-d3-bar-chart( tally($g.vertex-degree).map({ <x y>.Array Z=> [$_.key, $_.value] })».Hash.sort(*<x>), :$background, :$title-color, title => 'Distribution of vertex degrees')

A faster way of computing the graphs above — in Raku — is to use a relation graph over the points of a Moser lattice, [PE1]:
sub omega($t) { exp(i * acos(1 - 1/2 * $t))}my $omega = omega(1); # or just: -0.5 + sqrt(3)/2 * 1imy @gen = 1, 1i, $omega, 1i * $omega; # or just: i <<**>> (0, 1, 4/3, 7/3)) })my @p = cross((-2 ... 2) xx 4).map({ dot-product($_.Array, @gen) });my $gML = Graph::Relation.new({abs(abs(@p[$^a] - @p[$^b]) - 1) ≤ 1e-8}, ^@p.elems, as => {.Str}, vertex-coordinates => @p.kv.map(-> $k, $v { $k => [$v.re, $v.im]}).Hash);$gML
# Graph(vertexes => 625, edges => 2800, directed => False)
Plot the graph:
#% html$gML.dot( :!vertex-labels, vertex-color => 'Orange', vertex-fill-color => 'Orange', vertex-shape => 'point', vertex-width => 0.1, vertex-height => 0.1, edge-width => 0.4, edge-color => 'SteelBlue', :8graph-size, engine => 'neato'):svg

Let us make highlights on the graph based on vertex degrees:
my @highlight = $g.vertex-degree(:p).classify(*.value).map({ $_.value».key }).sort(-*.elems);deduce-type(@highlight)
# Tuple([Vector(Atom((Str)), 1000), Vector(Atom((Str)), 625), Vector(Atom((Str)), 500), Vector(Atom((Str)), 100), Vector(Atom((Str)), 84), Vector(Atom((Str)), 80), Vector(Atom((Str)), 8), Vector(Atom((Str)), 4)])
Plot the graph using Graphviz DOT (and related layout engines):
#% html$g.dot( :!vertex-labels, :@highlight, vertex-fill-color => 'orange', vertex-shape => 'point', vertex-width => 0.1, vertex-height => 0.1, edge-width => 0.2, :8graph-size, engine => 'neato'):svg

Bubble charts using “JavaScript::D3”:
#% jsmy %degrees = $g.vertex-degree():p;my @data = %res<vertex-coordinates>.map({ x => $_.value.head, y => $_.value.tail, z => %degrees{$_.key}, group => %degrees{$_.key}.Str })».Hash;@data .= sort({ -$_<z> * 100 + 10 * norm($_<x y>) + cosine-distance($_<x y>, [0, 1]) });my %opts = :500width, :500height, background => 'none', z-range-min => 6, z-range-max => 12, opacity => 0.4, color-palette => 'Tableau10', :!axes, :!tooltip, :!legends, :20margins ;js-d3-bubble-chart(@data.sort(*<z>), |%opts, z-range-min => 8, opacity => 0.2, color-palette => 'Blues[7]', stroke-color => 'Black')~js-d3-bubble-chart(@data, |%opts, z-range-min => 10, z-range-max => 24, opacity => 0.3, color-palette => 'RdBu[3]', stroke-color => 'none')~js-d3-bubble-chart(@data, |%opts, color-palette => 'Spectral[3]', stroke-color => 'none')
Remark: The z-ranges, opacities, and color palettes were chosen after 10 to 20 experiments in order to reveal the graph structure or configuration and produce compelling, attractive plots.
[AA1] Anton Antonov, “Erdős unit distance conjecture examples — Part 1: Leaper graphs”, (2026), RakuForPrediction at WordPress.
[DC1] Davide Castelvecchi, “AI cracks 80-year-old mathematics challenge — researchers are astonished”, Nature.com, DOI: https://doi.org/10.1038/d41586-026-01651-0.
[PE1] Peter Engel et al., “Diverse beam search to find densest-known planar unit distance graphs”, arXiv:2406.15317 [math.CO], (2025), arxiv.org.
[OAI1] OpenAI, “An OpenAI model has disproved a central conjecture in discrete geometry”, (2026), openai.com.
[PB1] Peter Brass et al., Research Problems in Discrete Geometry, 2005, Springer. ISBN-13: 978-0387-23815-8.
[AAn1] Anton Antonov, “Unit distance graph animations”, (2026), Wolfram Community.
[EPn1] Ed Pegg, “OpenAI disproves Erdős unit distance conjecture”, (2026), Wolfram Community.
[AAp1] Anton Antonov, Graph, Raku package, (2024-2026), GitHub/antononcube.
[AAp2] Anton Antonov, Math::NumberTheory, Raku package, (2025-2026), GitHub/antononcube.
[AAp3] Anton Antonov, Math::DistanceFunctions, Raku package, (2024-2026), GitHub/antononcube.
[AAp4] Anton Antonov, Math::DistanceFunctions::Native, Raku package, (2024), GitHub/antononcube.
[AAp5] Anton Antonov, Graphviz::DOT::Chessboard, Raku package, (2024), GitHub/antononcube.
[AAp6] Anton Antonov, Image::Markup::Utilities, Raku package, (2023-2026), GitHub/antononcube.
In the last two weeks there were quite a lot of discussions, posts, and articles about an OpenAI’s model disproving a conjecture by Paul Erdős, [OAI1]. Erdős posed the following unit distance problem in 1946:
What is the maximum number u(n) of unit-distance pairs (edges in the unit distance graph) determined by points in the Euclidean plane?
Here are key elements of the original conjecture:
In graph-theoretic terms, this concerns the maximum edge density in a unit distance graph embeddable in the plane. The square lattice provided the foundational example for believing the exponent was close to 1.
This conjecture was widely believed for decades (with the square grid seen as the model for maximal constructions), but it was disproved in 2026 by an OpenAI model, [OAI1], using algebraic or number-theoretic constructions that achieve a polynomial improvement (higher density than any square-grid-based approach).
For small , other structures (e.g., triangular lattices or algebraic configurations like Moser spindles/rings) can be denser, but Erdős’ original asymptotic thinking centered on the square grid.
This is closely related to (but distinct from) the chromatic number of the plane (Hadwiger-Nelson problem), which also involves unit distance graphs.
Remark: Here is the K(2,3) graph (which is a complete bipartite graph):
#% htmlGraph::Complete.new([2,3]).dot(vertex-shape => 'point'):svg

The OpenAI-vs-Erdős discussions “triggered” a particular path of learning-by-doing activities for me, which is outlined here:
powers-representations in “Math::NumberTheory”, [AAp2]This document (notebook) is the 11-th point of the list above — it shows how to make, plot, and animate collections of unit distance leaper graphs.
use Graph;use Graphviz::DOT::Chessboard;use Math::NumberTheory;use Math::DistanceFunctions;use Data::Reshapers;use Image::Markup::Utilities;
my $title-color = 'Ivory';my $stroke-color = 'SlateGray';my $tooltip-color = 'LightBlue';my $tooltip-background-color = 'none';my $background = '#1F1F1F';my $color-scheme = 'schemeTableau10';my $edge-thickness = 3;my $vertex-size = 3;
In order to construct square grid graphs with edges that are of length 1, we consider the family of leaper graphs. The Leaper graph generalizes the Knight Tour graph. Here are the moves of Camel graph, Flamingo graph, and Zebra graph, which are leaper graphs parameterized with , , and , respectively:
#% htmlmy %opts-brown = black-square-color => 'SandyBrown', white-square-color => 'Moccasin', :65font-size;my $fenC = '8/2N1N2/8/N5N1/3n3/N5N1/8/2N2N2';my $c = dot-chessboard($fenC, :7r, :7c, :4size, background=>'none', |%opts-brown, :svg);$c .= subst(/ '♞' | '♘'/, '🐪', :g);my %opts-blue = black-square-color => 'DarkSeaGreen', white-square-color => 'Wheat', :65font-size;my $fenF = '8/N1N5/8/8/8/6N1/1n6/6N1';my $f = dot-chessboard($fenF, :7r, :7c, :4size, background=>'none', |%opts-blue, :svg);$f .= subst(/ '♞' | '♘'/, '🦩', :g);my %opts-green = black-square-color => '#779556ff', white-square-color => '#ebedb7', :65font-size;my $fenZ = '8/1N3N1/N5N1/8/3n3/8/N5N1/1N3N1';my $z = dot-chessboard($fenZ, :7r, :7c, :4size, background=>'none', |%opts-green, :svg);$z .= subst(/ '♞' | '♘'/, '🦓', :g);$c ~ $f ~ $z
Remark: From the code and plots above it can be seen that the package “Graphviz::DOT::Chessboard”, [AAp5], can handle chess boards and FEN notations with non-standard sizes.
We can ask ourselves:
To answer the first question, we observe that we can rescale the “chess board” of the leaper graph in such a way that each leap has “over air” distance of 1. For example, the integer coordinates of an board can be divided by and that would make leaper graphs parameterized with and to have edges of unit length.
powers-representations(25, 2, 2)
# ((0 5) (3 4))
my ($rows, $columns) = (8, 8);my $g1 = Graph::Leaper.new(moves => [0, 5], :$rows, :$columns);my $g2 = Graph::Leaper.new(moves => [3, 4], :$rows, :$columns);my $g = $g1.union($g2)
# Graph(vertexes => 64, edges => 128, directed => False)
Here we rescale the vertex coordinates in order to get edges with unit length:
sink $g.vertex-coordinates = $g.vertex-coordinates.map({ $_.key => $_.value <</>> 5}).Hash
Plot the graph:
#% html$g.dot( engine => 'neato', graph-size => 5, vertex-shape => 'point', vertex-width => 0.02, vertex-height => 0.02, vertex-color => 'SlateGray', vertex-fill-color => 'SlateGray', edge-thickness => 0.2):svg

Let us convince ourselves that the edges of that graph have unit length:
$g.edgesandthen .map({ $g.vertex-coordinates{$_.key}, $g.vertex-coordinates{$_.value} })andthen .map({ euclidean-distance(|$_) })andthen .Listandthen (min => $_.min, max => $_.max)
# (min => 0.9999999999999998 max => 1)
That was just one, a relatively small graph. Can we find other leaper graphs based on representations with two or more terms? Here we search for integers that:
(1...10_000).grep({ my @fs = |factor-integer($_); @fs.elems == 1 && @fs.head.tail == 2 }).map({ $_ => powers-representations($_, 2, 2) }).grep({ $_.value.elems ≥ 2 })
# (25 => ((0 5) (3 4)) 169 => ((0 13) (5 12)) 289 => ((0 17) (8 15)) 841 => ((0 29) (20 21)) 1369 => ((0 37) (12 35)) 1681 => ((0 41) (9 40)) 2809 => ((0 53) (28 45)) 3721 => ((0 61) (11 60)) 5329 => ((0 73) (48 55)) 7921 => ((0 89) (39 80)) 9409 => ((0 97) (65 72)))
For example, if we pick the third smallest number of the ones found, , we can make two leaper graphs and combine them as above.
my $g1 = Graph::Leaper.new(moves => [0, 17], :27rows, :27columns);my $g2 = Graph::Leaper.new(moves => [8, 15], :27rows, :27columns);my $g = $g1.union($g2)
# Graph(vertexes => 729, edges => 1452, directed => False)
Here we rescale vertex coordinates (in order to get unit length edges):
sink $g.vertex-coordinates = $g.vertex-coordinates.map({ $_.key => $_.value <</>> 17 }).Hash;
Plot the graph:
#% html$g.dot(engine => 'neato', graph-size => 8, edge-thickness => 0.5, vertex-shape => 'point', vertex-width => 0.1, vertex-height => 0.1, :!vertex-labels ):svg

We can just make leaper graphs in order to produce some interesting to look at patterns of lines. For example:
#% htmlmy $g = Graph::Leaper.new(moves => [31, 21], :45rows, :45columns);$g.dot(engine => 'neato', :8graph-size, edge-thickness => 0.4, vertex-shape => 'point', :0vertex-width, :0vertex-height):svg

Let us make an animation of images of leaper graphs. First we derive the graph plots:
my @all-moves = (1, 2 ... 35) X (1, 2 ... 21);@all-moves .= grep({ are-coprime(|$_) && $_.all ≥ 6 && $_.sum ≥ 30 });say 'all-moves : ', @all-moves.elems;my @rules = @all-moves.pairs.map({ my $i = $_.key; my @moves = |$_.value; say (:$i) if $i %% 20; my $g = Graph::Leaper.new(:@moves, :45rows, :45columns); $i => $g.dot( engine => 'neato', :8graph-size, vertex-shape => 'point', vertex-width => 0, vertex-height => 0, edge-thickness => 0.23, edge-color => 'ivory', background => 'black', ):svg});deduce-type(@rules)# ≈2m
# all-moves : 185# i => 0# i => 20# i => 40# i => 60# i => 80# i => 100# i => 120# i => 140# i => 160# i => 180
# Vector(Pair(Atom((Int)), Atom((Str))), 185)
Sort the graph plots according to the sums of the squares of their leaps (and the take SVG values):
my @imgs = @rules.sort({ sum(@all-moves[|$_.key] <<**>> 2) })».value;deduce-type(@imgs)
# Vector(Atom((Str)), 185)
Make an animation with the list of images (SVG strings):
#%htmlsink my $res = list-animate(@imgs, :10duration, repeat-count => 'indefinite')# ≈11s without rendering# ≈3m with rendering
Export the obtained SVG animation into one file:
spurt('./img/leaper-graphs-from-45-35-21-coprime-30sum.svg', $res)
# True
In general, the SVG animation file can be quite large. (E.g. ≈50MB, or 200MB.) That is why we might prefer making PNG or JPEG images for the graphs plots and then combining them into a movie.
Export each SVG graph plot (into a directory of frames), then convert the SVG file into a PNG image using rsvg-convert:
sink for @rules.sort({ sum(@all-moves[|$_.key] <<**>> 2) }).kv -> $index, $p { my $svg-content = $p.value; my $filename = sprintf "./img/leaper-graph-frames/frame%05d.svg", $index; say (:$filename) if $index %% 20; spurt $filename, $svg-content; my $png-filename = sprintf "./img/leaper-graph-frames/frame-%05d.png", $index; shell "rsvg-convert -w 800 -h 800 -o $png-filename $filename";}# ≈45s
# filename => ./img/leaper-graph-frames/frame00000.svg# filename => ./img/leaper-graph-frames/frame00020.svg# filename => ./img/leaper-graph-frames/frame00040.svg# filename => ./img/leaper-graph-frames/frame00060.svg# filename => ./img/leaper-graph-frames/frame00080.svg# filename => ./img/leaper-graph-frames/frame00100.svg# filename => ./img/leaper-graph-frames/frame00120.svg# filename => ./img/leaper-graph-frames/frame00140.svg# filename => ./img/leaper-graph-frames/frame00160.svg# filename => ./img/leaper-graph-frames/frame00180.svg
Make a movie using FFmpeg:
#% bash# ffmpeg -framerate 6 -pattern_type glob -i './img/leaper-graph-frames/frame-*.png' -c:v libx264 -pix_fmt yuv420p -crf 23 -movflags +faststart ./img/output.mp4
The animation can be seen here (Imgur).
[OAI1] OpenAI, “An OpenAI model has disproved a central conjecture in discrete geometry”, (2026), openai.com.
[AAn1] Anton Antonov, “Unit distance graph animations”, (2026), Wolfram Community.
[EPn1] Ed Pegg, “OpenAI disproves Erdős unit distance conjecture”, (2026), Wolfram Community.
[AAp1] Anton Antonov, Graph, Raku package, (2024-2026), GitHub/antononcube.
[AAp2] Anton Antonov, Math::NumberTheory, Raku package, (2025-2026), GitHub/antononcube.
[AAp3] Anton Antonov, Math::DistanceFunctions, Raku package, (2024-2026), GitHub/antononcube.
[AAp4] Anton Antonov, Math::DistanceFunctions::Native, Raku package, (2024), GitHub/antononcube.
[AAp5] Anton Antonov, Graphviz::DOT::Chessboard, Raku package, (2024), GitHub/antononcube.
[AAp6] Anton Antonov, Image::Markup::Utilities, Raku package, (2023-2026), GitHub/antononcube.
The Raku package “DSL::Examples”, [AAp1], is a “data package” with examples of DSL commands translations to programming code.
The DSL examples are suitable for LLM few-shot training. The sub llm-example-function provided by “LLM::Functions”, [AAp3], can be effectively used to create translation functions utilizing those examples.
The utilization of such LLM-translation functions is exemplified below. Also in the presentation “Robust LLM pipelines (Mathematica, Python, Raku)”, [AAv1]:
Similar translations — with much less computational resources — are achieved with grammar-based DSL translators; see “DSL::Translators”, [AAp2]. The package “LLM::Resources”, [AAp4], has LLM-graphs for code generation that utilize the DSL examples of this package.
Get all examples:
use DSL::Examples;use Data::TypeSystem;dsl-examples() ==> deduce-type()
# Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 17), Assoc(Atom((Str)), Atom((Str)), 14), Assoc(Atom((Str)), Atom((Str)), 32), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 27), Assoc(Atom((Str)), Atom((Str)), 6)]), 7), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 10), Assoc(Atom((Str)), Atom((Str)), 26), Assoc(Atom((Str)), Atom((Str)), 17), Assoc(Atom((Str)), Atom((Str)), 20)]), 4), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 15), Assoc(Atom((Str)), Atom((Str)), 23), Assoc(Atom((Str)), Atom((Str)), 33), Assoc(Atom((Str)), Atom((Str)), 20)]), 4), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 15), Assoc(Atom((Str)), Atom((Str)), 10), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 6)]), 4)]), 4)
Tabulate all translation languages and available workflow examples:
use Data::Translators;dsl-examples(from => 'English').map({ $_.key X $_.value.keys }).flat(1).map({ <language workflow> Z=> $_ })».Hash.sort.Array==> to-dataset()==> to-html(field-names => <language workflow>)
| language | workflow |
|---|---|
| Python | LSAMon |
| Python | QRMon |
| Python | SMRMon |
| Python | pandas |
| R | DataReshaping |
| R | LSAMon |
| R | QRMon |
| R | SMRMon |
| Raku | DataReshaping |
| Raku | LSAMon |
| Raku | SMRMon |
| Raku | TriesWithFrequencies |
| WL | ClCon |
| WL | DataReshaping |
| WL | LSAMon |
| WL | QRMon |
| WL | SMRMon |
| WL | Tabular |
| WL | TriesWithFrequencies |
Note that for dsl-examples the language to translate from is specified. Currently, the package has DSL examples for Bulgarian, English, Portuguese, and Russian (being from-languages.)
Get the examples for Latent Semantic Analysis (LSA) Monadic pipeline segments in Python:
dsl-examples('Python', 'LSAMon') ==> deduce-type(:tally)
# Assoc(Atom((Str)), Atom((Str)), 15)
Make an LLM example function for translation of LSA workflow building commands:
use LLM::Functions;my &llm-pipeline-segment = llm-example-function(dsl-examples()<WL><LSAMon>);
Run the LLM function over a list of DSL commands:
my @commands = "use the dataset aAbstracts","make the document-term matrix without stemming","exract 40 topics using the method non-negative matrix factorization","show the topics";@commands.map({ .&llm-pipeline-segment }).map({ .subst(/:i Output ':'?/):g }).join("⟹\n")
# LSAMonUnit[aAbstracts]⟹# LSAMonMakeDocumentTermMatrix["StemmingRules"->{},"StopWords"->Automatic]⟹# LSAMonExtractTopics["NumberOfTopics" -> 40, Method -> "NNMF"]⟹# LSAMonEchoTopicsTable[]
Same workflow specified in Bulgarian:
my &llm-pipeline-segment-bg = llm-example-function(dsl-examples(from => 'Bulgarian')<WL><LSAMon>);my @commands = "използавай данните aAbstracts","направи документ-терм матрицата без да използаваш стъблата на думите","намери 40 теми ползвайки методата не-отрицателна матрична факторизация","покажи темите";@commands.map({ .&llm-pipeline-segment-bg }).map({ .subst(/:i Output ':'?/):g }).join("⟹\n")
# LSAMonUnit[aAbstracts]⟹# LSAMonMakeDocumentTermMatrix["StemmingRules"->{}]⟹# LSAMonExtractTopics["NumberOfTopics"->40,Method->"NNMF"]⟹# LSAMonEchoTopicsTable[]
There are several ways to organize the DSL examples with respect to the from-languages:
| Type | Comment | Currently used |
|---|---|---|
| Have a separate file for each from-langauge | Convenient editing and refinement | Yes |
| One file of all examples; from-langauge is a key for each workflow | Can be produces with the separate files | No |
| Keep English-only DSL examples and use dictionaries of command translations to English | Does not train the LLM directly with the from-language | Dictionaries are kept for reference |
This Jupyter notebook has a workflow for the translation of the English DSL examples into other languages.
[AAp1] Anton Antonov, DSL::Examples, Raku package, (2024-2026), GitHub/antononcube.
[AAp2] Anton Antonov, DSL::Translators, Raku package, (2020-2026), GitHub/antononcube.
[AAp3] Anton Antonov, LLM::Functions, Raku package, (2023-2026), GitHub/antononcube.
[AAp4] Anton Antonov, LLM::Resources, Raku package, (2026), GitHub/antononcube.
[AAv1] Anton Antonov, “Robust LLM pipelines (Mathematica, Python, Raku)”, (2024), YouTube/AAA4prediction.
Раку пакетът “DSL::Examples“, [AAp1], е „даннов пакет“ с примери за превод на DSL команди към програмен код.
Послучай 24-ти май аз реших да обогатя този пакет с примери на български и руски.
DSL примерите в пакета са подходящи за LLM few-shot обучение. Подпрограмата llm-example-function, предоставена от “LLM::Functions“, [AAp3], може ефективно да се използва за създаване на функции за превод, използващи тези примери.
Използването на такива LLM-функции за превод е показано по-долу. Също и в презентацията “Robust LLM pipelines (Mathematica, Python, Raku)“, [AAv1]:
Подобни преводи — с много по-малко изчислителни ресурси — се постигат с граматично-базирани DSL преводачи; вижте
“DSL::Translators“, [AAp2]. Пакетът “LLM::Resources“, [AAp4], съдържа LLM-графи за генериране на код, които използват DSL примерите от този пакет.
Получаване на всички примери:
use DSL::Examples;use Data::TypeSystem;dsl-examples() ==> deduce-type()
# Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 17), Assoc(Atom((Str)), Atom((Str)), 14), Assoc(Atom((Str)), Atom((Str)), 32), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 27), Assoc(Atom((Str)), Atom((Str)), 6)]), 7), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 10), Assoc(Atom((Str)), Atom((Str)), 26), Assoc(Atom((Str)), Atom((Str)), 17), Assoc(Atom((Str)), Atom((Str)), 20)]), 4), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 15), Assoc(Atom((Str)), Atom((Str)), 23), Assoc(Atom((Str)), Atom((Str)), 33), Assoc(Atom((Str)), Atom((Str)), 20)]), 4), Assoc(Atom((Str)), Tuple([Assoc(Atom((Str)), Atom((Str)), 15), Assoc(Atom((Str)), Atom((Str)), 10), Assoc(Atom((Str)), Atom((Str)), 20), Assoc(Atom((Str)), Atom((Str)), 6)]), 4)]), 4)
Табулиране на всички езици за превод и наличните примери за работни потоци:
use Data::Translators;dsl-examples(from => 'English').map({ $_.key X $_.value.keys }).flat(1).map({ <language workflow> Z=> $_ })».Hash.sort.Array==> to-dataset()==> to-html(field-names => <language workflow>)
| language | workflow |
|---|---|
| Python | LSAMon |
| Python | QRMon |
| Python | SMRMon |
| Python | pandas |
| R | DataReshaping |
| R | LSAMon |
| R | QRMon |
| R | SMRMon |
| Raku | DataReshaping |
| Raku | LSAMon |
| Raku | SMRMon |
| Raku | TriesWithFrequencies |
| WL | ClCon |
| WL | DataReshaping |
| WL | LSAMon |
| WL | QRMon |
| WL | SMRMon |
| WL | Tabular |
| WL | TriesWithFrequencies |
Обърнете внимание, че в dsl-examples се задава езикът, от който се превежда. В момента пакетът съдържа DSL примери за български, английски, португалски и руски език (като изходни езици).
Получаване на примерите за сегменти от монадични конвейери за латентен семантичен анализ (LSA) в Python:
dsl-examples('Python', 'LSAMon') ==> deduce-type(:tally)
# Assoc(Atom((Str)), Atom((Str)), 15)
Създаване на LLM функция-пример за превод на команди за изграждане на LSA конвейр:
use LLM::Functions;my &llm-pipeline-segment = llm-example-function(dsl-examples()<WL><LSAMon>);
Изпълнение на LLM функцията върху списък от DSL команди:
my @commands = "use the dataset aAbstracts","make the document-term matrix without stemming","exract 40 topics using the method non-negative matrix factorization","show the topics";@commands.map({ .&llm-pipeline-segment }).map({ .subst(/:i Output ':'?/):g }).join("⟹\n")
# LSAMonUnit[aAbstracts]⟹# LSAMonMakeDocumentTermMatrix["StemmingRules"->{},"StopWords"->Automatic]⟹# LSAMonExtractTopics["NumberOfTopics" -> 40, Method -> "NNMF"]⟹# LSAMonEchoTopicsTable[]
Същият работен поток, зададен на български:
my &llm-pipeline-segment-bg = llm-example-function(dsl-examples(from => 'Bulgarian')<WL><LSAMon>);my @commands = "използавай данните aAbstracts","направи документ-терм матрицата без да използаваш стъблата на думите","намери 40 теми ползвайки метода не-отрицателна матрична факторизация","покажи темите";@commands.map({ .&llm-pipeline-segment-bg }).map({ .subst(/:i Output ':'?/):g }).join("⟹\n")
# LSAMonUnit[aAbstracts]⟹# LSAMonMakeDocumentTermMatrix["StemmingRules"->{}]⟹# LSAMonExtractTopics["NumberOfTopics"->40,Method->"NNMF"]⟹# LSAMonEchoTopicsTable[]
Съществуват няколко начина за организиране на DSL примерите по отношение на изходните езици:
| Тип | Коментар | Използва се в момента |
|---|---|---|
| Отделен файл за всеки изходен език | Удобно редактиране и усъвършенстване | Да |
| Един файл с всички примери; изходният език е ключ за всеки работен поток | Може да бъде генериран от отделните файлове | Не |
| Запазване само на английски DSL примери и използване на речници за превод на командите към английски | Не обучава директно LLM с изходния език | Речниците се пазят за справка |
Тази тетрадка на Jupyter има процедура за превода на английските примери към други езици.
[AAp1] Anton Antonov, DSL::Examples Raku package, (2024-2026), GitHub/antononcube.
[AAp2] Anton Antonov, DSL::Translators Raku package, (2020-2026), GitHub/antononcube.
[AAp3] Anton Antonov, LLM::Functions Raku package, (2023-2026), GitHub/antononcube.
[AAp4] Anton Antonov, LLM::Resources Raku package, (2026), GitHub/antononcube.
[AAv1] Anton Antonov, Robust LLM pipelines (Mathematica, Python, Raku), (2024), YouTube/AAA4prediction.

It has been normal and expected for a long long time that any machine code they spit out would come with a bunch of metadata that is meant to be used by different pieces of the target system.
There is of course symbol names for functions, which allow you to use the instruction pointer to find what the function it's currently in is called, and where it starts. Plus, when a dynamic library (a DLL, dylib, or so) is loaded, the symbol names are a part of what allows you to actually call the functions that you want.
There's the debug data, which can include a wide variety of things. The interesting parts for this post are line number annotations that you can use to take the instruction pointer and not only get the name of the function it belongs to, but also the file name and line number (and more).
For languages like C++ that have exceptions, there is tables with the necessary information to find out at run time when an exception is thrown, how each of the frames on the stack want to deal with it. Of course this includes checking if there is a try block in the function that covers where inside the function the instruction pointer currently sits.
In the process of handling exceptions, it is typically necessary to get rid of some amount of stack frames, as if the code had returned from these functions. This is called "stack unwinding".
You don't want to compile special code into every function to handle the possibly quite rare case that an exception passes it by. In order to support unwinding frames, the run time library will read data put into the program by the compiler that tells it exactly what needs to happen to properly get rid of the stack frame, depending on where exactly the instruction pointer is.
"Getting rid of the stack frame" also includes things like freeing different kinds of resources. This should be familiar to any C++ programmer, where you can have local variables that are cleaned up automatically when execution leaves the scope in which it is valid.
But MoarVM, which I haven't told you yet this post is about, is written in C and even though the Raku (and nqp) code it runs has exceptions, Raku exceptions are basically unrelated to the C stack. Why, then, am I talking about exceptions and stack unwinding tables?
The reason why I know more than the most surface details is that something related to this broke suddenly when MoarVM was compiled on Windows starting at a specific version of MSVC.
The reason why that can happen in a project written in C, which doesn't have exceptions like C++ does, is that we do use longjmp for "basically exception handling, but with only one bell, and no whistles":
When the implementation of some opcode encounters a problem ("the specified attribute doesn't exist", "wrong type for this kind of op", etc etc) we can just call the function MVM_exception_throw_adhoc with a string and we jump from however deep in the C stack we may be back to the interpreter loop where we translate the exception into the kind of exception that Raku works with.
The change that caused this to explode was that on Windows, the implementation of longjmp changed so that it always tries to fully unwind the stack frame-by-frame. For C code it would otherwise be possible to do the entire unwinding process by just changing the stack pointer to what it was at the point setjmp was used. After all, C doesn't have per-frame / per-function cleanup.
This wouldn't be a problem, since the compiler could just emit all the unwinding data for everything. Except that MoarVM also has a JIT compiler. The JIT compiled code usually calls into the same implementation functions that the interpreter itself would use, so a frame from JITted code may be on the stack at the time longjmp happens, and we didn't have anything in the JIT compiler to provide the necessary data to allow Microsoft's implementation of longjmp to handle these, causing a crash at run time.
"Oops"
I started working on code to provide the necessary data, since the WinAPI offers functions for exactly this purpose. I had difficulties doing development on the free Windows VM that you can get from Microsoft, so it was a bit of a painful process, and a fix that takes a whole lot less code came to the rescue. You can still look at the code I wrote to generate unwinding information for our JITted code and registering it with the WinAPI function RtlAddFunctionTable here in my MoarVM pull request.
The simpler fix we ended up going with, including a lengthy explanation of the problem and solution, can be found in this pull request from Patrick Böker, with thanks to Lazymio for this post from the Unicorn Devblog.
But this was an important step on my journey towards the main topic of this post:
What are the ways our JIT compiler can tell other parts of the system (including not just the OS, but also development tools such as profilers and debuggers) information about the code it spits out?
APIs I've already come across and done something with:
RtlAddFunctionTable lets you give unwinding info to the WinAPI and its consumers, including where a jitted function starts, but doesn't let you give it a name._U_dyn_register lets you give a function a name and provide a table of unwind instructions.JITDUMP format is meant to be used with Linux's "perf" tool. It lets you give a function name, an unwind table, and even line number annotations! It requires a post-processing step though.There's also techniques I've seen but haven't myself tried yet. The first thing that comes to mind is to create a full ELF file (or DLL on windows or dylib on macos), write it to disk, then load it with dlopen.
There's also one thing I wish was there but I couldn't find a way to have it yet. I'll show you at the very end of the post!
The simplest out of all of these by far is the "Perf Map". We've had support for this in MoarVM going back to September of 2018. It allows you to see the names of functions and the filename they are associated with in the "report" output from the perf tool, and presumably some other profiling tools can consume this format as well.
The main drawback of this is that perf at least won't be able to let you look at the assembly of these functions. I assume this is because there's nothing that keeps the machine code around.
On the other end of the simplicity scale sits creating loadable dynamic library files and loading them into the process. It's also the only approach out of these that I could imagine probably works fine with every external tool. You just have to be fine with keeping the files around until the moment your tool needs them. After all, libraries aren't meant to disappear forever after the program has finished. Also, it feels like a lot of boring work to write a correct ELF (plus whatever your other target platforms want) file essentially by hand (of course you could use all the struct definition), and doing a round-trip to the filesystem feels like it might incur a heavy performance penalty. I haven't tried it though!
The next approach I will describe is using RtlAddFunctionTable or libunwind's _U_dyn_register, which are very similar. If I remember correctly, I didn't actually get RtlAddFunctionTable to work, and I'm not sure what exactly I was missing. I think it might have been related to address spaces, offsets, and stuff. It is however very similar to how _U_dyn_register works. The latter only works if you want to walk stack frames in your own program for whatever reason. I didn't see anything that can just piggy-back on libunwind's internal data structures to use the data for other purposes. If you want, you can compare the RtlAddFunctionTable implementation I linked above with the commit that has the equivalent thing in it.
Now we will take a look at GDB's "jitreader" feature. Essentially, there is a symbol called __jit_debug_descriptor that GDB will look at whenever you call a function called __jit_debug_register_code (which is otherwise empty). It points at a doubly-linked list with addresses and sizes of "symfiles". You can make up your own definition of what is actually stored at the address, since you will have to implement the code to interpret the data at this address yourself. That's because the second half of the jitreader feature is a dynamic library that you load into gdb itself. When you tell it to load the jitreader, GDB will run the gdb_init_reader function in your plugin and expects you to give it implementations of a few functions, including a function to read the debug info. GDB passes you a struct full of function pointers including one to read bytes from the target process, and functions that let you create an "object", a "symtab", a "block" inside a symtab, and adding a "line mapping" to your object. Here's a link to where I use these functions to introduce jitted functions to GDB. It has been over a year since I last touched this code, so I'm not exactly certain of the details, like "do the line mappings actually work as expected?", and I certainly can't vouch for any of this code being correct. But it does put jitted code with name, filename, and line number in backtraces, like this:
#6 0x00007ffff746a483 in MVM_io_write_bytes (tc=0x5dd68020180, oshandle=<optimized out>, buffer=<optimized out>)
at src/io/io.c:178
#7 0x00007ffff575cb3e in spurt () at SETTING::src/core.c/IO/Handle.rakumod:7
#8 0x00007ffff7428d26 in MVM_interp_run (tc=<optimized out>, initial_invoke=<optimized out>,
initial_invoke@entry=0x7ffff7561080 <toplevel_initial_invoke>, invoke_data=<optimized out>,
outer_runloop=<optimized out>, outer_runloop@entry=0x0) at src/core/interp.c:6459
The perhaps roughest part was maybe writing the unwind function. The jitted code we spit out adheres to the x64 SYSV ABI (on linux, that is) including the frame pointer being at the expected place. I didn't see an obvious way to just have GDB do the default unwinding, so I implemented restoring all the relevant registers of the previous frame by hand with the functions GDB gave me. Not using push and pop opcodes in our JIT has the benefit that no matter where the Instruction Pointer lands, exccpt right at the very first few instructions, the steps to unwind the frame are the same.
If you have more questions, such as what other interesting information you can put into the debug info that the program "sends" to GDB, or what else you can do when GDB encounters one of your jitted frames, you may have better luck reading the GDB documentation yourself ... It is sadly rather sparse on the topic of the jit reader API but on the topic of extending GDB with Python (which is the route I have chosen to make MoarVM easier to debug) there is much more to see. GDB being a GNU project, you will not be surprised to learn that another way to extend it is to use Guile Scheme, which I myself have not tried before.
I could have sworn I had a WIP / PoC for using the GDB Python API using Frame Filters and DisassembleInfo to show much more information for disassembled JIT code, but for the life of me I can't find it any more ...
If you find this interesting, let me recommend this blog post that Max Bernstein wrote about the GDB Jit Interface including an explanation of how you used to have to create a full shared object in memory to have GDB understand your jitted functions, a few implementations of that version of the interface, and how the new "jitreader" plugin approach allows you to do it more easily, and finally a jitreader plugin that just reads Perf Map files.
Even though this post is already quite lengthy, I'm going to spill a bunch more ink for the API that took me the furthest so far in my journey to debug and profile jitted code on a fine-grained level: The JITDUMP format.
Here's the official specification of the JITDUMP format in the linux kernel's perf folder. If you want to follow along, here's a/the Pull Request on github that puts JITDUMP support into MoarVM. Here's also a blog post that helped me get started, which shows how to write JITDUMP files in rust.
The long and short of it is this: Your process opens a file in whatever place you find convenient (new files will later be created next to it, so a freshly created folder is a good choice). You mmap it executable as a kind of "signal" or "marker" event, and you write the monotonic clock value at that moment into the header. Then you can write variable-sized blocks of data every time your jit does something specific, like finalizing a blob of machine code at a given location, again with the monotonic clock timestamp. Maybe the most important piece of the puzzle is that when adding such a blob of machine code to the file, you also have to include the entirety of the machine code in the file. I guess this is what makes it the jit "dump" file!
Later on, a perf recording of your process execution (with -k 1 to choose the same monotonic clock as the time source used in the recording) can be enhanced with the separate perf inject tool. This tool can do a few tasks, but the one we're interested in is the one that the --jit flag controls: Feed it your jitdump file, pass your perf.data as the input and something like perf.jit.data as the output filename and perf inject will create an entire .so file for each of the jitted frames, and using the timestamps from the jitdump file to cross-reference when each frame becomes available (or unavailable again) somehow stores the connection between raw memory address during runtime to actual jitted function inside a .so file.
After all of this work, we can finally open a regular perf report, go into one of our jitted frames, and finally be presented with disassembly, just as if the jitted function had been an AOT-compiled function the entire time! (But probably not as thoroughly optimized).
Of course, the recording and reporting options you know and love should all work: Higher frequency of sampling, sampling stack traces along with each event, recording with different events than just the CPU cycle counter, and so on.
If you read the JITDUMP specification yourself, you will have noticed that I didn't mention the support it has for unwinding information, nor the support for source line information. I actually didn't have a need for either of these yet. Presumably, if I created an output file with something like the spesh dump which has all the MoarVM bytecode ("disassembled") in the basic blocks and what-not, I could generate filename + line number pairs for all the instructions to place them at the exact right spot in the perf report output as well. I really need to look into what that might allow me to do, but for now I didn't have the time for it (but somehow I did have the time to write a good three thousand words about all of this? go figure.)
One utility that I haven't mentioned yet in this post is Valgrind, the dynamic instrumentation framework, which famously comes with the memcheck memory correctness checker and the cachegrind and callgrind performance profilers.
Valgrind offers a few "client requests" which let you tell the system helpful information about what your program is doing, for example when you have a custom allocator, you can tell valgrind what functions serve what function, and how memory "pools" and "pages" and such work in your implementation.
You can also manually mark memory as "this should not be written to", or "this must not be treated as a pointer".
Valgrind itself is way more than this. You can use it to write any kind of tool yourself that needs to run a program and at the same time make changes to the machine code that ends up executing on the CPU. This is what "instrumentation" refers to.
I just wanted to get correct function names and boundaries inside the output of callgrind / cachegrind (which can be visualized with kcachegrind), and ideally also a disassembly view of jitted functions, since that's where it can show you for every "outgoing" call instruction all the functions it ends up calling, and how often it hits each, and how much time is spent in which of the targets, etc.
Unfortunately, documentation for this part of the whole system is relatively sparse. I assume not many have had the same desire I had? Long ago I built a very naive attempt to post-process the callgrind or cachegrind output file and translate addresses if they fall into a jitted function's bounds to instead refer to a "function entry" as it were. Unfortunately, I couldn't get it to result in usable call graphs inside kcachegrind and I found it difficult to figure out where exactly to look for my mistake.
There's already a veritable plethora of APIs in this general space, some of which have overlap, some of which are for just one "platform", all of which leave me with something yet to be desired.
I sure wish there was a single solution that does everything I want and maybe even more!
yes, that is an XKCD reference. so sue me?
I'm sending this chunky blog post out into the world in the hopes that maybe someone out there is working on (or has already worked on) something that could help me with my blues, but even if not, I thought it was a good idea to get all my thoughts out and pull all of this into a single spot.
If you've made it through the whole post, thank you! I would love to hear your thoughts, so send them my way by finding me with the username timo on the libera.chat IRC network, or here on the fediverse where I occasionally post interesting things, but mostly just bad jokes and such?
They say that this blog has an RSS feed, which might just be getting en vogue again!
This blog post has been removed because of legal reasons by request of the author.
This is part thirteen in the "Cases of UPPER" series of blog posts, describing the Raku syntax elements that are completely in UPPERCASE.
This part will discuss the various introspection methods that you can use on objects in the Raku Programming Language. Note that in some documentation these methods are also referred to as Metamethods.
In Raku everything is an object, or can be thought of as an object. An object is an instantiation of a class (usually made by calling the new method on it). A class is represented by a so-called "type object". Such a type object in turn is an instantation of a so-called meta class. And these meta classes are themselves built out of more primitive representations.
Going this deep would most definitely be out of scope for these blog posts. But yours truly does intend to go there at some point in the future.
The WHAT method returns the type object of the given invocant. Not much else to tell about it really.
say 42.WHAT; # (Int)
say "foo".WHAT; # (Str)
say now.WHAT; # (Instant)
The HOW method returns the meta-object of the class of the given invocant. The HOW (b)acronym stands for "Higher Order Workings". It allows one to introspect the class of the invocant.
say 42.HOW.name(42); # Int
say "foo".HOW.name("foo"); # Str
say now.HOW.name(now); # Instant
Note that the invocant of the HOW method needs to be repeated in the introspection method's call as the first argument. Why? Well, this is really to be possibly compatible with future versions of Raku.
Since one is usually only interested in the introspection aspect of HOW, a shortcut method invocation was created that allows one to directly call the introspection method without needing to repeat oneself: .^:
say 42.^name; # Int
say "foo".^name; # Str
say now.^name; # Instant
Some other common introspection methods are mro (showing the base classes of the class of the value) and methods (which returns the method objects of the methods that can be called on the value):
say 42.^mro; # ((Int) (Cool) (Any) (Mu))
say 42.^methods.sort; # (ACCEPTS Bool Bridge Capture Complex...
Note that these meta-classes are classes themselves, so can have meta-methods on them called as well:
say 42.HOW.^name; # Perl6::Metamodel::ClassHOW
Yeah, there's still some legacy code that will need renaming under the hood!
The WHERE method returns the memory address of the invocant. It is of limited use in the Rakudo implementation as the memory location of an object is not guaranteed to be constant. As such, it is intended for (core) debugging only.
say 42.WHERE; # 2912024602280 (or some other number)
In the previous blog post the Scalar object was described. But the Scalar objects are nearly invisible. How can one obtain a Scalar object from a given variable? And find out its name from that?
The "secret" to that is the VAR method.
my $a;
say $a.VAR.^name; # Scalar
Each Scalar object provides at least these introspection methods: of, name, default and dynamic.
my Int $a is default(42) = 666;
say $a; # 666
say $a.VAR.of; # (Int)
say $a.VAR.name; # $a
say $a.VAR.default; # 42
say $a.VAR.dynamic; # False
The of method returns the constraint that needs to be fulfilled in order to be able to assign to the variable. The name method returns the name of the variable. The default method returns the default value (Any if none is specified).
The dynamic method returns True or False whether the variable is visible for dynamic variable lookups. This usually only returns True for variables with the * twigil.
The WHO method (for "who lives here?) is actually a bit of a misnomer. It should probably have been called OUR because it returns the Stash of the type object of the invocant. And a stash is an object that does the Associative role, and as such can be accessed as if it were a Hash. And the stash of a type object is the same namespace as our inside that package.
So for instance if you would like to know all classes that live in the IO package:
say IO.WHO.keys.sort; # (ArgFiles CatHandle Handle Notification Path Pipe Socket Spec Special)
Of course, you would know them more by their complete names such as IO::ArgFiles, IO::CatHandle, IO::Handle, etc. In fact the :: delimiter is shortcut for using WHO:
say IO.WHO<Handle>; # (Handle)
say IO::Handle; # (Handle)
And that goes even further: foo:: is just short for foo.WHO:
say IO::.keys.sort; # (ArgFiles CatHandle Handle Notification Path Pipe Socket Spec Special)
A little closer to home: how would that look in a package that you define yourself and have an our scoped variable in there:
package A {
our $foo = 42;
}
say A.WHO<$foo>; # 42
say A::<$foo>; # 42
say $A::foo; # 42
The careful reader will have noticed that
packagewas used in the example. A very simple reason:class,role,grammarare all just packages with differentHOWs. AndWHOdoesn't care why kind ofpackageit is.
The REPR method returns the name of the memory representation of the class of the invocant. For most of the objects this is "P6opaque".
This is basically the representation used by
classand its attribute specifications.
The NativeCall module provides a number or alternate memory representations, such as CStruct, CPointer and Cunion. Native arrays also have a different representation (VMArray).
say 42.REPR; # P6opaque
my int @a;
say @a.REPR; # VMArray
When a class is defined, it gets the P6opaque representation by default.
class Foo { }
say Foo.REPR; # P6opaque
Unless one is doing very deep core-ish work, how an object is represented in memory should not be of concern to you.
The DEFINITE method returns either True or False depending on whether the invocant has a concrete representation. This is almost always the same as calling the defined method. But in some cases it makes more sense in Raku to return the opposite with the defined method.
An example of this is the Failure class:
say Failure.new.DEFINITE; # True
say Failure.new.defined; # False
In general the defined method should be used. The DEFINITE method is intended to be used in very low-level (core) code. It's not all uppercase for nothing!
The reason
Failure.new.definedalways returnsFalseis to make it compatible withwith.
All of the introspection "metamethods" described in this blog post are actually parsed as macros directly generating low-level execution opcodes. This is really necessary in some cases (as otherwise information can be lost), and in other cases it's just for performance.
This doesn't mean that it's not possible to call this introspection functionality as a method: you can. For example:
my $a;
say "macro: " ~ $a.VAR.name; # macro: $a
say "method: " ~ $a."VAR"().name; # method: $a
Furthermore for consistency, the same functionality of these methods is also available as subroutines.
my $b;
say "sub: " ~ VAR($b).name; # sub: $b
So if you're more at home in imperative programming, you can do that as well!
This concludes the thirteenth episode of cases of UPPER language elements in the Raku Programming Language, the sixth episode discussing interface methods.
In this episode the following macro-like introspection methods were discussed (in alphabetical order): DEFINITE, HOW, REPR, VAR, WHAT, WHERE, WHO.
Stay tuned for the next episode!
This is a third follow-up on Raku Resolutions series.
The third meeting was held on 21 February 2026 at 19:00 UTC. Apart from 3 Raku Steering Council members, only 1 other person attended. In the end, 7 issues were discussed within the allotted time (1 hour).
After some discussion, it became clear that this issue basically has gone stale in light of the new raku.org site. Richard Hainsworth will create a new issue, after which this one can be closed.
unit be too late?
After some discussion it was agreed that from a language design point of view, it shouldn't really matter when the unit occurs in the code, as long as there's only one of them. And that the rest of the source would be considered to be part of that scope.
It was agreed that the documentation will describe this future state with the caveat that this is currently not yet the case. Eric Forste agreed to make a PR accordingly, after which the issue can be closed.
The point of being able to specify an EXPORT sub before a unit would be technically correct, but not very useful in practice as an EXPORT sub usually needs to refer to objects/classes that have already been defined in the code (and thus should logically be positioned after the scope).
List
After some discussion it was decided that the current behaviour of returning Nil for List elements beyond the end is correct. And that returning a Failure for negative index values is the most consistent behaviour, especially in light of Array doing that as well. So the issue could be closed.
Consensus was that it would be nice to have all of these math / statistics methods, but that these should live in module land for the foreseeable future. So the issue could be closed.
It was recognized that there are indeed quite a few open issues in Rakudo (although much less than there have been in the past). However, there will always be open issues. And with the current size of the core team, the number of issues will not significantly reduce in the future (with the current rate of new issues coming in).
So it was decided to close the issue as "unresolvable".
.classify
It was decided that the issue has gone a bit stale, and thus ask the OP (Original Poster) whether this should stay open, especially since it was suggested that .classify / .categorize maybe should need an overhaul (at least internally).
die with newline for raising end-user errors?
After explaining the esoteric rule in Perl 5 with regards to die with a message with and without a new line, it was agreed that it would be nice to have such a feature. Especially since at least 2 of the attendees had been using a note $message; exit 1 sequence to achieve just that. Disadvantage to this is that such a sequence can not be caught by a CATCH.
After some discussion, a :no-backtrace named argument to die() was suggested, and that the issue could be closed if a Pull Requst had been created for this. This has since then been implemented in #6076, so the issue was closed.
The next meeting will be held at 7 March 2026 at 19:00 UTC (20:00 CET, 14:00 EST, 11:00 PST, 04:00 JST (22 Jan), 06:00 AEST (22 Jan)), and again at a one hour maximum. If not all of these issues have been resolved, they will be moved to a future meeting.
Since Jitsi is still working out so far, the next one will be held at the same URL: https://meet.jit.si/SpecificRosesEstablishAllegedly. The reason Jitsi was selected, is that it has proven to be working with minimal hassle for at least the Raku Steering Council meetings. As the only thing you need to be able to attend, is a modern browser, a camera, and a microphone. No further installation required.
A new set of issues has been selected by yours truly (in issue number order, oldest first):
rw parameterRat and fail on lossy coercion)without allow chaining?.raku should be replaced with a pluggable systemAny Raku Community member is welcome to these meetings. Do you consider yourself a Raku Community member? You're welcome. It's as simple as that.
But please make sure you have looked at the issues that will be discussed before attending the meeting. And if you already have any comments to make on these issues, make them with the issue beforehand.
The original contributors to these issues will also be notified (unless they muted themselves from these issues). We hope that they also will be able to attend.
If you consider yourself a Raku Community member, please try to attend! If anything, it will allow you to put faces to the names that you may be familiar with.
Hope to see you there!
This is part twelve in the "Cases of UPPER" series of blog posts, describing the Raku syntax elements that are completely in UPPERCASE.
This part will discuss the various aspects of containers in the Raku Programming Language.
This may come as a shock to some, but Raku really only knows about binding (:=) values. Assignment is syntactic sugar.
What?
Most of the scalar variables that you see in Raku, are really objects that have an attribute to which the value is bound when you assign to the variable. These objects are called Scalar containers, or just short "containers".
In short: assignment in Raku is binding to an attribute in a
Scalarobject. Grokking how containers work in Raku (as opposed to many other programming languages) is one of the rites of passage to becoming an experienced and efficient developer in Raku. It sure was a rite of passage for yours truly!
In a simplified representation (almost pseudocode) one can think of these Scalar objects like this:
class Scalar {
has $!value;
method STORE($new-value) {
$!value := $new-value
}
method FETCH() {
$!value
}
}
And an assignment such as:
my $a;
$a = 42;
can be thought of as:
my $a := Scalar.new;
$a.STORE(42);
and showing the value of a variable (as in say $a), can be thought of as:
say $a.FETCH;
In reality it's of course slightly more complicated, because there are such things as type constraints that can exist on a variable (such as my Int $a). And variables may have a default value (as in my $a is default(42)).
This type of information is kept in a so-called "container descriptor", which is considered to be an implementation detail (as in: don't depend on its functionality directly, the interface to it might change at any time).
Many shortcuts are made in implementing this, in the interest of performance. Because assignments are one of the very basic operations in a programming language. And you want those to be fast!
As a mental model, this is very useful for understanding quite a few constructs in Raku.
In Raku any value returned at the end of a block (or with the return statement) are de-containerized by default. This means that something like this:
my $a = 42;
sub foo() { $a }
foo() = 666; # Cannot modify an immutable Int (42)
will not work. What if you could return the container from a block? Then you could just assign to it! There are indeed two easy ways to return something with the container intact: the is rw trait:
my $a = 42;
sub foo() is rw { $a }
foo() = 666;
say $a; # 666
Alternately, one can use the return-rw statement.
my $a = 42;
sub foo() { return-rw $a }
foo() = 666;
say $a; # 666
This feature is for instance used if you want to assign to an array element. In part 9 of this series it was shown that the AT-POS method is what is being called by postcircumfix [ ]. In the core, both the postcircumfix [ ] operator as well as the underlying AT-POS method have this trait set for performance (as the return-rw statement has slightly more overhead).
If an array is initialized with values, it will create containers for each element and put the right value in the right place. So you cannot only fetch the values from there, but you can also assign to these containers. And it is also possible to bind such a container to another variable.
Binding to containers allows for features in Raku that are considered "magic" by some, and maybe "too magic" by others. They are part of common idioms in the Raku Programming Language.
For instance: incrementing all values in an array:
my @a = 1,2,3,4,5;
$_++ for @a;
say @a; # [2 3 4 5 6]
The topic variable $_ binds to the elements of the array in a for loop. So in each iteration it actually represents the container at that location and can thus be incremented.
People coming from other languages may think that
$_is a "reference" (or "pointer") to the actual memory location of the element in the array. This notion is incorrect in Raku. The topic variable$_is bound to the container of each element. The container object itself is completely agnostic as to where it lives. It's just a simple object that knows how toFETCHandSTORE.
Slices to arrays also return containers. For instance to increment only the first and last element in an array without knowing its size:
my @a = 1,2,3,4,5;
$_++ for @a[0, *-1];
say @a; # [2 2 3 4 6]
The slice [0, *-1] produces 2 containers (one for the first element (0) and one for the last (*-1). Only these containers get incremented, thus giving the expected result.
The same logic applies to the values in hashes.
my %h = a => 42, b => 666;
$_++ for %h.values;
say %h; # {a => 43, b => 667}
But binding containers can also be done directly in your code. A contrived example:
my $a = 42;
my $b := $a;
$b = 666;
say $a; # 666
Note that by assigning to $b, you're assiging to the container that lives in $a. Because the binding of $b to $a effectively aliased the container in $a.
In Raku it is possible to assign to elements in an array that do not exist yet.
my @a;
@a[3] = 42;
say @a; # [(Any) (Any) (Any) 42]
So there's no container yet the element at index 3. Yet it is possible to assign to it! How does that work?
The secret is really in the "container descriptor". So let's refine our pseudocode representation of the Scalar class:
class Scalar {
has $!descriptor;
has $!value;
method STORE($value) {
$!value := $!descriptor.process($value);
}
method FETCH() {
$!value
}
}
Note that storing a value has now become a little more complicated ($!descriptor.process($value) rather than just $!value). So the descriptor object's process method takes the value, does what it needs to do with it, and then returns it so that it can be bound to the attribute.
This descriptor object is typically responsible for remembering the name of the variable, the default type, perform type checking and keep a default value of a container. And any additional logic that is needed.
There are many different types of container descriptor classes in the Rakudo implementation, all starting with the
ContainerDescriptor::name. And all are considered to be implementation detail.
For instance, when an AT-POS method is called on a non-existing element in an array, a container with a special type of descriptor is created that "knows" to which Array it belongs, and at which index it should be stored. The same is true for the descriptor of the container returned by AT-KEY (as seen in part 10) which knows in which Hash it should store when assigned to, and what key should be used.
It's this special behaviour that allows arrays and hashes to really just DWIM.
These special descriptors of containers for arrays and hashes also introduce an action-at-a-distance feature that you may or may not like.
my @a;
my $b := @a[3];
say @a; # []
$b = 42;
say @a; # [(Any) (Any) (Any) 42]
Note that the element in the array was not initialized after the binding, but only after a value was assigned to $b. This behaviour was specifically implemented this way to prevent accidental auto-vivification. For example:
my %h;
say %h<a><b>:exists; # False
say %h; # {}
%h<a><b> = 42;
say %h; # {a => {b => 42}}
So even though %h<a> is considered to be an Associative because of the <b>, the :exists test will not create a Hash in %h<a>. Only after a value has been assigned does %h<a> and %h<a><b> actually spring to life.
This rather lengthy introduction / diversion was to make you aware of some of the underlying mechanics of containers. Because Raku supplies a full customizable class that allows you to create your own container logic: Proxy. And understanding what containers are about is helpful when working with that class.
Creation of such a container is quite easy: all you need to supply are a method for fetching the value, and a method for storing a value (very similar to the pseudocode representation at the start of this blog post). This is done with the named arguments FETCH and STORE. Creation of a Proxy object is usually done inside a subroutine for convenience. A contrived example:
sub answer is rw {
my $value = 42;
Proxy.new(
FETCH => method () {
$value
},
STORE => method ($new) {
say "storing $new";
$value = $new;
}
)
}
my $a := answer;
say $a; # 42
$a = 666; # storing 666
say $a; # 666
The careful reader will have noticed that the is rw attribute needs to be specified on the subroutine, otherwise the Proxy would be de-containerized on return. And that the result of calling the answer subroutine was bound (:=) instead of assigned, because assignment would also cause de-containerization and thus completely defeat the purpose of this exercise.
Because the code in the supplied methods closes over the lexical variable $value, that variable stays alive until the Proxy object is destroyed. So it offers an easy way to actually store the value for this Proxy object.
Inside the supplied methods you are completely free to put whatever code that you want. As an example how that could work in a module, the Hash::MutableKeys distribution was created. Another case of BDD (Blog Driven Development)!
You may have observed that the
Proxyobject does not allow for a descriptor. It was not considered to be needed, as you have all the flexibility you could possibly want. If you want one in yourProxyobjects, you can create one yourself.
This concludes the twelfth episode of cases of UPPER language elements in the Raku Programming Language, the fifth episode discussing interface methods.
In this episode containers were described, as well as the special Proxy class with its named arguments STORE and FETCH. This Proxy class provides a fully customizable container implementation.
Stay tuned for the next episode!
We needed a legal document with numbered Articles, and the document needed to be in MarkDown for github issues, and in html, so naturally the source should be in RakuDoc.
Although numbered headings and items were specified in RakuDoc v1 (aka POD6), they were never implemented. In RakuDoc v2 there was progress, and together with some tweaking of the numitem templates, it was easy to write the RakuDoc source.
However, when we were revising RakuDoc, Damian Conway had some extra ideas about generalising enumeration, including ideas about adding alias definitions so that the numbered block could be referenced later in the text.
Since it had been so easy to tweak the numitem templates, I thought it would be easy upgrade the specification of RakuDoc v2 to get these generalisations. Was I ever so wrong!!!! Ask a genius with decades of language design experience for a nice design and you get an effusion of ideas and extensions that make RakuDoc better than any editor I have ever used, but with a simplicity that makes it easy for a document author to understand.
Another result of the redesign is to make the underlying specification of RakuDoc much clearer, something I will cover later.
During the development process, my daughter mentioned that her friend had just finished a PhD dissertation and was complaining about how much time she needed to spend reformatting the text because the numbering kept getting out of sync. The problem with most editors is that most of the effort goes on perfecting the user-facing interface, while the underlying format is created ad hoc, and enumeration is an addition. Getting the underlying structure right will make subsequent rendering easier.
Just as the design was ending and the renderer passing most tests, I casually mentioned citations would be a good extension. The "standards" for citations number in the thousands! .oO(The Jabberwocky ) But Damian snicker-snacked his vorpal blade, reducing the monstrous tangle to something easier to use. RakuDoc v2 now has a =citation block and Q<> markup to insert quoted citations. I will cover these additions in the next blog (as in: when I get the renderer to work with the new ideas).
Back to enumerating RakuDoc, here are some examples to illustrate the new functionality.
Suppose you have a formula (or code or map or table or item in a list) and you want to number it, and then reference the number in the text? Then another formula gets added into the text before, well you would want the references to update as well.
Suppose you have tables that you want to be enumerated separately from headings? But also by preference you want them to be enumerated in sequence with headings? That is the prefix to the table enumeration is the heading number.
Suppose you want Chinese, Roman, or Bengali numbering?
AND suppose you also want the numbering to be a mix of numerals and other characters, such as brackets? This is a common requirement in legal documents.
Suppose you want Arbitrary words before after or in between the numbers? For example, Article 1., Article 2. etc.
Suppose you want to have the paragraphs numbered? Sometimes you might want the paragraphs numbered in sequence from the start of the document, and sometimes you want the numbering to restart after a new heading.
Suppose you want to have the Tables and the Formulae numbered in sequence? Or perhaps, for a section that explains some aspect of one formula, you want to number the formulae separately, but then return to the original sequence after that section?
The updated RakuDoc v2 allows for all of these possibilities, while also providing for sensible default option values.
Moreover, RakuDoc allows for custom blocks, eg. LeafletMap - a map block that exposes the marvelous Leaflet library. Now it is an automatic part of the specification that prefixing a custom block with num (numLeafletMap) will number the caption of the block.
An HTML rendering of the new RakuDoc v2 specification containing the enumerated functionality can be found at RakuDoc enumeration branch
In the specification of RakuDoc, there are discussions about directives, blocks, metaoptions, and a section on =config.
Since the syntax for a directive is almost the same as the syntax of a block, it is not immediately apparent what the difference is. As we developed the generic enumeration, it became much clearer what the difference is.
Furthermore, the older specification covered multi-level headings and items. This functionality is now extended to all blocks, so =numtable2 or =numcode3 will be numbered in parts from the previous instance of =table (the equivalent of table1) or =code. This means that we need to carefully distinguish between the block base (eg., table or code), and the block level (eg., 1, 2, 3). Together the base and the level create a blocktype. These distinctions, although implied, were not so clear in the older specification.
Let's return to the =config directive. The first parameter of =config is the name of a blocktype. Note that the num prefix is not a part of the blocktype and only indicates that the enumeration associated with the instance needs to be rendered. Consequently, the presence or absence of 'num' in the config parameter has no significance. The next =config parameters are all, and may only be, metadata options.
The function of the =config directive is to distribute the named metadata options, and their values, to the named blocktype. In addition, the same metadata option can be specified on a blocktype instance (using either the =for or =begin directives), in which case it takes precedence over the option in the config. A consequence of this paradigm is that each metadata option has to have a semantic significance in the context of a blocktype instance.
One of the design aims was to give a document author the choice of restarting the enumeration for some blocktype when another blocktype is encountered. For example, the original specfication for =numitem included the idea that whenever a sequence of =numitems was encountered, they would form an ordered set, and that if another block, such as a paragraph, was encountered, the enumeration would be restarted.
This means that the occurrence of a =head restarts the item counter. This cannot be controlled within the handler of a block. Consequently, any option affecting block counting needs to be distinct from the rendering of the blocks themselves.
After some design iterations, a new directive called =counter was introduced. A directive, as opposed to a block, affects all subsequent blocks in the RakuDoc source, within the same scope. A block, and the metadata options operating on the blocktype, only affects its immediate contents.
Further, it became clear that a block and its counter were different objects, although for simplicity they have the same name. For most needs, an author does not need to know that a counter and a block are different, except that when a new counter is needed, the difference becomes necessary. In a similar way, for many purposes it doesn't matter whether a number is an integer or a string, except when it does. Raku allows for things to become complicated when the author needs it to be.
To make it easier to experiment with RakuDoc and the enumerated functionality, I have developed a Docker image called browser-editor. It is based on an Alpine image and contains raku, Cro, and the latest version of Rakuast::RakuDoc::Render (currently not yet in the fez system).
Using podman, the image can be put into a container and run locally on Linux based systems, thus:
podman pull docker.io/finanalyst/browser-editor:latest
podman run -d -v .:/browser/publication --rm -name rb docker.io/finanalyst/browser-editor:latest
For Mac silicon, a small change is needed to indicate the platform inside the docker image is based on Linux, thus:
podman run -d -v .:/browser/publication --rm --platform linux/amd64 --name rb docker.io/finanalyst/browser-editor:latest
In both cases the container is given the arbitrary name rb, and so when it is time to stop the container, the following is sufficient:
podman stop rb
The directory that the container is started from will then linked to the container's /browser/publication directory, and changes and new RakuDoc source files will be saved in that directory.
A RakuDoc source can then be edited and the HTML rendering is created on the fly, by pointing a browser at (setting the browser URL to) localhost:3000.
You should see something like the following in the browser:

Two frameworks exist: one needing no internet connection - a minimal single file rendering, and another that uses plugins to expose some useful third-party libraries and the more sophisticated Bulma CSS framework. The choice is toggled using the 'online' button.
Try selecting 'online' and copying in the following test source by Damian Conway to see some different effects.
=begin rakudoc
=TITLE Taster source
=numitem One
=numitem Two
=counter item :restart(42)
=numitem Three
=counter item :restart
=numitem Four
=counter item :prefix<head3>
=numitem Five
=counter item :!restart
=para ???
=numitem Six
=numpara
S<Now is the winter of our "no content"
Made glorious summer by Camelia’s bloom;
And all backlog that lour’d upon our docs
In deep commits is buried, link’d, and tagged.
Our nightly builds now wear triumphant green,
Our failing tests to passing smiles are turn’d;
Grim sighs of “ere next Yule” have chang’d to grins,
And hacker dread to blog posts boldly strung.>
=numpara
S<But I—long nurs’d on RFCs and hope,
Deform’d by specs that shifted as I read,
Unfit for idle scripts or stable sleep—
Am set, since long delays are now no more,
To ship Raku...and break the world anew.>
=numcode
$x = any <1 2 3>;
=for numcode :caption<Same thing, just labelled>
$x = any <1 2 3>;
=for numformula :caption<This means nothing!>
x^2 = y_j + \sum z_i
=for numformula :caption<This means nothing!> :alt< xH<2> = yJ<1> + E<GREEK CAPITAL LETTER SIGMA> zJ<i> >
x^2 = y_j + \sum z_i
=for numformula :alt< (1+x)H<n> = E<GREEK CAPITAL LETTER SIGMA> H<n>CJ<i> xH<i> > :caption<This is actually right>
(1+x)^n = \sum_{i=0}^n {n \choose i} x^i
=for numinput
Hey type something:
=numoutput
You typed: hsdkhldkhskdhasd
=counter numtable :restart(33456)
=begin numtable :caption<Encryption table> :form<Example %R: %C:pc>
=row
=cell A
=cell B
=cell C
=row
=cell D
=cell E
=cell F
=end numtable
=end rakudoc
This should look like the following (or at least the top part).

The example shows some features like numbering paragraphs, code examples and tables. But you will also see the difference between the two rendering contexts. The online version has access to an online latex rendering resource, so the formula are nicely rendered, whilst the off-line version only renders to the raw formula or a character-based alternative - if provided.
Suppose we want to enumerate a code sample and then refer to it later, we can do the following:
=begin rakudoc :!toc
=TITLE Enumerations
=for numcode :numalias<SAY_EX> :lang<raku>
my %h = <one two three> Z=> ^3;
say %h;
=numoutput {one => 0, three => 2, two => 1}
=for numcode :numalias<PUT_EX> :lang<raku>
my %h = <one two three> Z=> ^3;
put %h;
=for numoutput
one 0
three 2
two 1
The difference between A<SAY_EX> and A<PUT_EX> is that C<say> and C<put> use different methods to convert the C<%h> structure into printable strings.
=end rakudoc
In the browser-editor image, we will get an HTML rendering something like:

The
=begin rakudoc :!tocand=end rakudocare used to top and tail the RakuDoc example above because the HTML renderer expects a complete Raku program, and a RakuDoc source (currently) needs the RakuDoc to be within a=rakudocblock. The:!tocswitches off the automatic Table of Contents that the HTML utility of theRakuast::RakuDoc::Renderdistribution generates. (Try removing:!toc)
Suppose we want out tables to have enumerations that align with the enumerations of the headings. So this means we are requiring a different sort of behaviour from the counter associated with the table block base. Consequently, we need to use the =counter directive. Also note that we are prefixing with the head2 block, which has an implicit prefix of head1.
=begin rakudoc :!toc
=TITLE Prefixes
=counter table :prefix<head>
=numhead First title
=numhead2 Sub first title
=for numtable :caption<First table>
| one | two |
=for numtable :caption<Second table>
| three | four |
=numhead Second Title
=counter table :restart(6)
=for numtable :caption<Third table>
| five | six | seven | eight |
=for numtable2 :caption<Subordinate table>
| nine | ten |
| nine | ten |
=end rakudoc
Comments:
table counter to 6 before Third table. 
To illustrate the multi-lingual ability of RakuDoc (and Raku in general), lets use Chinese, Roman and Bengali for multilevel headings.
=begin rakudoc :!toc
=TITLE Some non-Arabic numerals
=config head :form< %Z %D >
=config head2 :form< 「%Z」%R %D >
=config head3 :form< 「%Z」%R「%B」 %D >
=numhead First title
=numhead Second title
=numhead3 Sub-sub-head one (implies the sub-head)
=numhead3 Sub-sub-head two
=numhead2 Sub-head first explicit
=numhead2 Sub-head second explicit
=for numformula2 :form<%T %Z.%R. >
\begin{align*}
\sum_{i=1}^{k+1} i^{3}
&= \biggl(\sum_{i=1}^{n} i^{3}\biggr) + i^3\\
&= \frac{k^{2}(k+1)^{2}}{4} + (k+1)^3 \\
\end{align*}
=end rakudoc
This will produce an HTML rendering a bit like

The :numform option is very flexible and in fact the brackets in the previous example are arbitrary text. The following RakuDoc source
=begin rakudoc :!toc
=TITLE Arbitrary text in enumeration
=config head :form< Article %N. %D >
=config head2 :form< Article %N.%r. %D >
=config head3 :form< Article %N.%r「%Z」 %D >
=numhead First title
=numhead Second title
=numhead3 Sub-sub-head one (implies the sub-head)
=numhead3 Sub-sub-head two
=numhead2 Sub-head first explicit
=numhead2 Sub-head second explicit
=end rakudoc
will produce something like:

In RakuDoc, paragraphs as in all text editors, are strings of text ending in a blank line or a new block (for RakuDoc). There is no need to mark a paragraph block, but it will be equivalent to a block marked =para.
By default, each paragraph is numbered from the start of the document. In order to see the enumeration, the paragraph does need to be started with a =numpara.
For this example, we want to number paragraphs in each section marked with a heading. So we need to tell the counter which conditions it is restarted by; in this case after every =head (by default a bare block name has a level of 1). There are both :restart-after and :restart-except-after conditions, but that's all we'll say about them here.
The RakuDoc source is
=begin rakudoc :!toc
=TITLE Restarting after headings
=counter para :restart-after<head>
=head First heading
=numpara First line
=numpara Second line
=numpara Third line
=head Second heading
=numpara First line 2
=numpara Second line 2
=head2 Subordinate heading does not restart the paragraphs
=numpara Third line 2
=numpara Fourth para
=end rakudoc
The source will yield something like:

We want to number code and formulae using the same counter, but also we want to explain some formula with a special numbering that is then forgotten.
Since all =config and =counter statements are scoped, all we need to do to get the special numbering is to create a =section, which introduces a new block scope. The previous config/counter options continue, unless explicitly overridden.
However, it would not be useful if upon exiting a section, the numbering of a counter reverts to the value before the section. So there is a subtle distinction between the counter and the value of the count it contains. The counter options, such as its prefix, and when it is restarted, are scoped, but the value of the counter is not scoped. In order to reset the counter value, the counter has to be reset.
RakuDoc v2 clarified the idea of custom blocks. Previously it was implied that developers could have their own blocks, but in V.2 the difference between built in and custom blocks was clarified: custom blocks must contain a mix of upper and lower case letters (more precisely characters with the Unicode properties Lu and Ll).
The enumeration options use this idea by creating custom counters. Since this is something that managed by a block, the :counter option is provided to the appropriate blocks using a =config directive.
=begin rakudoc :!toc
=TITLE Using custom counnters
=config formula :counter< FormulaeTables >
=config table :counter< FormulaeTables >
=numhead First title
=numtable
| one | two | three |
=numtable
| more | tabula data |
| 5 | 6 |
| 7 | 8 |
=numformula E = mc^2
=numformula e^{\pi i} = -1
=begin section
=config table :counter< Derivation > :form<Aside: %T %N>
=numhead2 Some explanation
=numtable
| this | data | is | more | detailed |
| 1 | 2 | 3 | 4 | 5 |
=end section
=numhead Continuing
=numtable
| here | we | resume |
=end rakudoc
This will produce something like

We have only just completed the revised specification, and the Renderer has only just been developed. It is inevitable that there will be flaws, and the styling choices may not be liked by everyone.
Even so, we think this new upgrade of RakuDoc v2 will prove to have a much wider applicability than just a documentation aid to Raku programs.
The docker image allows anyone to experiment with the new RakuDoc functionality immediately without needing to install the whole Raku / Cro / Rakuast::RakuDoc::Render stack and some dependencies, such as Dart Sass, locally.
How time flies. Yet another year has flown by.
Let’s first start with the technical stuff, as nerds do!
Rakudo saw about 1650 commits (MoarVM, NQP, Rakudo, doc) this year, which is about 20% less than 2024. All of these repositories now have “main” as their default branch (rather than “master”).
About 58% of the Rakudo commits were in the development of RakuAST (up from 33% in 2024), of which more than 95% were done by Stefan Seifert. This work, that was supported by a TPRF grant, resulted in being able to build the part of Rakudo that’s written in Raku using RakuAST (often referred to as the “bootstrap“).
However there are still quite a few issues that need to be fixed before RakuAST-based Rakudo can be made the default. And thus be ready for the next language level release. Still, an amazing amount of work done by Stefan Seifert, so kudos!
Geoffrey Broadwell has done a major update of the internal MoarVM Unicode tools. Based on that work Shimmerfairy developed an update of the MoarVM Unicode support from 15.0 to 17.0. This includes support for some new emojis such as FINGERPRINT  , SPLATTER
, SPLATTER  , HARP
, HARP  . This means that all of the changes of Unicode 16 and Unicode 17 were implemented to a very high degree. Quite a feat!
. This means that all of the changes of Unicode 16 and Unicode 17 were implemented to a very high degree. Quite a feat!
Patrick Böker was really busy this year: new script runners not only made execution of CLI-scripts a bit faster, it also made it possible to run CLI-scripts on Windows without any issues.
Again, a lot of work was done on making the Continuous Integration testing produce fewer (and recently hardly any) false positives anymore. Which makes life for core developers a lot easier!
Very important for packagers: Rakudo now again has a reproducible build process, thanks for Timo Paulssen and others.
Also the REPL (Read, Evaluate, Print Loop) has been improved: grammar changes are now persistent, and it’s also possible to enter multi-line comments. Some of these changes were backported from the REPL module, as described in this blog post.
The tests for experimental Raku features (such as :pack, :cached, :macros) have been moved from the Raku test-suite (roast) to the Rakudo repository, as they are technically not part of the definition of the Raku Programming Language.
Sadly, the JVM backend has hardly seen any updates the past year. It was therefore decided to not mention the JVM backend in releases anymore, nor to make sure that there would not be any ecosystem breakage on the JVM backend before a release.
If you want the JVM to remain a viable backend, you are very much invited to get involved!
The most notable new features in the default language level:
NativeCallAfter many years of people asking for this feature, Patrick Böker actually wrote the infrastructure in MoarVM and Rakudo to support calling C-functions that support a variable number of arguments using the va_arg standard.
To give an example, it’s now possible to create a foo subroutine that will call the printf C-function (from the standard library) that takes a format string as the first argument, and a variable number of arguments after that:
use NativeCall;
sub foo(str, **@ --> int32) is native is symbol('printf') {*}
foo "The answer: %d\n", 42; # The answer: 42The printf() C-function is a good example of using varargs.
Writing terminal applications has become much simpler with the support for pseudo-terminals that Patrick Böker has written. This Advent post explains the how and why of this development, and the new Anolis terminal emulator module.
Support is still a bit raw around the edges: pretty sure the coming year will see a lot of smoothing over, so that it can e.g. be used to create a full featured terminal-based Raku debugger!
Hash.new(a => 42, b => 666)A common beginner mistake was trying to create a new Hash (or Map) object by using .new and named arguments. This would silently create an empty Hash (or Map) because by default any unexpected named arguments are ignored in calls to .new. This was changed so that if Hash.new (or Map.new) is called with named arguments only, they will be interpreted as key/value pairs to be put into the Hash (or Map):
dd Hash.new(a => 42, b => 666);
# {:a(42), :b(666)}
dd Map.new(a => 42, b => 666);
# Map.new((:a(42),:b(666)))The Test module now also provides an exit-ok tester subroutine, making it a lot easier to test the exit behaviour of a piece of code. It takes a Callable, and an integer value. It expects the code to execute an exit statement, and will then compare the (implicitly) given exit value with the given integer value.
use Test;
exit-ok { exit 1 }, 1;
# ok 1 - Was the exit code 1?
exit-ok { exit }, 1;
# not ok 2 - Was the exit code 1?
exit-ok { 42 }, 0;
# not ok 3 - Code did not exit, no exit value to checkThe most notable additions to the future language level of the Raku Programming Language:
An implementation of ordered hashes (a hash in which the order of the keys is determined by order of addition) has become available:
use v6.e.PREVIEW;
my %h is Hash::Ordered = "a".."e" Z=> 1..5;
say %h.keys; # [a b c d e]
say %h.values; # (1 2 3 4 5)This will probably get some easier syntactic sugar. Until then, the above syntax can be used.
The following changes are only seen when using RakuAST (by calling raku with the RAKUDO_RAKUAST=1 environment variable set), and thus available by default when the next language level is released.
The RAKU_LANGUAGE_VERSION environment variable can be used to indicate the default language level with which to compile any Raku source code. Note that this does not affect any explicit language versions specified in the code.
$ RAKUDO_RAKUAST=1 RAKU_LANGUAGE_VERSION=6.e.PREVIEW raku -e 'say nano'
1766430145418821670
$ RAKUDO_RAKUAST=1 RAKU_LANGUAGE_VERSION=6.e.PREVIEW raku -e 'use v6.d; say nano'
===SORRY!=== Error while compiling -e
Undeclared routine:
nano used at line 1Although of limited use while RakuAST is not yet the default, it will make it a lot easier to check the behaviour of code at different language levels, e.g. when running tests in the official test-suite (aka roast).
$?SOURCE, $?CHECKSUMThe compile-time variables $?SOURCE and $?CHECKSUM have been added. The $?SOURCE compile-time variable contains the source of the current compilation unit. If for some reason one doesn’t want that to be included in the bytecode, then the RAKUDO_OMIT_SOURCE environment variable can be set.
The $?CHECKSUM compile-time variable contains a SHA1 digest of the source code.
$ RAKUDO_RAKUAST=1 raku -e 'say $?SOURCE'
say $?SOURCE
$ RAKUDO_RAKUAST=1 raku -e 'say $?CHECKSUM'
81892BA38B9BD6930380BD81DB948E4D7A9C14E7
$ RAKUDO_RAKUAST=1 RAKUDO_OMIT_SOURCE=1 raku -e 'say $?SOURCE'
NilThese additions are intended to be used by the MoarVM runtime debugger, as well as by packagers for verification.
Most of the localization work has been removed from the Rakudo core and put into separate Raku-L10N project. And there it gained a few new contributors! For a progress report, checkout out habere-et-dipertire‘s advent blog post titled Hallo, Wêreld!
To make it easier to work with code in a specific localization, each localization comes with a “fun” command line script, and an official one. So for instance, the Dutch localization has a “dutku” (for dutch raku) executable (well, actually a CLI script), but also a “kaas” one. Same for French (“freku” and “brie”), etc. The fun one is usually associated with a favourite foodstuff of the language in question.
$ dutku -e 'zeg "foo"'
foo
$ kaas -e 'zeg "foo"'
foo
$ freku -e 'dis "foo"'
foo
$ brie -e 'dis "foo"'
fooThe RakuDoc v2.0 specification was completed in December 2024, and 2025 was spent implementing it. A compliant renderer is now available by installing the Rakuast::RakuDoc::Render distribution. Work then began on a document management system called Elucid8 which renders the whole Raku documentation (development preview).
From September onwards, Damian Conway and Richard Hainsworth worked on a enumeration system (originally envisioned for RakuDoc v3.0) so that any block – meaning any paragraph, heading, code snippet, formula, etc – can be enumerated simply by prefixing the blocktype with num. It is a far more flexible system than anything encountered in the editor space.
The RakuDoc specification is now at version 2.20.2. The new enumeration specification has not yet been merged to main because work is still being done on getting Rakuast::RakuDoc::Render to implement the new standard.
It really looks like RakuDoc has the potential to becoming the markup language for any type of serious documentation, and a direct competitor to markdown.
The Raku ecosystem has seen quite a lot of developments. Many modules got moved to the Raku Community Modules Adoption Center where they got a new lease on life. But there were also quite a few new modules, and interesting updates to existing modules in 2025.
According to raku.land in 2025, 503 Raku modules have been updated (or first released): up from 367 in 2024 (an increase of 37%). There are now 2431 different modules installable by zef by just mentioning their name. And there are now 13808 different versions of Raku modules available from the Raku Ecosystem Archive, up from 12181 in 2024, which means more than 4.4 module updates / day on average in 2025 (up from 3.9 updates / day).
The modules that yours truly found interesting, so a very personal list! In alphabetical order:
Also in alphabetical order:
A new experimental bot has appeared on the #raku-dev IRC channel: rakkable. It is basically an interactive front end for the new “rakudo-xxx” features of App::Rak. Which in turn is based on the new Ecosystem::Cache module. This allows easy searching in all most current versions of modules in the ecosystem.
For instance: look in the Raku ecosystem for code mentioned in “provides” sections that contain the string “Lock.new” and which also have the string “$!lock”:
<lizmat> rakkable: eco-provides Lock.new --and=$!lock
<rakkable> Running: eco-provides Lock.new --and=$!lock, please be patient!
<rakkable> Found 30 lines in 25 files (24 distributions):
<rakkable> https://gist.github.com/fa2424aebf085ea656b436c63722bf9dThe bot currently only lives on the #raku-dev, but can also be accessed directly without needing the “rakkable:” prefix.
Yes, there’s also non-technical stuff in the Raku world!
The raku.org website has been completely renewed, thanks to Steve Roe who has taken that on. It’s now completely dogfooded: hypered with htmx. Aloft on Åir. Constructed in cro. Written in raku. & Styled by picocss.
The Raku Documentation Project has gained quite a few collaborators, who are working on making the Raku documentation more accessible to new users. One factor making this easier, is that the CI testing for the documentation has become about 4x as fast by using RakuAST RakuDoc parsing.
Yours truly stopped using what is now X (formerly Twitter). It hurt. But Bluesky and Mastodon are good alternatives, and the people important to yours truly have moved to them. If you haven’t yet, you probably should. As well as the people important to you.
Please be sure to mention the #rakulang tag when posting about the Raku Programming Language!
Sadly it has turned out to be impossible to organize a Raku Conference (neither in-person or online) this year. Hoping for better times next year! It just really depends on people wanting to put in the effort!
It was possible to organize a second Raku Core Summit in 2025!
The Rakudo Weekly News has been brought to you by Steve Roe in the 2nd half of 2025 (and for the foreseeable future). With some new features, such as code gists! Kudos!
The Problem Solving repository has seen an influx of 36 new issues the past year. They all deserve your attention and your feedback! Some of them specifically ask for your ideas, such as:
Please, don’t be shy and have your voice heard!
Sadly, Vadim Belman and Stefan Seifert have indicated that they wanted to step down from the Raku Steering Council. They are thanked for all that they have done for Raku, the Raku Community in general, and the Raku Steering Council in particular.
John Haltiwanger has accepted an invitation to join the Raku Steering Council. The seat opened by Stefan Seifert will not be filled for at least the coming 6 months.
After writing a blog post about a Raku Foundation, a problem solving issue and many discussions at the second Raku Core Summit, there finally is a version of the Raku Foundation Documents that everybody can agree on (at least for now).
Yours truly urges the readers to check out The Articles Of Association, as these will be very hard to change once the foundation is established.
If you are really interested in this kind of stuff, please check out the Regulations for the operation of the Raku Foundation as well.
And if you would like to become part of the initial Executive Board or the Supervisory Board, please send an email to [email protected].
Looking back, again an amazing amount of work has been done in 2025! And not only on the technical side of things!
Hopefully you will all be able to enjoy the Holiday Season with sufficient R&R. Especially Kane Valentine (aka kawaii) who is still going strong in their new role:

And on that note: Слава Україні! Героям слава!
The next Raku Advent Blog is only 340 days away!
This document (notebook) describes three ways of making mazes (or labyrinths) using graphs. The first two are based on rectangular grids; the third on a hexagonal grid.
All computational graph features discussed here are provided by “Graph”, [AAp1]. The package used for the construction of the third, hexagonal graph is “Math::Nearest”, [AAp2].
Just see the maze pictures below. (And try to solve the mazes.)
The first maze is made by a simple procedure which is actually some sort of cheating:
The second maze is made “properly”:
The third maze is again made “properly” using the procedure above with two modifications:
Here are the packages loaded for use in the rest of the notebook:
use Graph;
use Graph::Classes;
use Math::DistanceFunctions;
use Math::Nearest;
use Data::TypeSystem;
use Data::Translators;
use Data::Generators;
This sub is used to invoke the Graphviz graph layout engines:
sub dot-svg($input, Str:D :$engine = 'dot', Str:D :$format = 'svg') {
my $temp-file = $*TMPDIR.child("temp-graph.dot");
$temp-file.spurt: $input;
my $svg-output = run($engine, $temp-file, "-T$format", :out).out.slurp-rest;
unlink $temp-file;
return $svg-output;
}
In this section, we create a simple, “cheating” maze.
Remark: The steps are easy to follow, given the procedure outlined in the introduction.
# Maze dimensions
my ($n, $m) = (10, 25);
# Base grid graph
my $g = Graph::Grid.new($n, $m, :!directed);
# Using the edges of the grid graph make a new graph assigned random edge weights
my $gWeighted = Graph.new($g.edges(:dataset).map({ $_<weight> = random-real([10,1000]); $_}))
# Graph(vertexes => 250, edges => 465, directed => False)
Find the spanning tree of the graph:
my $mazePath = $gWeighted.find-spanning-tree
# Graph(vertexes => 250, edges => 249, directed => False)
Shortest path from the first vertex (bottom-left) to the last vertex (top-right):
my @path = $mazePath.find-shortest-path('0_0', "{$n-1}_{$m-1}");
@path.elems
# 56
Graph plot:
#% html
my $simpleMaze = Graph.new($mazePath.edges);
$simpleMaze.vertex-coordinates = $g.vertex-coordinates;
my %opts =
background => "Black",
:!node-labels,
:!edge-lables,
node-shape => 'square',
node-width => 0.7,
node-color => 'SteelBlue',
node-fill-color => 'SteelBlue',
edge-thickness => 52,
edge-color => 'SteelBlue',
size => '10,6!',
engine => 'neato';
$simpleMaze.dot(|%opts):svg

The “maze” above looks like a maze because the vertices and edges are rectangular with matching sizes, and they are thicker than the spaces between them. In other words, we are cheating.
To make that cheating construction clearer, let us plot the shortest path from the bottom left to the top right and color the edges in pink (salmon) and the vertices in red:
#%html
my $gPath = Graph::Path.new(@path);
$simpleMaze.dot(highlight => {Salmon => $gPath.edge-list, Red => $gPath.vertex-list}, |%opts):svg

A proper maze is a maze given with its walls (not with the space between walls).
Remark: For didactical reasons, the maze in this section is small so that the steps—outlined in the introduction—can be easily followed.
Make two regular graphs: one for the maze walls and the other for the maze paths.
# Maze dimensions
my ($n, $m) = (6, 12) »*» 1;
# Walls graph
my $g1 = Graph::Grid.new($n, $m, prefix => 'w');
# Space graph
my $g2 = Graph::Grid.new($n-1, $m-1);
$g2.vertex-coordinates = $g2.vertex-coordinates.map({ $_.key => $_.value >>+>> 0.5 }).Hash;
$g2
# Graph(vertexes => 55, edges => 94, directed => False)
Maze Path Graph:
my $mazePath = Graph.new($g2.edges(:dataset).map({ $_<weight> = random-real([10,1000]); $_}));
$mazePath = $mazePath.find-spanning-tree;
$mazePath.vertex-coordinates = $g2.vertex-coordinates;
$mazePath
# Graph(vertexes => 55, edges => 54, directed => False)
Combined Graph:
my $g3 = Graph.new([|$g1.edges, |$mazePath.edges]);
$g3.vertex-coordinates = [|$g1.vertex-coordinates, |$mazePath.vertex-coordinates].Hash;
$g3
# Graph(vertexes => 127, edges => 180, directed => False)
Plot the combined graph:
#% html
$g3.dot(
highlight => $mazePath,
:node-labels,
background => "Black",
node-width => 0.45,
node-height => 0.2,
edge-width => 4,
size => '10,10!',
engine => 'neato'
):svg

Remove wall edges using a formula:
my $g4 = $g3.clone;
for $mazePath.edges -> $e {
my ($i, $j) = |$e.key.split('_')».Int;
my ($i2, $j2) = |$e.value.split('_')».Int;
if $i2 < $i || $j2 < $j {
($i2, $j2, $i, $j) = ($i, $j, $i2, $j2)
}
# Horizontal
if $i == $i2 && $j < $j2 {
$g4 = $g4.edge-delete( "w{$i2}_{$j2}" => "w{$i2+1}_{$j2}")
}
# Vertical
if $j == $j2 && $i < $i2 {
$g4 = $g4.edge-delete( "w{$i2}_{$j2}" => "w{$i2}_{$j2+1}")
}
}
$g4
# Graph(vertexes => 127, edges => 126, directed => False)
Plot wall graph and maze space graph:
#% html
$g4.dot(
highlight => $mazePath,
:!node-labels,
background => "Black",
node-width => 0.25,
node-height => 0.2,
edge-width => 4,
size => '10,10!',
engine => 'neato'
):svg
Fancier maze presentation with rectangular vertices and edges (with matching sizes):
#% html
my $g5 = $g4.subgraph($g1.vertex-list);
my @path = $mazePath.find-shortest-path('0_0', "{$n-2}_{$m-2}");
say @path.elems;
my @mazeStartEnd = "w0_0", w0_0 => "w0_1", w0_0 => "w1_0", "w{$n-1}_{$m-1}", "w{$n-1}_{$m-1}" => "w{$n-1}_{$m-2}", "w{$n-1}_{$m-1}" => "w{$n-2}_{$m-1}";
$g4.dot(
highlight => {'#1F1F1F' => [|$mazePath.vertex-list, |$mazePath.edge-list, |@mazeStartEnd], Orange => @path},
#highlight => {'#1F1F1F' => @mazeStartEnd},
background => '#1F1F1F',
size => '10,10!',
:!node-labels,
node-shape => 'square',
node-color => 'SteelBlue',
node-fill-color => 'SteelBlue',
node-width => 0.4,
edge-width => 30,
engine => 'neato'
):svg
Let us create another maze based on a hexagonal grid. Here are two grid graphs:
# Maze dimensions
my ($n, $m) = (6, 10) »*» 2;
# Walls graph
my $g1 = Graph::HexagonalGrid.new($n, $m, prefix => 'w');
# Space graph
my $g2 = Graph::TriangularGrid.new($n-1, $m-1);
$g2.vertex-coordinates = $g2.vertex-coordinates.map({ $_.key => $_.value >>+<< [sqrt(3), 1 ] }).Hash;
$g2
Graph(vertexes => 240, edges => 657, directed => False)
#% html
$g1.union($g2).dot(
highlight => $g2,
:!node-labels,
background => "#1F1F1F",
node-width => 0.85,
node-height => 0.85,
node-font-size => 28,
node-shape => 'hexagon',
edge-width => 7,
size => '10,10!',
engine => 'neato'
):svg

Maze Path Graph:
my $mazePath = Graph.new($g2.edges(:dataset).map({ $_<weight> = random-real([10,1000]); $_}));
$mazePath = $mazePath.find-spanning-tree;
$mazePath = Graph.new($mazePath.edges);
$mazePath.vertex-coordinates = $g2.vertex-coordinates;
$mazePath
# Graph(vertexes => 240, edges => 239, directed => False)
Combine the walls-maze and the maze-path graphs (i.e., make a union of them), and plot the resulting graph:
#% html
my $g3 = $g1.union($mazePath);
$g3.dot(
highlight => $mazePath,
:node-labels,
background => "#1F1F1F",
node-width => 0.85,
node-height => 0.85,
node-font-size => 28,
node-shape => 'hexagon',
edge-width => 7,
size => '10,10!',
engine => 'neato'
):svg
Make a nearest neighbor points finder functor:
my &finder = nearest($g1.vertex-coordinates.Array, method => 'KDTree');
Math::Nearest::Finder(Algorithm::KDimensionalTree(points => 544, distance-function => &euclidean-distance, labels => 544))
Take a maze edge and its vertex points:
my $e = $mazePath.edges.head;
my @points = $g2.vertex-coordinates{($e.kv)};
# [[-3.4641016151381225 -2] [-1.7320508075691228 1]]
Find the edge’s midpoint and the nearest wall-graph vertices:
my @m = |((@points.head <<+>> @points.tail) >>/>> 2);
say "Mean edge point: {@m}";
my @vs = |&finder.nearest(@m, 2, prop => <label>).flat;
say "To remove: {@vs}";
# Mean edge point: -2.5980762113536224 -0.5
# To remove: w3 w6
Loop over all maze edges, removing wall-maze edges:
my $g4 = $g1.clone;
for $mazePath.edges -> $e {
my @points = $g2.vertex-coordinates{($e.kv)};
my @m = |((@points.head <<+>> @points.tail) >>/>> 2);
my @vs = |&finder.nearest(@m, 2, prop => <label>).flat;
$g4 = $g4.edge-delete(@vs.head => @vs.tail);
}
$g4
# Graph(vertexes => 544, edges => 544, directed => False)
The start and end points of the maze:
my ($start, $end) = $g4.vertex-list.head, $g4.vertex-list.sort({ $_.substr(1).Int }).tail;
# (w0 w543)
Finding the Maze Solution:
my $solution = Graph::Path.new: $mazePath.find-shortest-path(|$mazePath.vertex-list.sort(*.Int)[0,*-1]);
$solution.vertex-coordinates = $mazePath.vertex-coordinates.grep({$_.key ∈ $solution.vertex-list }).Hash;
$solution
# Graph(vertexes => 50, edges => 49, directed => False)
Plot the maze:
#% html
my @mazeStartEnd = $start, $end, |$g4.neighborhood-graph([$start, $end]).edges;
my $g5 = $g4.union($solution);
my %opts =
:!node-labels,
background => "#1F1F1F",
node-width => 0.8,
node-height => 0.8,
node-shape => 'circle',
edge-width => 40,
size => '10,10!',
engine => 'neato';
$g4.dot(highlight => {'#1F1F1F' => @mazeStartEnd}, |%opts):svg

(Here is the solution of the maze).
[AA1] Anton Antonov, “Day 12 – Graphs in Raku”, (2024), Raku Advent Calendar at WordPress.
[AAp1] Anton Antonov, Graph, Raku package, (2024–2025), GitHub/antononcube.
[AAp2] Anton Antonov, Math::Nearest, Raku package, (2024), GitHub/antononcube.
[AAv1] Anton Antonov, “Graphs” videos playlist, (2024-2025), YouTube/@AAA4prediction.
Hello again! I return during this week of winter solstice to tell you about my experience participating in the Langjam Gamejam. I planned to use Raku, partially so that you could have an advent blogpost to read today, but also because Raku’s builtin support for grammars ensure that I would not get stuck when writing my parser.
I did a few things to ensure that I would be able to complete the game jam. The first was to be realistic about what I could achieve; with seven days of time, I could realistically expect to produce about three weekends worth of working code. This is only going to be a few hundred lines, maybe one or two files total, and prioritizing basic functionality over any fancy features.
I decided to make an idle game.
There’s no rule against deciding that ahead of time. I also decided to use Raku. That’s allowed too. I read the source of a couple different idle games too, mostly to get ideas of what not to do. In particular, big thanks to Idle Game Maker by Orteil, Antimatter Dimensions by Ivar K., and Trimps by the Trimp authors for publishing reasonably-readable source code. All three of these have some notion of programmability, although I ended up doing something quite different.
The first place to start when making a game is with the scenario that the
player will be asked to experience. Games are fundamentally about roleplay,
and roles only exist within scenarios. Fortunately, I didn’t have to come up
with any of this.
Instead, I asked my friend Remi to come up with something interesting. We spent a couple hours adapting an idea for a Zelda-style fishing minigame, with the novel twist that the game would mechanically be an idle game; instead of putting in the athletic effort to retrieve the fish, the player manages a fishing business and delegates the work to employees.
It’s important to allow a genuine brainstorm at the beginning of the process.
Yes-and reasoning is essential for developing concepts. At the same time, it was important that we not plan for work that we couldn’t schedule. Remi committed to drawing a few icons and I committed to carrying out the core of the gamejam objectives:
The first place to start when making a language is with the objects of that language. I don’t mean object-oriented design but the idea that the language expresses some sort of manipulation of reality. What are we manipulating? How do we manipulate them?
At a high level, idle and incremental games are about resource management. They can also include capacity planning. Thus, I decided that resources are the main objects of study. I also needed some way for the player to interact with the game world, and clickable buttons are a traditional way to express idle games. For each button, I’d thought to have a corresponding action in the game, which I’d also express in language.
I also needed to figure out what substrate I’m going to use. I mean, of course I’m using Raku, but how deeply do I want to embed the game? At one end, I could imagine compiling the game into a single blob which runs wholly in the end user’s windowing system or Web browser, so that there’s nothing of Raku in the end product.
At the other end, I could imagine shallowly embedding the game by writing some Raku subroutines and having the game developer write in ordinary Raku. I initially decided to go with the shallowest embedding that would still allow me to use Raku’s syntax for arithmetic: a Raku sublanguage, or Raku slang. Technically, a slang
is its own programming language, or so I was prepared to argue.
One open question concerned the passage of time. A resource evolves in time, perhaps growing or shrinking; it also has some invariants in time, particularly identity. What did I actually want to store internally? All hand-coded games devolve into a soup of objects cross-referenced by string-keyed maps, or at least that was the case for a half-dozen idle games that I’ve looked at. Maybe we can organize all of that into one big string-keyed map?
Another question is how the game will be experienced. I’d assumed that it should be possible to put up some simple HTTP server and run it locally. My notes are unclear, but I think that this is around the first time that I took a serious look at Humming-Bird.
Let’s actually write some code. I started by writing a slang that abused the Raku metamodel. I was inspired by OO::Actors, which introduces an actor keyword, as well as the implementation of the standard grammar keyword. I can just introduce my own resource and action keywords which manage some subexpressions, including Raku arithmetic, and that’ll be my language. To prototype this, I first wrote out a file which I want to be able to load, and then I wrote the parser which handles it.
Here’s a snippet from that first prototype:
resource fishmonger {
flavor-text "employee with knives and a booming voice for telling stories";
eats seafood by 0.017 per second;
eats bux by 15 per second;
converts from seafood into bux by 75 per second;
}
action hire-fishmonger {
flavor-text "employ a fishmonger to sell seafood";
costs 10 bux;
pays 1 fishmonger;
}Several features are very important here. One big deal is that flavor text is inalienable from the resources and actions. I was very conflicted about this. Languages like Idle Game Maker are basically enlightened CSS and HTML; they are extremely concerned with presentation details rather than getting to the essential mechanics and handling time.
At the same time, Remi and I are both big fans of flavor text both for its immersive value as well as for its ability to create a memorable experience. Another important idea here is that costs and pays are two distinct attributes in concrete syntax, even though they’re going to be implemented as the same underlying sort of amount-and-currency pair.
This syntax is a little heavy. I was imagining that this would be a sort of Ruby or Tcl DSL where each command takes a row of arguments, some of which are literal tokens, and imperatively builds the corresponding resources and actions.
At this point, the scenario is complete. The game will have a few natural resources, like plankton, fish, and sharks; a conversion from fish to seafood; employees like fishers, fishmongers, and white mages; and an enhancement that white mages apply to fishers. There is no objective; it’s a population-dynamics sandbox.
After a day of trying to understand Raku’s metamodel, I concluded that a slang is the wrong layer of integration. I really wanted to run an input file through a parser in order to build a small nest of Resource and Action objects in memory, set up an HTTP server displaying them, and repeatedly take one tick per second, integrating changes over all of those objects.
This was a gumption trap for me; I completely lost motivation for a few hours. In those times, it is essential to allow one’s emotions to flow in order to move past them, and also essential to rest in order to restore energy.
After recovering a bit, I cleaned up my repository and thought about what I should do next. I might as well write a proper grammar. What should that language look like? I agonized over this for a few minutes, went through the possibilities of fixity and bracketing, and eventually decided that a nice little S-expression language would work for my needs.
This did mean that I would need to internalize arithmetic, but I also knew one of the standard cheats of game development: it’s okay to not implement arithmetic operations which aren’t actually used. Consider the following snippet:
(resource plankton 1e15
"little crunchy floaty things"
(growth 0.004 /s)
(view water-color (if (< .count 1e20) "clear" "cloudy"))
(view concentration (str (/ .count 2e14)))
)
(action look-at-water-color
"gaze at the ocean"
(enables view plankton water-color)
)
(action measure-plankton
"buy a plankton meter and put it in the water"
(enables view plankton concentration)
(costs 10 bux)
)This is from my prototype. The only arithmetic that’s required is in the views, which format internal numbers about resources into strings. For those, I have a mini-language which allows the user to specify any arithmetic they want, as long as it’s either division or less-than comparisons. The formatting language is strongly typed; the parser won’t allow a non-Boolean operation as an if conditional, for example.
Some other design decisions stand out. Flavor text is now required. Resources have starting counts, which are also required. Rates always end with “/s”, an abbreviation for “per second” that is supposed to easily distinguish them from non-rates.
Gumption management requires not just succeeding, but having a feeling of understanding and competence. I probably could have started on the parser that night, but instead I walked to the bar and speedran Zelda 3, doing any% No Major Glitches and finishing in about two hours and change. Not a superb time, because I grabbed quite a few backups, including an entire extra heart and two bottles; but I didn’t die. The parser can wait until tomorrow.
Parsing an S-expression is really easy, especially when the list of special forms (the words that can legally follow an opening parenthesis) is short. For each special form, we have a rule that parses each of the required components in order, followed by an optional zero-or-more collection of modifiers / attributes / members / components / accessories. The resource special form from Wednesday is parsed with a rule like:
rule thing:sym { '(resource' <s> * ')' }The parser bottoms out on some very simple tokens. For parsing numbers, we parse a subset of what Raku accepts and then use .Rat or .Num methods to convert those strings to live values by reusing Raku’s parser. I may not have been able to reuse arithmetic but I was certainly able to reuse the numerals!
token id { + }
token s { '"' + '"' }
token n { + ('.' +)? ('e' +)? }As I wired up the parser, I also set up a Humming-Bird application. I’m a fan of Ruby’s Sinatra and Python’s Flask, so it seemed like Humming-Bird would be a good fit for me. It doesn’t come with a preferred HTML-emitting library, so I tried a few options. I started with HTML::Tag, which I had added to the project on either Tuesday or Wednesday, but after a few minutes of practical usage, it became totally unusable due to syntactic zones of ceremony (Subramaniam, Seemann, myself): making a fresh HTML tag requires many source characters. I ended up using HTML::Functional, which is much lighter-weight but occasionally allows me to misuse Nil as a string.
I’m hacking out two roles. I’m presenting them here in their final versions; initially they didn’t take any parameters, which was too restrictive. One role is for rendering HTML and the other role is for evolving with each tick.
The %context is all of the resources and actions, and the $resource is the resource currently being acted upon. This sort of late-bound approach is technically too flexible for what I’m building, but I don’t feel like restricting it.
role Render { method html(%context, $resource) { ... } }
role Evolve { method tick(%context, $resource) {;} }I committed, pushed, and asked Remi for feedback.
Remi approves! They’ll make a few cute little icons for some resources. At this point, I stopped and reflected upon what I’d made so far. Pastafarians typically take Fridays off, and I’m not about to work when I could rest instead. What works? What doesn’t work? Where should I spend the rest of my time? What should I have for dinner?
The parser works. The Resource and Action objects operate as nodes of an AST. Exporting the AST as HTML with Render.html() works. Traversing the AST for a tick with Evolve.tick() also works. The Nix environment, which Ihaven’t mentioned yet, also works; I’m using direnv to configure the environment and
install Raku packages.
Arithmetic operations don’t work yet. Actions don’t actually act on anything. Remi’s artwork isn’t visible and I haven’t split out the CSS yet.
I should spend the rest of my time getting the core mechanics of rendering and evolution to work properly. Easy to say; harder to do.
For dinner, I’ll have noodles of some sort, because it’s Friday. I ended up having spaghetti and meatballs in red sauce.
Before dinner, I went to the bar and speedran Mario 1. I played for about 90 minutes but I didn’t finish a single run. On 8-3, the penultimate level, I was repeatedly defeated by a gauntlet of tough enemies.
Humming-Bird got in my way a little; it blocks by default and the
documentation doesn’t explain how to fix it. After reading the relevant code,
I had to change this line:
listen(8080);To have a non-blocking annotation:
listen(8080, :no-block);I also explore how to perform ticks in the background. I do find Supply.interval, but that will let the interpreter exit. Instead, I end up with the following hack:
while 1 { sleep 1; $venture.tick };As I wired up operations and fixing display bugs, I became increasingly stressed as my CSS changes aren’t being applied. By doing some testing, I discovered that the Humming-Bird convenience helper for attaching static directories is not working. I had initially written:
static('/static', 'static');But this doesn’t work, or it had worked on Friday but not on Saturday, or I had somehow mistyped “static”, or any of a dozen other impossible considerations. I knew that I can’t get distracted by this, and I finished up all of the rest of the functionality; the game works, but it’s not styled and Remi’s artwork isn’t visible.
That’s the end of the game jam. I produced a language and a game. However, the game doesn’t display properly and I wouldn’t consider it to be playable. What a frustration.
I’m not done yet! I want to ensure that the release version has Remi’s artwork displayed. First, I hand-wrote the static routes; these do correctly route the CSS and images.
$router.get('/static/style.css', -> $req, $resp {
$resp.file('static/style.css');
});
$router.get('/static/icons/:icon', -> $req, $resp {
my $name = $req.param('icon');
1$name.contains('..') ?? $resp.status(400) !! $resp.file('static/icons/' ~ $name);
});I found a few holes in our scenario. For example, there’s no way to see how many Bux the user has. By default, resource amounts are hidden both to keep the UI uncluttered and to provide a sense of mystery; however, for Bux or seafood, we want to give the user precise numbers. Our existing syntax can fully accommodate this! The view is enabled by an action which doesn’t have any line items (costs or pays) and it prints the .count variable as-is.
(resource bux 1000
"wireless cash"
(view cash-on-hand (str .count))
)
(action check-balance
"become aware of our earnings"
(enables view bux cash-on-hand)
)With these two fixes, we now have a working interface that allows the scenario to be fully accessed! The new view looks like this:

Finally, I’m not going to be able to deploy this version as written. I’ll have to do some reading on production HTTP setups for Raku. When the game loads, it tries to load one image for every visible resource. If more than about five images are requested then the page fails to load. Every action is an HTTP POST which causes everything to reload again.
I imagine that this is properly fixed by adding entity tags to the HTTP backend so that images can be cached. For example, I took the screenshot in the header of this blog post while Firefox was still considering whether it could load the image for plankton; it eventually gives up:

Every load of the page causes a different set of images to not load. This is an unacceptable game experience.
The idea of a declarative idle-game maker is reasonable and it was only a week’s effort to prototype a basic interpreter which simulates a simple scenario. I think that the biggest time sinks were trying to make a slang instead of a deeper language with a parser, fighting with Humming-Bird, and generally trying to keep code clean. On that last point: I found that cleaning up my code was necessary to let bugs and mistakes become visible.
The game comes out to about three hundred lines of Raku and fewer than one hundred lines of S-expressions. It’s within my coding budget for sure. I don’t think that I went for more than I could reasonably accomplish. The entire code is available in this gist. Remi quite reasonably doesn’t want their art uploaded to GitHub, but you can check out more of their work at their website.
Have a happy winter solstice and Holiday!
This document (notebook) discusses number theory properties and relationships of the integer 2026.
The integer 2026 is semiprime and a happy number, with 365 as one of its primitive roots. Although 2026 may not be particularly noteworthy in number theory, this provides a great excuse to create various elaborate visualizations that reveal some interesting aspects of the number.
The computations in this document are done with the Raku package “Math::NumberTheory”, [AAp1].
use Math::NumberTheory;
use Math::NumberTheory::Utilities;
use Data::Importers;
use Data::Translators;
use Data::TypeSystem;
use Graph;
use Graph::Classes;
use JavaScript::D3;
Notebook priming code:
#%javascript
require.config({
paths: {
d3: 'https://d3js.org/d3.v7.min'
}});
require(['d3'], function(d3) {
console.log(d3);
});
First, 2026 is obviously not prime—it is divisible by 2—but dividing it by 2 gives a prime, 1013:
is-prime(2026 / 2)
# True
Hence, 2026 is a semiprime. The integer 1013 is not a Gaussian prime, though:
is-prime(1013, :gaussian-integers)
# False
A happy number is a number for which iteratively summing the squares of its digits eventually reaches 1 (e.g., 13 → 10 → 1).
Here is a check that 2026 is happy:
is-happy-number(2026)
# True
Here is the corresponding trail of digit-square sums:
is-happy-number(2026, :trail).tail.head(*-1).join(' → ')
# 2026 → 44 → 32 → 13 → 10 → 1
Not many years in this century are happy numbers:
(2000...2100).grep({ is-happy-number($_) })
# (2003 2008 2019 2026 2030 2036 2039 2062 2063 2080 2091 2093)
The decomposition of 2026 as 2 * 1013 means the multiplicative group modulo 2026 has primitive roots. A primitive root exists for an integer n if and only if n is 1, 2, 4, p^k, or 2 p^k, where p is an odd prime and k > 0.
We can check additional facts about 2026, such as whether it is “square-free”, among other properties. However, let us compare these with the feature-rich 2025 in the next section.
Here is a side-by-side comparison of key number theory properties for 2025 and 2026.
| Property | 2025 | 2026 | Notes |
|---|---|---|---|
| Prime or Composite | Composite | Composite | Both non-prime. |
| Prime Factorization | 3⁴ × 5² (81 × 25) | 2 × 1013 | 2025 has repeated small primes; 2026 is a semiprime (product of two distinct primes). |
| Number of Divisors | 15 (highly composite for its size) | 4 (1, 2, 1013, 2026) | 2025 has many divisors; 2026 has very few. |
| Perfect Square | Yes (45² = 2025) | No | Major highlight for 2025—rare square year. |
| Sum of Cubes | Yes (1³ + 2³ + … + 9³ = (1 + … + 9)² = 2025) | No | Iconic property for 2025 (Nicomachus’s theorem). |
| Happy Number | No (process leads to cycle including 4) | Yes (repeated squared digit sums reach 1) | Key point for 2026—its main “happy” trait. |
| Harshad Number | Yes (divisible by 9) | No (not divisible by 10) | 2025 qualifies; 2026 does not. |
| Primitive Roots | No | Yes | This is a relatively rare property to have. |
| Other Notable Traits | – (20 + 25)² = 2025 – Sum of first 45 odd numbers – Deficient number – Many pattern-based representations | – Even number – Deficient number – Few special patterns | 2025 is packed with elegant properties; 2026 is more “plain” beyond being happy. |
| Overall “Interest” Level | Highly interesting—celebrated in math communities for squares, cubes, and patterns | Relatively uninteresting—basic semiprime with no standout geometric or sum properties | Reinforces blog’s angle. |
To summarize:
Here is a computationally generated comparison table of most of the properties found in the table above:
#% html
my &divisors-count = { divisors($_).elems };
<is-prime is-composite divisors-count prime-omega euler-phi is-square-free is-happy-number is-harshad-number is-deficient-number primitive-root>.map({ %(sub => $_, '2025' => ::("&$_")(2025), '2026' => ::("&$_")(2026) ) })
==> to-html(field-names => ['sub', '2025', '2026'], align => 'left')
| sub | 2025 | 2026 |
|---|---|---|
| is-prime | False | False |
| is-composite | True | True |
| divisors-count | 15 | 4 |
| prime-omega | 6 | 2 |
| euler-phi | 1080 | 1012 |
| is-square-free | False | True |
| is-happy-number | False | True |
| is-harshad-number | True | False |
| is-deficient-number | True | True |
| primitive-root | (Any) | 3 |
Digits of 2026 represented in the Phi number system:
my @res = phi-number-system(2026);
# [15 13 10 6 -6 -11 -16]
Verification:
@res.map({ ϕ ** $_ }).sum.round(10e-11);
# 2026
Let us create and plot a graph showing the trails of all happy numbers less than or equal to 2026. Below, we identify these numbers and their corresponding trails:
my @ns = 1...2026;
my @trails = @ns.map({ is-happy-number($_):trail }).grep(*.head);
deduce-type(@trails)
# Vector((Any), 302)
Here is the corresponding trails graph, highlighting the primes and happy numbers:
#% html
my @prime-too = @trails.grep(*.head).map(*.tail.head).grep(*.&is-prime);
my @happy-too = @ns.grep(*.&is-harshad-number).grep(*.&is-happy-number);
my %highlight = '#006400' => @prime-too».Str, # Deep Christmas green for primes
'Blue' => [2026.Str, ], # Blue for the special year
'#fbb606ff' => @happy-too».Str; # Darker gold for joyful numbers
my @edges = @trails.map({ $_.tail.head(*-1).rotor(2 => -1).map({ $_.head.Str => $_.tail.Str }) }).flat;
my $gTrails = Graph.new(@edges):!directed;
$gTrails.dot(
engine => 'neato',
graph-size => 12,
vertex-shape => 'ellipse', vertex-height => 0.2, vertex-width => 0.4,
:10vertex-font-size,
vertex-color => '#B41E3A',
vertex-fill-color => '#B41E3A',
arrowsize => 0.6,
edge-color => '#B41E3A',
edge-width => 1.4,
splines => 'curved',
:%highlight
):svg

There is a theorem by Gauss stating that any integer can be represented as a sum of at most three triangular numbers. Instead of programming such an integer decomposition representation in Raku, we can simply use Wolfram|Alpha, [AA1, AA3], or wolframscript to find an “interesting” solution:
#% bash
wolframscript -code 'FindInstance[{2026 == PolygonalNumber[i] + PolygonalNumber[j] + PolygonalNumber[k], i > 10, j > 10, k > 10}, {i, j, k}, Integers]'
# {{i -> 11, j -> 19, k -> 59}}
Here, we verify the result using Raku:
say "Triangular numbers : ", <11 19 59>.&polygonal-number(:3sides);
say "Sum : ", <11 19 59>.&polygonal-number(:3sides).sum;
# Triangular numbers : (66 190 1770)
# Sum : 2026
Here is the number of primitive roots of the multiplication group modulo 2026:
primitive-root-list(2026).elems
# 440
Here are chord plots [AA2, AAp1, AAp2, AAv1] corresponding to a few selected primitive roots:
#% js
my $n = 2026;
<339 365 1529>.map( -> $p {
my &f = -> $x { power-mod($p, $x, $n) => power-mod($p, $x + 1, $n) };
my @segments = circular-chords-tracing($n, with => &f, :d);
@segments .= map({ $_<group> = $_<group>.Str; $_ });
js-d3-list-line-plot(
@segments,
stroke-width => 0.1,
background => '#1F1F1F',
:300width, :300height,
:!axes,
:!legends,
:10margins,
color-scheme => 'Ivory',
#:$title-color, title => $p
)
}).join("\n")

Remark: It is interesting that 365 (the number of days in a common calendar year) is a primitive root of the multiplicative group generated by 2026. Not many years have this property this century; many do not have primitive roots at all.
(2000...2100).hyper(:4degree).grep({ 365 ∈ primitive-root-list($_) })
# (2003 2026 2039 2053 2063 2078 2089)
The number 2026 appears in 18 results of the search “2026 graphs” in «The On-line Encyclopedia of Integer Sequences». Here is the first result (from 2025-12-17): A033483, “Number of disconnected 4-valent (or quartic) graphs with n nodes.” Below, we ingest the internal format of A033483’s page:
my $internal = data-import('https://oeis.org/A033483/internal', 'plaintext');
text-stats($internal)
# (chars => 2928 words => 383 lines => 98)
Here, we verify the title:
with $internal.match(/ '%' N (<-[%]>*)? <?before '%'> /) { $0.Str.trim }
# Number of disconnected 4-valent (or quartic) graphs with n nodes.
Here, we get the corresponding sequence:
my @seq = do with data-import('https://oeis.org/A033483/list', 'plaintext').match(/'[' (.*) ']'/) {
$0.Str.split(',')».trim
}
# [0 0 0 0 0 0 0 0 0 0 1 1 3 8 25 88 378 2026 13351 104595 930586 9124662 96699987 1095469608 13175272208 167460699184 2241578965849 31510542635443 464047929509794 7143991172244290 114749135506381940 1919658575933845129 33393712487076999918 603152722419661386031]
Here we find the position of 2026 in that sequence:
@seq.grep(2026):k
# (17)
Given the title of the sequence and the extracted position of 2026, this means that the number of disconnected 4-regular graphs with 17 vertices is 2026. Let us create a few graphs from that set by using the 5-vertex complete graph (K₅) and circulant graphs.
Here is an example of such a graph:
#% html
reduce(
{ $^a.union($^b) },
[
Graph::Complete.new(5),
Graph::Complete.new(5).index-graph(6),
Graph::Circulant.new(7,[1,2]).index-graph(11)
]
).dot(engine => 'neato'):svg
And here is another one:
#% html
my $g = reduce(
{ $^a.union($^b) },
[
Graph::Complete.new(5).index-graph(13),
Graph::Circulant.new(12, [1, 5]).index-graph(1),
]
);
$g.dot(engine => 'neato', splines => 'curved'):svg
Here, we check that all vertices have degree 4:
$g.vertex-degree.sum / $g.vertex-count
# 4
Remark: Note that although the plots show disjoint graphs, each graph plot represents a single graph object.
Here are a few ways to compute 2026:
sub postfix:<!>(UInt:D $n) { [*] 1..$n }
[
2**11 - 22,
1 + 2 * 3 / 4 / 5 / 6 * 7! * 8 + 9,
1 + 2 + 3 * 4! + 5 / 6! * 7 * 8! - 9,
1 + 2 + 345 * 6 - 7 * 8 + 9,
1 - 2 * 3! * 456 * 7 + 8! + 9,
12 / 3! * 4**5 + 67 - 89,
12**3 + 45 / 6! * 7! - 8 - 9,
123 / 4! * 56 * 7 + 8 + 9,
9! / 8 / 7 / 6 + 5**4 + 321,
9 * 8 - 7 + 654 * 3 - 2 + 1,
987 + 6! + 5 * 4**3 - 2 + 1
]
# [2026 2026 2026 2026 2026 2026 2026 2026 2026 2026 2026]
This section has a few additional (leftover) comments.
GCD and LCD are also extended to work with rationals.integer-digits, is-happy-number, is-harshad-number, is-abundant-number, is-perfect-number, is-deficient-number, abundant-number, deficient-number, and perfect-number.
integer-digits — had lower implementation priority.
#%bash
number-theory is happy number 2026
# True
#%bash
number-theory primitive root list 2026 | grep 365
# 365
[AA1] Anton Antonov, “Numeric properties of 2025”, (2025), RakuForPrediction at WordPress.
[AA2] Anton Antonov, “Primitive roots generation trails”, (2025), MathematicaForPrediction at WordPress.
[AA3] Anton Antonov, “Chatbook New Magic Cells”, (2024), RakuForPrediction at WordPress.
[EW1] Eric W. Weisstein, “Quartic Graph”. From MathWorld–A Wolfram Resource.
[AAn1] Anton Antonov, “Primitive roots generation trails”, (2025), Wolfram Community. STAFFPICKS, April 9, 2025.
[EPn1] Ed Pegg, “Happy 2025 =1³+2³+3³+4³+5³+6³+7³+8³+9³!”, Wolfram Community, STAFFPICKS, December 30, 2024.
[AAp1] Anton Antonov, Math::NumberTheory, Raku package, (2025), GitHub/antononcube.
[AAp2] Anton Antonov,
NumberTheoryUtilities, Wolfram Language paclet, (2025), Wolfram Language Paclet Repository.
[AAp3] Anton Antonov, JavaScript::D3, Raku package, (2021-2025), GitHub/antononcube.
[AAp4] Anton Antonov, Graph, Raku package, (2024-2025), GitHub/antononcube.
[AAv1] Anton Antonov, Number theory neat examples in Raku (Set 3), (2025), YouTube/@AAA4prediction.
When I start something new in Raku with Cro, I almost always begin with a mental sketch: two or three routes, a response shape, maybe a typed segment. In the Perl world I leaned heavily on Mojolicious::Lite for that prototyping phase. In Cro—powerful and modular as it is—I missed an immediate “lite mode”: no manual wiring of server, pipeline, and router just to test a thought. Out of that friction came Crolite: a thin layer that re‑exports Cro's routing keywords and adds a multi MAIN with quick exploration commands.
RouteSet + a tiny embedded CLI.From a local checkout (inside the project directory):
zef install .
Once published:
zef install Crolite
File example.raku:
use Crolite;
get -> $any {
content 'text/plain', "Hello: $any";
}
delete -> 'thing', Int $id {
content 'application/json', %( :$id );
}
List derived routes:
raku example.raku routes
Run a development server:
raku example.raku --host=127.0.0.1 --port=3000 daemon
Test a route without a persistent daemon (ephemeral in‑memory request):
raku example.raku GET /thing/42
raku app.raku routes to confirm patterns.raku app.raku GET /foo/123.| Command | Purpose |
|---|---|
routes |
Print summary of registered endpoints |
[--host=0.0.0.0] [--port=10000] daemon |
Start simple Cro server |
GET <path> |
Single in‑memory GET |
POST <path> |
Single POST (no custom body) |
PUT <path> |
Single PUT |
DELETE <path> |
Single DELETE |
--method=<VERB> http <path> |
Generic form for any method |
Stop the daemon with Ctrl+C (SIGINT is trapped for graceful shutdown).
use Crolite;
get -> 'greet', Str $name {
content 'text/plain', "Hi $name!";
}
post -> 'sum', Int $a, Int $b {
content 'application/json', %( total => $a + $b );
}
Test:
raku app.raku GET /greet/Ana
raku app.raku POST /sum/2/5
Just produce a Hash or Map:
get -> 'status' {
content 'application/json', %( service => 'ok', ts => DateTime.now );
}
If you manually add before or after handlers to the underlying RouteSet, Crolite includes them when composing the application for daemon:
use Crolite;
$*CRO-ROUTE-SET.before: {
# Simple logging / auth stub
proceed;
}
get -> 'ping' { content 'text/plain', 'pong' }
use Crolite;
get -> 'health' {
content 'application/json', %( ok => True );
}
put -> 'echo', Str $msg {
content 'text/plain', $msg.uc;
}
post -> 'calc', Int $x, Int $y {
content 'application/json', %( sum => $x + $y, prod => $x * $y );
}
delete -> 'soft', Int $id {
content 'application/json', %( deleted => $id, soft => True );
}
Quick ping:
raku app.raku GET /health
Server:
raku app.raku --port=4000 daemon
routes surfaces path typos immediately.curl just to see a body.daemon mode.routes.Cro::HTTP::Test (mirrors what the CLI verbs do).Crolite does not compete with the full flexibility of a structured Cro project; it lowers the time to first useful response when exploring HTTP ideas in Raku. If you also miss the lightness of Mojolicious::Lite, try making the first step of each spike just:
use Crolite;
Then, once the shape hardens, graduate to something more robust.
Suggestions, issues, and PRs welcome.
Cro’s HTTP router is great at declaring routes, but it doesn’t provide a first‑class way to reference those routes elsewhere in your app. Cro::HTTP::RouterUtils fills that gap: it lets you reference endpoints by name, build typed-safe paths, generate HTMX attributes, redirect to routes, and even call the underlying implementation.
path() builder validates parameter typeshx-attrs() renders HTMX attributes with the correct method and URLredirect-to() returns a Cro redirect to the endpointcall() invokes the route implementation directly (handy for tests)include with prefixes seamlesslyRepo: https://github.com/FCO/Cro-HTTP-RouterUtils
zef install --depsonly .
use Cro::HTTP::RouterUtils;
my $app = route {
# Name a route via a named sub
get my sub greet-path('greet', $name) {
content 'text/plain', "Hello, $name!"
}
# Use the endpoint by name
get -> 'links' {
my $ep = endpoints('greet-path');
content 'text/html', qq:to/END/
<a href="{ $ep.path(:name<alice>) }">alice</a>
<a href="#" { $ep.hx-attrs(:name<bob>, :trigger<click>) }>bob</a>
END
}
}
endpoints('your-name').get_greet.
# Auto-named
get -> 'greet', Str :$name { 200 }
endpoints('get_greet').path; # => "/greet"
# Named
get my sub greet-path('greet', $name) { "Hello, $name!" }
endpoints('greet-path').path(:name<alice>); # => "/greet/alice"
Includes with prefixes are supported transparently:
include external => other-routes; # /external prefix applied
endpoints('external-ep1').method; # "GET"
endpoints('external-ep1').path; # "/external/returns-ok"
path(*%values) enforces your route’s typed parameters; missing or invalid values throw.
get my sub sum('sum', Int $a, Int $b) { $a + $b }
my $ep = endpoints('sum');
$ep.path(:a(1), :b(2)); # "/sum/1/2"
$ep.path(:a("x"), :b(2)); # throws (type mismatch)
$ep.path(:a(1)); # throws (missing parameter)
hx-attrs(:args…) returns a space-separated string of HTMX attributes. It uses the endpoint’s HTTP method by default (e.g., hx-get) and the built URL.
<a href="#"
{ endpoints('greet-path').hx-attrs(
:name<alice>,
:trigger<click>,
:target<#out>,
:swap<'outerHTML settle:200ms'>,
:push-url<true>,
:on{ click => "console.log(\"clicked\")" }
)
}>
Load Alice
</a>
Highlights supported:
method override; parameters via :name<...> etc.trigger, target, confirm, indicator, swap, oob (as hx-swap-oob), boost
push-url (Bool|Str), replace-url (Bool|Str)select, select-oob
vals, headers, request
disable, validate
disabled-elt, disinherit, encoding, ext, history, history-elt, include, inherit, params, prompt, sync, vars (deprecated):on{ event => "code" } emits hx-on:event='code'
Example minimal output:
hx-get='/greet/alice' hx-trigger='click' hx-target='#out'
get -> 'redir' {
endpoints('greet-path').redirect-to: :name<ok>
}
call(|args) invokes the underlying route implementation. Literal path segments are auto-injected; you pass only the non-literal parameters.
get my sub ret('ret') { 42 }
get my sub sum('sum', Int $a, Int $b) { $a + $b }
endpoints('ret').call; # 42
endpoints('sum').call(2, 3); # 5
Great for unit tests of pure route logic. If you depend on Cro’s pipeline, prefer Cro::HTTP::Test.
See examples/example.raku and examples/ExampleRoute.rakumod in the repo. Run:
raku examples/example.raku
Then visit:
/form for a classic form/links for <a href> links built from endpoints/links-htmx for HTMX-driven linkscall() auto-injects literal path segments; you provide the rest.Cro focuses on routing and request handling. This utility adds “endpoint as a value” ergonomics—stable references, typed path building, HTMX helpers, and redirect/call helpers—while staying a thin layer on top of Cro::HTTP::Router.
# examples/ExampleRoute.rakumod
use Cro::HTTP::RouterUtils;
sub other-routes is export {
route {
get my sub external-ep1("returns-ok") { content "text/plain", "OK" }
post my sub external-ep2("using-post") { content "text/plain", "OK" }
}
}
# elsewhere
include external => other-routes;
endpoints('external-ep1').path; # "/external/returns-ok"
endpoints('external-ep2').path; # "/external/using-post"
—
Made with Cro::HTTP::RouterUtils (Raku).
Precise code search and transformation for Raku
Raku’s RakuAST opens up a powerful way to analyze and transform code by working directly with its Abstract Syntax Tree (AST). ASTQuery builds on that by offering a compact, expressive query language to find the nodes you care about,
capture them, and even drive compile-time rewrites.
This guide explains:
RakuAST::Call,
RakuAST::ApplyInfix, RakuAST::Var, and more.my $ast = $code.AST; for strings, or $*CU for the current compilation unit in a CHECK phaser.rw on your Rakudo; rebuild/replace enclosing
nodes when needed.CHECK phaser with use experimental :rakuast; to inspect/modify $*CU before runtime.$*CU
2) Query nodes with ASTQuery
3) Mutate nodes (or rebuild if fields aren’t rw)
(How mutable RakuAST needs to be is still being discussed)Example: Add '!!!' at the end of every say call.
use experimental :rakuast;
use ASTQuery;
CHECK {
my $ast = $*CU;
for $ast.&ast-query(Q|.call#say|).list {
.args.push: RakuAST::StrLiteral.new: "!!!";
}
}
say "some text"; # prints "some text!!!"
• Query language: Describe node kinds, relationships (child/descendant/ancestor), and attributes succinctly.
• Captures: Name nodes you want to retrieve with $name.
• Functions: Reusable predicates referenced with &name.
• Programmatic API: ast-query and ast-matcher.
• CLI: Query files and print results in a readable form.
use ASTQuery;
my $code = q:to/CODE/;
sub f($x) { }
f 42;
say 1 * 3;
CODE
my $ast = $code.AST;
# Find Apply operator nodes where left=1 and right=3
my $ops = $ast.&ast-query('.apply-operator[left=1, right=3]');
say $ops.list;
# Find calls that have an Int somewhere under args
my $calls = $ast.&ast-query('&is-call[args=>>>.int]');
say $calls.list;
Node description format:
RakuAST::Class::Name.group#id[attr1, attr2=attrvalue]$name&function
Components:
• RakuAST::Class::Name: Optional full class name.
• .group: Optional node group (alias to multiple classes).
• #id: Optional id value compared against the node’s id field (per-type mapping).
• [attributes]: Optional attribute matchers (see below).
• $name: Optional capture name (one per node part).
• &function: Optional function matcher (compose with AND when multiple).
Relationship operators:
• >: Left has right as a child.
• >>: Left has right as a descendant, skipping only ignorable nodes.
• >>>: Left has right as a descendant (any nodes allowed between).
• <: Right is the parent of left.
• <<: Right is an ancestor of left, skipping only ignorable nodes.
• <<<: Right is an ancestor of left (any nodes allowed between).
• Note: The space operator is no longer used.
Ignorable nodes (skipped by >>/<<):
• RakuAST::Block, RakuAST::Blockoid, RakuAST::StatementList,
RakuAST::Statement::Expression, RakuAST::ArgList
Attribute relation operators (start traversal from attribute value when it is a RakuAST node):
• [attr=>MATCH] child
• [attr=>>MATCH] descendant via ignorable nodes
• [attr=>>>MATCH] descendant (any nodes)
Attribute value operators (compare against a literal, identifier, or regex literal):
• [attr~=value] contains (substring) or regex match
• [attr^=value] starts-with
• [attr$=value] ends-with
• [attr*=/regex/] regex literal
Notes:
• When an attribute holds a RakuAST node, the matcher walks nested nodes via configured id fields to reach a comparable
leaf (e.g., .call[name] → Name’s identifier).
• Non-existent attributes never match.
Captures:
• Append $name to capture the current node part, e.g., .call#say$call then access with $match<call>.
Functions:
• Use &name to apply reusable predicates; multiple functions compose with AND.
Common groups:
• .call → RakuAST::Call
• .apply-operator → RakuAST::ApplyInfix|ApplyListInfix|ApplyPostfix|Ternary
• .operator → RakuAST::Infixish|Prefixish|Postfixish
• .conditional → RakuAST::Statement::IfWith|Unless|Without
• .variable, .variable-usage, .variable-declaration
• .statement, .expression, .int, .str, .ignorable
Built-in &functions:
• &is-call, &is-operator, &is-apply-operator
• &is-assignment, &is-conditional
• &has-var, &has-call, &has-int
See REFERENCE.md for the full, authoritative list of groups, functions, and id fields.
• Each RakuAST type maps to an “id field” used for #id comparisons (e.g., RakuAST::Call uses name, RakuAST::Infix uses
operator, literals use value).
• When comparing attributes whose value is a RakuAST node, ASTQuery walks down by id fields until reaching a leaf value
to compare.
• For variable declarations, bare ids strip sigils for comparison:
• .variable-declaration#x matches my $x, even though the declaration’s name includes the sigil internally (if needed, you can always use [name="$x"]).
Find specific infix applications (left=1, right=3):
my $code = q{
for ^10 {
if $_ %% 2 {
say 1 * 3;
}
}
};
my $ast = $code.AST;
my $result = $ast.&ast-query: Q|.apply-operator[left=1, right=3]|;
# ast-query returns a ASTQuery::Match object
say $result.list;
If you print the object itself, instead of getting the list of matched nodes, it will print something like this:

Use ancestor operator <<< with captures:
my $result = $ast.&ast-query('RakuAST::Infix <<< .conditional$cond .int#2$int');
say $result.list; # infix nodes
say $result.hash; # captured 'cond' and 'int'

Parent operator < and capturing:
my $result = $ast.&ast-query('RakuAST::Infix < .apply-operator[right=2]$op');
say $result<op>; # ApplyInfix nodes with right=2
Descendant operator >>> and capturing a variable:
my $result = $ast.&ast-query('.call >>> RakuAST::Var$var');
say $result.list; # call nodes
say $result.hash; # captured 'var'
Attribute relation traversal (from attribute node):
# Calls that have an Int somewhere under args:
my $calls = $ast.&ast-query('&is-call[args=>>>.int]');
Attribute value operators:
# Calls whose name contains "sa" (e.g., say)
my $q1 = $ast.&ast-query('.call[name~= "sa"]');
# Calls whose name starts with "s"
my $q2 = $ast.&ast-query('.call[name^= "s"]');
# Calls whose name ends with "y"
my $q3 = $ast.&ast-query('.call[name$= "y"]');
# Calls whose name matches /sa.*/
my $q4 = $ast.&ast-query('.call[name*=/sa.*/]');
Capturing and retrieving nodes:
my $m = $ast.&ast-query('.call#say$call');
my $call-node = $m<call>;
my @matched = $m.list;
Register a function and use it via &name:
• From a compiled matcher:
my $m = ast-matcher('.call#f');
new-function('&f-call', $m);
$ast.&ast-query('&f-call');
• From a callable:
new-function('&single-argument-call' => -> $n {
$n.^name.starts-with('RakuAST::Call')
&& $n.args.defined
&& $n.args.args.defined
&& $n.args.args.elems == 1
});
$ast.&ast-query('&single-argument-call');
• From a selector string:
new-function('&var-decl' => '.variable-declaration');
$ast.&ast-query('&var-decl');
• ast-query($ast, Str $selector) / ast-query($ast, $matcher): Run a query and get an ASTQuery::Match (acts like
Positional + Associative).
• ast-matcher(Str $selector): Compile a selector once and reuse it.
• new-function($name, $callable|$matcher|$selector): Register &name.
• add-ast-group($name, @classes) / add-to-ast-group($name, *@classes): Define/extend group aliases.
• set-ast-id($class, $id-method): Configure which attribute is used as the id for #id and nested value matching.
• Run against a directory or single file:
• ast-query.raku 'SELECTOR' [path]
• If path is omitted, it scans the current directory recursively.
• Extensions scanned: raku, rakumod, rakutest, rakuconfig, p6, pl6, pm6.
• Example:
• ast-query.raku '.call#say >>> .int' lib/
• Set ASTQUERY_DEBUG=1 to print a colored tree of matcher decisions, including deparsed node snippets and pass/fail per
validator step. This helps understand why a node matched—or didn’t.
• RakuAST is experimental. It's still being discussed how mutable it will be.
• Regex flags in /.../ literals aren’t supported in attribute value operators yet.
• The old “space operator” for relationships is deprecated; use the explicit operators (>, >>, >>>, <, <<, <<<).
ASTQuery lets you describe meaningful shapes in RakuAST—calls, operators, variables, and more—compose those
descriptions, capture the nodes you want, and apply them to everything from precise code search to automated
compiler-time refactorings. It’s a compact tool for robust code understanding and transformation.
• Repo: https://github.com/FCO/ASTQuery
• See REFERENCE.md for the complete catalog of groups, built-in functions, and id fields.
The Elucid8 system can be used to create websites based on RakuDoc. The article is to show how to create a minimal website.
Elucid8 ("elucidate") is still being developed, and more information can be found in the Github elucid8-org repositories.
The following need to be present:
zef install Elucid8::Build
zef install Elucid8::Run-locally
Assuming that the zef installs bin/ files to a location in the PATH, then the utilities in the next section should run without problem.
In an empty directory (to be concrete, lets call it webdir), which will be the root for the website build, run the following
elucid8-setupgather-sourceselucid8-buildrun-locallyThen point a browser at localhost:5000
That is all for the minimum site.
Now change the file site-source/en/index.rakudoc.
Then run elucid8-build; run-locally again to see the changes.
Here elucid8-setup copies resources in the Elucid8::Build distribution to create the minimal configuration entries in webdir,
a sample text and some minimal plugins.
The directory structure under webdir will be something like
- config/
- 01-base.raku
- 02-plugins.raku
- 03-plugin-options.raku
- 04-repos
- misc/
- site-sources/
- en/
- index.rakudoc
- examples.rakudoc
Since Elucid8 is being built from the bottom up to be multi-lingual, it is intended that all of these directories can be named in a local variation. The file
config/01-base.rakucontains the tokens that are used within Elucid8::Build.
It is intended that each set of language sources will be in a different repo. gather-sources looks at config/04-repos for files and repo information, clones repositories, runs git blame against them and stores a file description in misc/.
After this step, website will contain the file misc/repo-info.rakuon.
For the minimal website, the RakuDoc v2 specification is pulled from the Raku repository. This document also shows many of the features of RakuDoc.
The config/04-repos shows an example of how to map documents from the repository to subdirectories within publication.
At this step, the build process starts. A processor engine is created that uses the plugins described in config/02-plugins. These are run with options described in config/03-plugin-options.
After this step, misc/ also contains ui-dictionary.rakuon, which will have the English version of the UI tokens. When this dictionary is appropriately edited, other languages will be available.
Elucid8 makes a distinction between the language of the UI and the language of the contents.
A new directory publication/ has now appeared, and this will contain the HTML version of the index file.
At this step, a Cro app is run that takes the HTML in publication and serves the files to localhost:3000.
There are many ways to customise the site:
config/03-plugin-options and the root-domain field of SiteMap, so that the SEO map points to your website.index.rakudoc all the other RakuDoc sources in your local-sources/ directory.Examples of what can be done can be seen in Sandpit repo, for Raku documentation
⚠️ Note: This is a personal experiment. I’m not experienced in game development or ECS, and I’ve only recently learned about these concepts. This framework is not production-ready, and the API is still in flux. But I’d love your feedback! 🙏
ECS stands for Entity-Component-System, a popular architecture pattern in game development.
Instead of having objects with both data and behavior (like in OOP), ECS separates those concerns cleanly. It encourages data-driven design and enables powerful querying and parallelism (though we’re far from that in this toy project).
This ECS implementation uses the concept of archetypes, which means:
Entities are grouped by the exact combination of components (and optionally tags) they have.
This means the world knows: "All entities with position and velocity, but not health are in this group."
This makes querying more efficient and predictable — we only iterate over relevant entities per system.
Archetypes are typically used in high-performance ECS engines (like Unity’s DOTS or Bevy in Rust), but here it also simplifies reasoning about how entities are grouped.
Recently, I came across the idea of Entity Component System (ECS) architectures, and it instantly clicked with my love for declarative APIs and composable logic.
So I decided to implement a minimal ECS framework in Raku — not for performance or production use, but just to explore the paradigm and learn from it. And who knows? Maybe others in the Raku community will enjoy hacking on it too.
Here’s a simple bouncing animation built with this ECS framework and Raylib::Bindings:

Here’s the full example:
use Raylib::Bindings;
use ECS;
constant $screen-width = 1024;
constant $screen-height = 450;
my $white = init-white;
my $background = init-skyblue;
init-window($screen-width, $screen-height, "Bouncing Camelias");
my $string = "./camelia.png";
my $camelia = load-image($string);
my $camelia-height = $camelia.height;
my $camelia-width = $camelia.width;
my $camelia-pos = Vector2.init: $camelia-width/2e0, $camelia-height/2e0;
my $texture = load-texture-from-image($camelia);
unload-image($camelia);
set-target-fps(60);
END {
unload-texture($texture);
close-window;
}
# We define a few basic vector operators to help with math:
sub term:<vector2-zero> { Vector2.init: 0e0, 0e0 }
multi infix:<+>(Vector2 $a, Vector2 $b) { Vector2.init: $a.x + $b.x, $a.y + $b.y }
multi infix:<->(Vector2 $a, Vector2 $b) { Vector2.init: $a.x - $b.x, $a.y - $b.y }
multi infix:<*>(Vector2 $a, Numeric $i) { Vector2.init: $a.x * $i, $a.y * $i }
multi infix:</>(Vector2 $a, Numeric $i) { Vector2.init: $a.x / $i, $a.y / $i }
# Then comes the fun part: defining the ECS world.
my $world = world {
component position => Vector2;
component velocity => Vector2;
entity "camelia";
# Input system: spawn a new “camelia” on mouse click
system "click", :when{is-mouse-button-pressed MOUSE_BUTTON_LEFT}, -> {
world-self.new-camelia:
:position(get-mouse-position - $camelia-pos),
:velocity(vector2-zero),
;
}
system-group "input", <click>;
# Movement, gravity and bounce logic
system "move", -> :$position! is rw, :$velocity! {
using-params -> Num $delta {
$position += $velocity * $delta
}
}
system "bounce", -> :$position! where *.y >= $screen-height - $camelia-height.Num, :$velocity! where *.y > 0 {
$velocity.y *= -.8
}
system "gravity", -> :$velocity! {
using-params -> Num $delta {
$velocity.y += 100 * $delta;
}
}
system-group "physics", <move gravity bounce>;
# Draw each camelia
system "draw", -> :$position! {
draw-texture-v $texture, $position, $white;
}
}
system "draw", -> :$position! {
# And finally the game loop:
until window-should-close {
$world.input;
$world.physics: get-frame-time;
begin-drawing;
clear-background $background;
$world.draw;
draw-fps 10, 10;
end-drawing;
}
world
The world function is the entry point to define your ECS universe. Inside it, you declare your components, entity types, systems, and system groups. It returns an object that you will use to create entities and run your systems.
component
The component function defines a component that entities can have. You can call it in two ways:
component position => Vector2;
Or more concisely
component Color;
In the second case, the name of the component will be automatically derived from the type by converting it to kebab-case (e.g., Color becomes "color"). This helps reduce repetition when the type name already describes the data well.
The entity function defines a named entity type. This name becomes a tag automatically added to all instances of that entity. For example:
entity "ball";
After this, you can create new entities with $world.new-ball(...), and those entities will be tagged with "ball".
The system keyword defines a system — a unit of logic that processes entities. By default, a system automatically performs a query based on its parameters: it runs once per entity that has all the required components and tags.
For example:
system "gravity", -> :$velocity! { ... }
This system runs once per frame for each entity with the velocity component.
However, if you pass a :condition or :when parameter, the system behaves differently: it no longer queries entities, and runs only once per frame (or tick), executing only when the condition is true. This is ideal for global events like input, timers, or other non-entity-specific logic.
Example:
system "click", :when { is-mouse-button-pressed MOUSE_BUTTON_LEFT }, -> {
...
}
This system executes once per frame only if the left mouse button is pressed.
The system-group function defines a reusable group of systems. This allows you to bundle related systems and execute them together. You can call the group like a method, optionally passing arguments that will be forwarded to any using-params blocks inside the systems.
Example:
system-group "physics", <move gravity bounce>;
...
$world.physics: get-frame-time;
The using-params function allows a system to access parameters passed when the system or system group is invoked. This is useful for values like frame delta time or external input.
Example:
system "gravity", -> :$velocity! {
using-params -> Num $delta {
$velocity.y += 100 * $delta;
}
}
Here, the system needs a time delta value to apply acceleration due to gravity. It gets the value passed to the system group (e.g., physics: get-frame-time).
Inside a system or query, you can call current-entity to get the entity object currently being processed. This is useful for adding or removing tags or other manipulations.
Example:
if some-condition {
current-entity.add-tag: "jumping";
}
This gives you fine-grained control over the entity’s state and behavior beyond component data.
world-self
Inside a system or query, world-self gives you access to the current world instance. You can use it to create or modify entities, trigger systems, or manage state globally.
Example:
world-self.new-ball: :position(...), :velocity(...);
This allows a system to spawn new entities as part of its logic.
Here are some things you should know:
Nothing is fixed. The API might change. This is just the beginning of a small experiment. If you’re curious about ECS, or if you have experience with game development and want to help shape a more solid design, please get in touch!
You can find the project here:
Feel free to open issues, create examples, or criticize design decisions.
⸻
Thanks for reading!
I've recently released a new Raku module called Resource::Wrangler. The idea is to provide a simple way to handle a pretty significant roadblock in the way Raku handles resources.
Raku distributions have a %?RESOURCES variable that stores references to the resources that are declared in the resources object defined in META6.json.
However, complications arise even as early as testing. This is because the tests will be compiled outside of the CompUnit and it's the CompUnit that circumscribes the extent %?RESOURCES.
In other words, different CompUnit, different %?RESOURCES.
But even beyond that, something as seemingly straightforward as having a local copy of the resource to hand to a library can be quite convoluted.
Resource::Wrangler to the rescueBy combining Resource::Wrangler with dependency injection, it is now dead simple to bridge the gap between the distribution's CompUnit, code that makes use of that distribution's CompUnit, and the test files.
Resource::Wrangler utilizes role parameterization, a sort of hyper-flexible Raku-soaked take on implementing "generics" while adding a lot of characteristic spice to the possibility space.
Here is an example directly from the test suite:
class Resourceful {
has $.resources handles <AT-KEY> =
Resource::Wrangler[{ %?RESOURCES }].new;
}
The most sensible default for parameterizing Resource::Wrangler is { %?RESOURCES }, i.e. a block that returns the %?RESOURCES of the current CompUnit.
Resource::Wrangler implements AT-KEY to expose associative indexing to %?RESOURCES, allowing Resourceful to do the same by declaring that $.resources handles <AT-KEY>. This will be demonstrated in the example below.
But then when we go to test, we can set our own Str => IO pairs for Resource::Wrangler to reference:
my %resources = test => "/tmp/test".IO;
my $resourceful = Resourceful.new:
resources => Resource::Wrangler[-> { %resources }].new;
is "/tmp/test".IO, $resourceful<test>, "Dependency injection works as expected";
Note that the block here needs a signature so as not to be mistaken for a single-argument "hash from a hash" initialization by Raku's grammar. Since %?RESOURCES is actually an object rather than a "proper" hash, it doesn't need this special treatment.
I wrote this library to address some obstacles in another project entirely, one which should have significant examples of relatively complex use of Resource::Wrangler.
Until then, thanks for reading.
Recently on IRC someone asked how to add methods to basic types, which reminded me of an old experimental project of mine: Protocol. Its goal is to explore a structural style of interface in Raku—distinct from Raku’s nominal roles—echoing how Go’s interfaces work by method shape rather than explicit declaration.   
Raku roles are nominal: you explicitly compose (does) a role to promise a bundle of behavior; roles package partial behavior for reuse and are mixed in at compile- or run-time.   
Go interfaces are structural: any type whose method set matches the interface implicitly satisfies it—no prior annotation—providing “if it quacks…” flexibility with static checking.   
Structural typing differs from duck typing: structural typing is verified statically (at compile/analyze time), while duck typing relies on runtime method availability.   
Originally, declaring a protocol like:
use Protocol;
protocol Nameable {
method name { ... }
}
created a subset of Any that type-checks values by verifying the presence of a name method (the ... yada marks a required placeholder).   
Subsets in Raku re-dispatch to their base type but enforce constraints at assignment / parameter binding; Protocol leveraged that to express a structural “has-method(s)” check without nominal composition.   
At first, providing concrete method bodies inside a protocol (i.e. anything other than yada) was disallowed—protocols were strictly about requirements.   
In practice you often want lightweight structural acceptance plus helper / default methods that build upon the required minimal surface (a pattern familiar from roles’ default methods or convenience wrappers around Go interface method sets).   
If a protocol now includes any concrete method bodies, Protocol generates a class (instead of only a subset) so those methods can be mixed in via coercion when needed.
use Protocol;
protocol Nameable {
method name { ... } # required
method description {
[
"Type: { $.^name }",
"Name: { $.name }"
].join: "\n"
}
}
This Nameable now packages both a structural requirement (name) and a concrete helper (description) that becomes available after coercion/mix-in.   
ProtocolSubset
Need only to assert “this value has method name” (no helper methods)? Parameterize with ProtocolSubset:
my Nameable[ProtocolSubset] $with-name = Person.new: :name<Fernando>;
This uses subset semantics: compile/runtime binding checks ensure the method’s existence, while the underlying object remains unchanged and un-augmented.   
ProtocolCoerce
To use helpers like .description, request coercion:
sub print-description(Nameable[ProtocolCoerce] $_) {
say .description;
}
ProtocolCoerce mixes in the generated class so its concrete methods become callable—conceptually similar to mixing a role into an instance on demand.   
Raku’s mixin mechanism produces a new (reblessed) object when adding roles/mixins; the coerced value your function receives may differ in identity from the original variable, though it forwards behavior/state as defined by Raku’s mixin metaobject and caching rules.   
ProtocolSubset) validates method presence without retrofitting roles into legacy or 3rd-party types.   ProtocolSubset) and augmentation (ProtocolCoerce) avoids hidden behavior changes.   mixin patterns in the ecosystem, easing conceptual load.   | Goal | Raku Role (Nominal) | Go Interface (Structural) | Protocol |
|---|---|---|---|
| Require methods | Consumer does role; nominal link |
Any type with matching method set | Subset check: structural (ProtocolSubset) |
| Add helper methods | Role can define defaults | Helpers usually on concrete type | Concrete methods in protocol ⇒ coercible class |
| Retroactively apply w/out editing source | Mix role (instance/class) | Implicit satisfaction | Structural subset + optional coercion |
| Avoid nominal coupling | No (explicit name) | Yes (implicit) | Yes (shape-based check) |
| Opt-in behavior augmentation | Role mixin | Not via interface itself | ProtocolCoerce parameter |
Each cell reflects documented capabilities of roles, subsets, mixins, and structural interfaces.   
A Go value satisfies an interface automatically if it implements the interface’s method set—no implements clause—enabling decoupled design and interface-oriented APIs; this is a compile-time structural check distinct from dynamic duck typing.   
Community discussions and educational material reiterate the static structural nature (and its contrast with duck typing) emphasizing that interface satisfaction is derived from shape not explicit declarations.   
Nameable[ProtocolSubset] where you just need a guarantee the argument responds to .name.Nameable[ProtocolCoerce] when you also want .description (or other helper methods) to exist via a safe mixin/coercion process.
These steps leverage Raku’s subset validation and mixin metaobject to approximate Go-like structural acceptance with optional augmentation.   Protocol aims to blend Go-style structural typing’s flexibility with Raku’s powerful role, subset, and mixin machinery—cleanly separating validation (ProtocolSubset) from augmentation (ProtocolCoerce) so you can retrofit interfaces onto existing code while progressively layering reusable helper behavior.   
Recently I've been exploring two programming languages that live well outside the current mainstream but which in past eras of computing have existed much closer -- or directly inside of -- a previous mainstream.
Despite of their decreased visibility today, these languages -- APL and Eiffel -- represent incredible and currently relevant achievements in language design. They also provide unique programming styles in a holistic fashion that my primary personal language Raku does not. 1
APL and Eiffel continue to provide significant value for their users today and thus are also of interest to me by fact that their continued existence is maintained through sheer commercial viability.
Without software companies supporting various commercial implementations, both of these languages would have "died" out years ago. And yet, they did not.
The experience of finding what I consider to be potentially priceless gems just hiding out in plain sight has reminded me of other moments in my life where I have followed my heart and ended up ahead of the curve.
So please, if you will, let me take you on a shopping trip for eyeglasses in the summer of 1999...
I've always been terrible at conforming. Even during my not-so-non-conformist-after-all phase, those early teen years of Hot Topic and JNCO 32" cuff jeans, I was crap at fitting in with the other outcasts.
For me, buying a pair of the thickest black frames I could find in the shop the summer before my second year of high school was the punkest move I could pull at the time. Let yourk inner freak fly regardless of what anyone thinks, that sounds like it should be punk, right?
So, my reasoning went, wouldn't it be punk for me to embrace my dorky side?

It may surprise some readers today, but I was not the only one who thought that these and other "frameless" styles were dope in the late 90s.
This was at the very, very earliest phase of thick (or even plastic of any kind) glasses frames coming back into fashion -- and the word 'hipster' had not yet been revived as a label because the fashion and lifestyle that would become the stereotype was only just beginning. (Crotchety old man voice: "Back in my day, 'hipster' still referred to a subculture from the 50s and 60s who inspired the Beat poets.")
The reason I wanted those glasses: I wanted to physically embrace my decision to go full nerd my sophomore year (I failed spectacularly but that's a story for later).
During a re-watch of Apollo 13 at a farmhouse in Iowa after dropping my sister off for her second year of college, I noticed how dope all the dudes in the control center looked in their solid black frames. I vowed to pick the thickest pair I could find.

Here is a photo from the real command center during Apollo 13. Look at those tough ass frames!
For those that don't remember or weren't there, the glasses aesthetics in the 90s were almost entirely about disappearing the frames. When I showed up on my first day of school as a sophomore, I got reactions above what I was expecting -- and not in a good way.

Special Agent Dana Scully with a "no-nonsense nerd" look that shows off the way the fashionable frame game was done in the 90s.
I never showed up to Henderson with a face tattoo or a mohawk but I think at least in those cases there would have been some degree of fear or respect in the looks of shock and distaste I encountered.
In just a few short years my choice would become the height of fashion but in those first trips through the crowded hallways between classes I can promise you that no one considered these glasses on my face to be fashionable. I remember my punkest friend at the time laughing behind his hand and pointing at me.
"But I don't get it," I would later ask him, "I thought that doing something so non-conformist would be a punk move."
I can't remember what he said, just his head shaking at my naivete.
Then again, hadn't it been me who wanted to put a big flashy nerd signal on my face in the first place?
"What did you expect would happen?", he asked, at some point during that conversation.
I realized I didn't know. I had definitely chosen those glasses as a statement and so reactions from people were to be expected.
I realized I wasn't so shocked or upset about the reactions from the people who hadn't respected me before that day.
It was getting shit on by the so-called non-conformists (and so-called friends, at that) that had been unexpected.
Need proof? If you were able to stand on two legs on US soil at the time, I am betting you can still viscerally remember the year where everyone -- including you -- danced the Macarena non-stop. (No joke, there was no way to escape that year without some person or event forcing you to participate in a round of La Macarena.)

This post is already getting quite long so I will leave a deeper examination of this topic for another time. It may or may not involve juicy corporate failure analysis when it arrives.
Just deciding to want thick black frames in 1999 didn't guarantee that you would have access to them. I visited half a dozen glasses shops before I found that first pair of jet black retro-60s Calvin Kleins.
I wasn't searching out these frames because I wanted to latch onto some upcoming or popular fashion, just like I wasn't following anyone else I knew in high school when I went searching out old classic albums in the local record shop. I'm not saying I was the only one buying records in that school of 1600+ students. But I can say for a fact that I was the only one with thick black rimmed eyeglasses in 1999. I still have the yearbook to prove it.
By the time the term 'hipster' came to life, thick frames were commonplace. This should have great for me because my lenses are so extra that sticking them in thin frames amplifies their Coke bottle nature to deafening levels.
But no, I had to be difficult about it.
Thick rim ubiquity, however, diluted the impact of letting my eyeglasses communicating an inner nerdiness. Eventually those magical Calvin Kleins turned gray and broke but by then they were only a backup pair. The popularity of thick frames led me to go move on to different -- and less attractive on me -- thin frames.
This was a stupid mistake but I promise you it was far from the only one I've made for similar reasons.
It is important to mention that dismissing something as unimportant or trivial or wrong just because it is popular has a long history of negative consequences too.
Just one non-spectacles example: I refused to start a blog in 2005 because I considered it to be a saturated space full of vanity projects and definitely too mainstream for me to be able to make an impact or "able to speak my real truth". (What an idiot! - ed.)
Actually, I have. I just maybe haven't yet phrased it in it's most common manifestation: be true to yourself.
I liked records and discovering lost classics (and trash rock, so much dollar bin trash rock), so I bought records. I wanted to look like a nerd from NASA circa 1969, so I looked for the right pair of frames until I found them.
These are far from my only "early arrivals" in terms of fashion, book series, technologies, and the like. I land on these latent-but-soon-to-be-explosive gems for the simple reason that I could care less about whether they are currently perceived as cool.
I've been alive long enough to know that no new solution arrives without delivering the next generation of problems. Your hot framework or language today is going to peak and ebb away as a new generation rebels against your dominance and against the inevitable gaps and flaws in your generation's solutions.
It is highly unlikely that they will either be charitable in their critique or particularly informed about the historical dynamics that led to the constraints that they are now rebelling against. They will almost certainly throw the baby out with the bathwater, leaving themselves exposed to the flaws that will act as seeds of their own cyclical downfall.
What is new, what is cool, these are so transient as to be irrelevant.
If you get a job with a current hot tech stack and you actually enjoy that job enough to remain for five or ten years, when you decide to depart that hot stack will almost certainly be considered a hot pile of crap by a non-trivial segment of "cutting edge" programmers.
Don't take it personally. It is in fact a required aspect of marketing this new current hot tech stack that they paint your previously-viewed-as-revolutionary technologies as untrustworthy garbage.
This is what the old sage types mean when they nod knowingly and say "the blade's edge cuts both ways."
It has taken me a long time to come to a place where I accept myself as capable of making a living on my own, pursuing only my own interests towards only my own ends.
It's an important realization precisely because the sense of all-encompassing despair that I fell into on my way into a multi-year burnout, that despair came from a place of irreconcilable differences between what makes me okay with life and fulfilled as a human being and what a day in a huge corporate office looks like (hint: Hell has an open floor plan).
So, do I want to "climb the ladder" and join some other enormous corporation to spend the major portion of my functionally useful life for the enrichment of a large pyramid of stakeholders that could care less about workers?
Amazingly, as little as these enormous companies seem to ultimately care about their employees (at least relative to the Holier-Than-Life-Itself Bottom Line), it often seems that they care even less about the products they put those workers to use towards.
And I'm supposed to live my life improving software objects, from functions to modules to entire systems, that will never receive the love and attention that they deserve?
A waking life of always either creating the next so-called "Minimum Viable Product" (deceivingly abbreviated as an "MVP"), or working on the un-loved guts of an MVP that was only intended as a quickly-replaced "Proof of Concept" that instead became an unchangeable bedrock of technical debt? -- this being the natural result of impatiently waiting business cases flocking to the "POC" "MVP" and essentially showing management's bluff that anything besides the most bare minimum viability of a product was going to land in production?
No. Thanks for your kind offer, but no.
This moment of self-realization -- of realizing what I don't want -- is usually the first stage of a sequence of events that leads me to a new cool thing before the hype cycle arrives.
I don't believe in "discoveries" or "discoverers" so that's never been what I'm about. I sometimes remark on how I "did it before it was cool" but rarely in an unironic way (this essay outweighs any previous unironic expression by a long mile).
Put another way, I could care less about planting my flag somewhere unless that's a place I actually give a shit about being.
To that end, the programming languages that I will be blogging about are ones that I am using (Raku) and learning about (APL and Eiffel) with a great deal of thought and intention -- and with absolutely zero regard for what's fashionable in software development.
Instead I'm focusing on the many ways that our current approaches are based on largely unconscious choices that are steeped in would-be-comic-if-not-so-tragic cargo cult practices -- choices are made today within a narrow focus and to resemble the choices we made yesterday but this time we will try to do it without the choices we didn't like.
Will it actually solve the issue? Well, the fact that we already have good cause -- thanks to accumulated technical debt -- to patch the whole thing again tomorrow should tell us all we need to know on that front. (Code refactoring targeted at alleviating technical debt is a pinnacle form of crafting the structures of tomorrow to look and act exactly like the structures of yesterday, minus whatever annoyances that we can afford to fix at the moment).
Moments of self-reflection don't need to be rare. Right now I'm only even interested in a continued career in programming if it involves using systems that have a track record of not even being capable of encountering entire categories of problems that I've been facing with mainstream solutions. (These problems can be cultural as well as technical and I look forward to writing more about this topic soon.)
Only time will tell how well I have decided... but I have lived through several reasons to embrace and trust my instincts.
With any luck, this will be another wave of a lifetime.
First-class array programming for APL and design by contract for Eiffel. Raku, the polyglot of programming styles, has plenty of syntax and semantics that are applicable and amenable to these styles -- but that polyglot nature keeps Raku from centralizing them the way they are in APL and Eiffel. I am not saying this is a mark against Raku._↩

A few weeks ago I was chatting with coralina and she linked me 4:19 of The Zipf Mystery but every time he repeats a word it loops.
It's an instance of a meme format I don't think I had seen before. The basic conceit is, as the title states, every time a word that has been said before is said again, the video loops back to that time.
As I interpret it, the instances of words inside of looped sections don't count for determining the "last time" each word has been said, though it's only a little extra work to implement that interpretation as well.
As a Rakunaut it of course didn't take me long to make an attempt at implementing a script that turns a bit of text into the "but every time it repeats a word it loops it repeats the text in between".
After a bit of hacking, I fed the introductory paragraph of the raku website into my script and got the following result. Each time a repetition is done, the word that caused the repetition is printed in red blue, and the repeated text is printed in green:
There's definitely some funny bits in there. My favorites include:
You can help too. The only requirement is Camelia.
You can help too. The only requirement is that you can
help too. The only requirement is that you know how to be developed.
Go to #raku (irc.libera.chat) and someone will be glad to help you know how to be nice to all kinds of people (and butterflies).
I think I might make a recording of reading the text and edit it to do the correct looping, maybe I'll see if Whisper can give precise per-word timestamps that I could turn into a command line with sox or ffmpeg to create the final result.
But for now, I'll go through the actual code I used for this. You can already look at and play with the final version on Compiler Explorer here.
The version I linked to on Compiler Explorer begins with a tiny implementation of Terminal::ANSIColor's sub colored:
The alternative is of course to use Terminal::ANSIColor, but Compiler Explorer doesn't have raku libraries yet. For this case it doesn't really matter that it only supports green and red, and trying to choose any other color just makes no text come out at all 
Oh and to top it off, I accidentally switched the codes for green and red around in the sub, and I have the same switch-around in the code that uses the sub, so both mistakes cancel each other out here. Don't look too closely, haha 
Next is the text we want to put in. Since I was prototyping this with my code editor (vim) and executing it again after making a change, I didn't want to paste the source text in every time. For that reason, the input text is part of the source file, instead of reading from $*IN (aka stdin). It could have gone into a separate file as well just as easily with my @input = "text.txt".IO.words for example.
I chose the Q quoting construct here with square brackets because square brackets aren't in the source text, but using heredocs with Q:to/INPUT-TEXT/ for example would have been just as clean.
In that case, the .words can go directly after the Q while the input text goes below, with indentation if you like, followed by a line with just INPUT-TEXT in it. The .words method makes line wrapping and indentation in the output
Next up, we do a loop over the input array. Using the .pairs method on the array will give us a Pair object each iteration that has a .key with the index of the item and a .value of the word in question.
The result of the for loop goes directly into a result variable. For that purpose, we take the for that by itself is a statement and adapt it into an expression with the do prefix. That lets us put the result of every iteration directly into our array:
You can see that instead of giving a variable to put the pair object into, we just use the default, which is $_, the "topic variable". This lets us refer to .key and .value just like that.
Next up, inside the for loop we declare a state variable to hold information about words we've seen already. A state variable behaves like a variable you declared outside of the loop in terms of keeping values from one round to the next, but is only visible inside of the curly braces. I find that this makes it a bit clearer where the variable belongs. After the loop it is no longer relevant, and trying to address it there is just a case of "undeclared variable".
I mentioned earlier that the .words method gives us a list of consecutive non-whitespace, and that includes punctuation. We don't want the punctuation to be counted when looking up when a word was seen the last time, and also want to count capitalized and lower cased versions of words as the same, so we normalize the words before looking them up or storing them in our %last hash:
We use a simple regex with the .comb method that gives us every alphabetical character from the input, joins them into one string without spaces, and turns it into fold-case (it's kind of like lower case, but different for some scripts.)
The next few lines set up the logic to put the index we saw the word at into the hash. Since we want to get whatever was already in the hash before we assign the new value, we have a few ways to make that happen, but the implementation I chose here is a LEAVE block, which is executed when the body of the loop has finished.
I made the choice to use LEAVE rather than just putting the code at the end of the block because I'm also using the last statement of the loop body to give the value that the for loop puts into the result list.
The block itself is pretty straight-forward:
When leaving the for block, we set the value in %last for the $keyword to the .key, i.e. the index of the word from the input list.
We're almost done! 
We now want to grab a "previous position" from the hash, if it exists, and make the repetition happen. Otherwise, the word just goes straight through to the result:
The with construct lets us check a value for definedness and assign it into a variable for the block.
The if statement can do the same variable assignment, but it checks for truth value. The very first word in our array would have the index 0, which would count as False, and not execute the block.
So for the result of our iteration in case there is a previous position for our keyword should be the word itself, followed by the repeated content. $prevp is the index where the current word was seen before and .key will give us the current index. We use ^.. which creates a Range just like .., but skips the first value.
We use colored for the .value as well as every word we copied out of the @input list with the [] postcircumfix operator to make the first word green and the copied words red respectively.
Now that I've looked at the code again and again for writing this post, it occurs to me that there's not really a good reason to pass every word individually through the colored sub with a map. Instead, I could have turned the list I took out of the @input array into a String joined by spaces, which is conveniently exactly what the .Str method on it would do. That can then be fed into colored and we've saved maybe a third of the whole line.
Ah well, what can you do! I'm not really golfing the code down to the shortest it could possibly be. It would probably look a bit different if I did 
For the case where we didn't actually have an entry in the %last hash yet for the $keyword we would land in the else branch of this construct. We take the value we got into a named variable so that our $_ doesn't get scribbled over. We could still refer to the $_ from the outer block with $OUTER::_ but I thought that's less pleasing.
All that this block needs to do is get the .value out from the pair so it's just the word, and it's done!
Here's the whole loop in one uninterrupted piece:
Now all that's left is to print it out to the terminal.
Just putting the text on the screen as one long string doesn't look good, so I want it word-wrapped. There is a method called naive-word-wrapper on the Str class, however it is marked is implementation-detail.
What that means is that we get no guarantees that it will stay around, or behave the same on a different version of rakudo. It's also not expected to be present on other implementations of Raku. For this use case, I think it's totally fine. If the method is gone, we can just output the string without any wrapping of words, and maybe expect our caller to pipe it through some program that does word wrapping.
Incidentally, when trying that out, I found that neither fmt nor par understand that ANSI color formatting codes have zero visible width when printed 
Even though the naive-word-wrapper implements greedy line wrapping like fmt rather than an algorithm that tries to find a globally optimal solution for how many words should go on each line which par has, the result still looks a lot more correct since it actually strips color formatting codes before doing its calculations 
Again, you can copy out or play with the whole code, put in your own input text, try to make the code shorter, or whatever you like by following this link to Compiler Explorer.
Normally I'd tell you to leave a comment if you liked the post, but I haven't set up anything yet that would make that easy. Maybe soon I will have the experimental Ghost ActivityPub thing running? But until then, you can reply to this toot.
If you don't have an account that can post to the fediverse, you can also find me on IRC, on the raku mailing list, and if there's a discussion on one of the typical social media discussion sites I might see it.
I hope you'll come back when I publish my next post! Don't forget this blog has an RSS feed 

Hi! It's me again, the timotimo you may know & love from the Raku community.
I used to have a blog years ago when I was writing and posting reports for a TPF Grant for the Rakudo / MoarVM profilers, and some other stuff related to Rakudo and MoarVM development.
At some point I stopped taking care of the blog, and shut down the webspace.
Well, I had an export of the blog from back then, so I imported that in this fresh instance of Ghost. Some images, mostly screenshots, didn't make it into the export, unfortunately. The posts are back, and I believe the old URLs are still valid where they were linking to my blog.
I'm also planning to write more posts again in the future, so stay tuned, keep your RSS / ATOM feed reader aimed at my blog, or maybe you're already subscribed to the raku weekly blog, which many of my posts will hopefully be mentioned in 
So for now, take care and you'll read from me soon!
In a previous article, I described how to take a web page source file, edit it, then send the edited source back to Github.
In that post, the authorisation token id-token was one I generated for myself as a Github user. It would also be possible to assign to the hallowed glade (see previous article) an authorisation for a pseudo user or bot specifically set up to take user generated editing.
However, when the edit is merged into the source, the author of the commit would be the bot, and not the author of the edit.
Suppose, though, we want a 'credits' page listing authors and the number of commits they have made. We could run a command in the repo such as:
git log --pretty="%an %n" | sort | uniq -c | sort -n -r
and filter the results into a table. But authors who have entered our hallowed glade will not be listed.
Another concern is spamming. If we require a community user to have a Github identity, then Github will handle authorisation. If there is spamming by a forest troll, it is in Github's best interest to hold that troll to account.
This post explains (mostly to myself) the steps that are needed to insert a login layer.
When I finally got the whole thing working, it was like a weird dance between three different entities. Looking at the documentation for the first time, all the steps seemed odd and unrelated, but once they were all put into motion, there is a logic to the whole thing.
We already have a hallowed glade, which is the suggestion_box server. The server runs in a docker container, and has a Cro server to handle input from a websocket, a Cro client to interact with Github to create a new branch, store the edited file, and raise a Pull Request.
Github allows the owner of a repo to register a 'Github app' and assign it permissions. So, the token granted during the authorisation process is a combination of the permissions of the app and those of a user.
It is always scary for a user to have to authorise someone else to do something on their behalf, so here is what Github says about the authorisation token:
A token has the same capabilities to access resources and perform actions on those resources that the owner of the token has, and is further limited by any scopes or permissions granted to the token. A token cannot grant additional access capabilities to a user. Github authorisation documentation
Here is diagram of the interaction between the browser, the server (in our case suggestion_box) and Github from a great article by Tony on OAuth2:
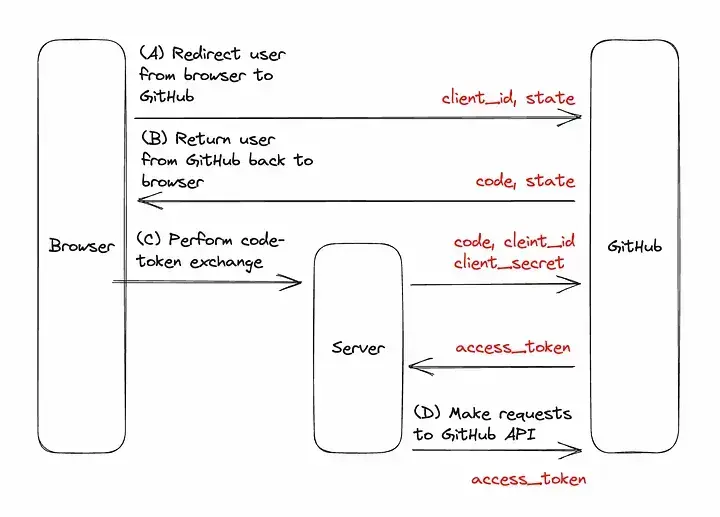
Suppose we add in the request that if an editor wants to make edits on several documents (which means the page is refreshed), then it is inefficient for Github to generate an id-token for each page.
We can keep an object in local storage with the name of the editor and the time the first submission is accepted.
Note that Github issues its web tokens for a fixed period of time, by default 8 hours.
A pre-requisite is that the Github app, which is our suggestion-box is already registered with Github.
The brief laid out above suggests the following series of steps:
editor field in the submission form must be consistent with Github rules:
-, with a minimum of three characters and a maximum of 39. -.state string that contains information for the suggestion_box to be able to issue a successful submission message back to the browser.Inside the suggestion_box server:
In this scheme,
In the previous post, the Cro app had a route for the websocket and a Client section to handle putting suggestions into Github.
We need to modify the Client section to use the editor's id-token, but essentially it remains the same.
We also need to add a route which is used by Github to send login information to the server. In addition, there needs to be a way for the webserver route and the authorisation route to interact.
These modifications imply a shared resource to match editor-name, id-token, id-token expiration date. Since Cro assumes concurrency, the storage has to be thread-safe and ensure that only one thread at a time can access it.
Although the Cro documentation uses
OO::Monitorfor this purpose, I prefer the simplerMethod::Protectedmodule. Theis protectedtrait ensures that only one thread at a time can access the shared resource. For example,
use Method::Protected;
class Editor-Store {
#| has key = editor, with two attributes :token and :time (a Date::Time)
has %!storage;
#| if False, makes sure editor key is deleted
method is-editor-active( $editor --> Bool) is protected {
return False unless %!storage{ $editor }:exists;
return True if %!storage{ $editor }<expiration> > (now.DateTime + Duration.new(10 * 60));
sink %!storage{$editor}:delete;
return False
}
#| if there is no editor, an emptry string is returned
method get-token( $editor --> Str) is protected {
if self.is-editor-active( $editor ) { %!storage{$editor}<token> }
else { '' }
}
#| expiration date
method expiration( $editor ) is protected { %!storage{$editor} }
#| returns the remaining time in seconds as an integer
method time-remaining( $editor --> Int ) is protected {
if self.is-editor-active( $editor ) { ( %!storage{ $editor }<expiration> - now.DateTime).Int }
else { 0 }
}
#| adds editor
method add-editor( Str $editor, DateTime $expiration, Str $token ) is protected {
%!storage{$editor} = :$expiration, :$token;
}
}
The Websocket route of the Cro app needed refactoring completely. Instead of getting all the information for an edit from the browser, typically, the edit suggestion comes first but the editor and their id-token comes later. So the Webocket needs to create a promise and also to put a timer on it.
My first-draft solution is (the code needs to be cleaned up somewhat):
get -> 'suggestion_box' {
web-socket :json, -> $incoming {
supply whenever $incoming -> $message {
my $json = await $message.body;
# first filter out the handshake signal for opening a websocket
if $json<loaded> {
say strftime(DateTime.now, '%v %R') ~ ': connection made'
if $debug;
emit({ :connection<Confirmed> })
}
else {
if $debug {
say strftime(DateTime.now, '%v %R') ~ ': got suggestion, now at ' ~ +@suggestions;
for $json.kv -> $k, $v {
say "KEY $k =>\n$v"
}
say "edit suggestion finished\n";
}
my $response = sanitise( $json ); # sanitise returns an error message or 'ok'
my $editor := $json<editor>;
if $response ne 'OK' {
emit( {
:timestamp( DateTime.now.Str ),
:$response,
:$editor,
})
}
# handle the socket with an active editor
elsif $store.is-editor-active($editor) {
say strftime(DateTime.now, '%v %R') ~ ': editor is registered' if $debug;
# too little time left for token
if $store.time-remaining( $editor ) <= 10 * 60 {
say strftime(DateTime.now, '%v %R') ~ ': not enough time' if $debug;
emit( {
:timestamp( DateTime.now.Str ),
:response<TooLittleTimeOnToken>,
:$editor,
})
}
else {
say strftime(DateTime.now, '%v %R') ~ ': handling with stored token' if $debug;
$json<id-token> = $store.get-token($editor);
@suggestions.push: $json;
emit( {
:timestamp( DateTime.now.Str),
:response<OK>,
:$editor,
:expiration( strftime($store.expiration($editor), '%v %R'))
} )
}
}
# the editor does not have a token, but may have in some period of time
else {
say strftime(DateTime.now, '%v %R') ~ ': editor without authorisation' if $debug;
my $timestamp;
my $response = 'NoAuthorisation';
my $expiration = '';
my $token = '';
my Promise $tapped-out .= new;
my $tap = $see-new-auths.tap( -> %a {
if %a<editor> eq $editor {
$timestamp = DateTime.now.Str;
$response = 'OK';
$token = %a<token>;
$expiration = %a<expiration>;
$tapped-out.keep;
}
});
await Promise.anyof(
$tapped-out,
my $timer = Promise.in($auth-wait-time).then: {
$response = 'NoAuthorisation';
}
).then( { $tap.close } );
if $response eq 'OK' {
$json<id-token> = $token;
@suggestions.push: $json;
say strftime(DateTime.now, '%v %R') ~ ": authorising suggestion {$json.raku}, now at " ~ +@suggestions if $debug;
}
emit( %( :$timestamp, :$response, :$expiration, :$editor) )
}
}
}
}
The $tapped-out Promise is created so that it can be kept with .keep inside the code that listens for an authorisation event.
Then a separate Promise composed of the $tapped-out Promise and a timer Promise is created so that whichever comes first triggers the next step. If the timer exits before an authorisation, then the edit suggestion is discarded, otherwise it is combined with the id-token and queued.
In the code section above, the webserver is a supply and when the emit sub is called, the hash argument is mapped by Cro into a JSON object and returned to the browser that has connected to the Cro app. So it can be picked by the Javascript's websocket's onmessage function, and the data used by the browser program.
When a Github app is registered, a route is supplied for the authorisation data. Consequently, the server section of the Cro app has to be set up to service this route. I chose the route /raku-auth (and in my code comes before the websocket, but since we are dealing with concurrent processes, the order of websocket and raku-auth is irrelevant):
get -> 'raku-auth', :%params {
CATCH {
default {
content 'text/html', '<h1>Raku documentation</h1><p>Authorisation error.</p><p>Please report</p>';
say 'error is: ', .message;
for .backtrace.reverse {
next if .file.starts-with('SETTING::');
next unless .subname;
say " in block { .subname } at { .file } line { .line }";
last if .file.starts-with('NQP::')
}
}
}
my %decoded = from-json( base64-decode( %params<state>).decode );
say strftime(DateTime.now, '%v %R') ~ ': got from Github params: ', %params , ' state decoded: ', %decoded
if $debug;
my $editor = %decoded<editor>;
my $resp = await Cro::HTTP::Client.post(
"https://github.com/login/oauth/access_token",
query => %(
:$client_id,
:$client_secret,
:code( %params<code> ),
),
);
# Github returns an object with keys access_token, expires_in (& others not needed)
my $body = await $resp.body;
my %data = $body.decode.split('&').map(|*.split("=",2));
# first store the data for future suggestions
my $token = %data<access_token>;
my $expiration = now.DateTime + Duration.new( %data<expires_in>);
$store.add-editor($editor, $expiration, $token );
# next put the data in a stream for suggestions that have already arrived
$auth-stream.emit( %( :$editor, :$expiration, :$token ) );
content 'text/html', '<h1>Raku documentation</h1><p>Editing has been authorised.</p><p>Thank you</p>';
}
get -> 'suggestion_box' {
The CATCH phaser is only ever triggered if there is an error processing the route. If it is triggered, then the string after content is sent back to Github, which displays it in the tab containing the authorisation button. The HTML could be improved.
At the end of the code, the content sub similarly sends back an HTML string to indicated authorisation is successful.
When a route has a query appended to it, the Cro route function get captures the data into a named hash, which I have called %params. Github recommends that a state variable is sent when sending the user to Github for authorisation. I have chosen to send the name submitted by the editor with Base64 encoding. Since the editor name in the form and the user's Github id could be different, this adds some complexity to improve security.
I have to say that the Cro syntax is easy to work with. When the data is transmitted as a JSON, there is the named :body field, and with the data is transmitted as a query, there is the named :query field. Otherwise the get sub has a consistent syntax. Compare this to a cURL command.
The parameters sent to the route include a code field, which is then returned (again as a query) to Github. When it receives the code, it returns the id-token for the editor. This two-fold handshake makes it difficult to impersonate someone else.
In addition, Github returns the number of seconds the id-token is valid for. So this needs to be combined into a DateTime both for the suggestion-box server and the browser.
Finally, the editor name, id-token and expiration date are both stored in a thread-safe Hash, and placed in an event stream into which the websocket has tapped.
Raku's concurent structures make it easy to set up the event loop into which the raku-auth route injects information and the websocket listens for information. At the start of the code we have
my $auth-stream = Supplier.new;
my $see-new-auths = $auth-stream.Supply;
As can be seen from the code fragments, the raku-auth route has the line $auth-stream.emit( %(...) ) and the websocket code has the line my $tap = $see-new-auths.tap( -> %a { ... }).
The first stanza supplies an item, in this case as hash, while the second listens for all items supplied. The second then determines which item to react to.
One of the pieces of data required by a Github app is a 'secret' for the app. There are also several items to be provided to the Cro app.
Since this Cro app is intended for a docker container, the configuration data is conveyed in Environment variables. So at the start of the app, several secret variables are extracted as (just an example here):
my $client_id = %*ENV<CLIENT_ID>;
and these data can be temporarily saved in an environment file env-file. Then when the docker image is invoked the data can be supplied:
sudo docker run -d --rm --env-file env-file my-docker-image
As can be seen from the diagram above, getting authorisation is delicate dance, and it took me days to stop the browser, Github and the suggestion-box treading on each others' toes.
First, the interaction between Github and the suggestion-box server to exchange a code for an id-token are all conducted using the query format. That is a url ending ?data-item=stuff&item-two=nonsense, which is in turn Base64 encoded. All the Github API calls use JSON data with authorisation headers.
In hindsight, we can recognise that the OAuth protocol is an industry standard, while the Github API protocols are not, so can be different. But it took me a while to work out what the strange data was being received by the server. I did not come across this behaviour as being explicitly documented.
Second, Github requires that the suggestion-box server is registered by the owner of the repo as a Github app and specific permissions need to be allocated to it. There are dozens of permissions in over a dozen categories and the correct ones have to be given to the Github app. I thought - mistakenly - that the permissions for Pull requests was what I needed.
Actually this was the last bug I had to overcome and it took a couple of days to figure out that the error was not in the server code, but that I had not allocated enough permissions.
To summarise, the suggestion-box server uses four separate Github API calls and the permissions are different:
api.github.com/repos/{$repo-name}/git/ref/heads/main to get the commit sha for the repo-name - this is public data and the permission is mandatory for an App, so it does not need to be specifically addedapi.github.com/repos/{$repo-name}/git/refs (with data) to create a reference - this requires the Contents permission with read/writeapi.github.com/repos/{$repo-name}/contents/{$file-path} to supply the edited - this requires the Contents permissionapi.github.com/repos/{$repo-name}/pulls to create a pull request of the new branch - this requires the Pull Request permissionSome 'simple' requests have complex solutions. Although Cro and Raku's concurrent structures take a while to understand, they are easy to apply.
The ask, expressed by our website users, is simple enough, edit a source from a GitHub repo in a browser, then save the edited version back.
How difficult is that? It's easy to point the browser at the file in the repo, and GitHub has an editor ...
The problem comes from authorisation, and bad actors wanting to add stupid stuff to files - like: I'm the brilliantish shop for high-ent wazzoo's. Come take a look at http://rip-me-off.darkweb.cosmo
Github's editor is easy to use - if you have commit permissions on the repo, otherwise:
But its only one letter!??
Also, our website text source is written in RakuDoc (not MarkDown, but that's another story) and so it would be nice to be able to see what the change looks like. As always a seemingly trivial mistake, such as deleting a < in the wrong place, can have severe effects.
So, it would be nice to see an HTML rendering of the edited text before submitting it back.
It seems doable:
fetch function. Rakuast::RakuDoc::Render into a docker container, wrote a very simple Cro app that has all the logic for a websocket. The app expects RakuDoc source, and sends back the rendered HTML, which is then added into a div next to the online editor. I'll not explain tasks 1-3 above and focus on task 4.
While getting the content is easy, returning it is hard. The API documentation is written for developers who understand Github and HTTP requests.
I spent two days wandering though the API documentation, searching for tutorials, (and Github's own discussion forum seems to be flooded with trolls, so is not a good place to look).
I even resorted - gasp - to ChatGPT. Whilst the code it suggested was not remotely what I wanted, the 'solutions' demonstrated a remarkably simple truth. Perhaps I should have realised it on my own, but in all my documentation searches I had not read a hint about it.
The simple truth: getting a patch of a file to the repo maintainers could only be done in a sequence of steps, not the single step that I was looking for.
It is obvious that Github wants to ensure that only authorised users can change the state of a repo. Authorisation is accomplished by accompanying any request for a change with a token that has a limited duration, is unique to a recognised user on Github, and has permissions for the repo.
While it is possible to get and use such a token for an arbitrary user, by sending them to Github to log in, the process is an added layer of complexity. For simplicity, we shall consider that a token has been generated and call it id-token. (For development, I used one generated for myself)
In generalised terms, here are the steps to sending a suggestion for editing a file to the Github repo. (I'll explain some of the jargon with each step).
Obtain the contents of the file and its sha from repo.
Raku/doc Github storage, where Raku is the organisation that owns the storage, and doc is the repo in which Raku holds its documentation suite.sha is the encrypted sum of the entire file, and is presented as a 40 digit hexadecimal string. The maths of shas is quite interesting but not relevant here. Suffice it to say that if a file is changed at all, the shas of the two files (before the edit and after it) will be different (for the pedantic, I'll add 'with high probability').Obtain the latest sha or commit for the repo.
Create a new branch or reference point in the repo.
Move a copy in BASE64 format of the edited file to the new branch
Raise a PR for the branch
PR is a pull request, and it is a suggestion to the repo maintainer to merge the suggested changes of the file into the main content of the repo.Even though only one letter in one file may need to be changed, the API is set up (reasonably) for many changes to many files.
Can we do this in the browser? Uh, well ... yes, but No.
The problem is that everything in a browser can be examined by the world. So if you put an id-token in a browser, it can be extracted from the browser, and then a bad actor can use the token to do silly stuff.
So, each of the steps above which require an id-token have to be executed from a place that can be defended, such as inside a container where the id-token can be hidden and renewed on a regular basis.
The solution is to create a safe location - hallowed glade - in which the id-token can be stored, and from which the calls to Github can safely be executed.
So let us create a container with a Cro application. The container will have a websocket to accept the edited file from the browser, and then separately interact with Github.
The Cro documentation was written by a genius for developers with experience, unlike me. They are daunting and confusing - it took days of work to figure things out. However, Cro does make it easy to set up the steps listed above.
The first thing to realise is that Cro::HTTP::Client and Cro::HTTP::Server / Cro::HTTP::Router are - at least externally - independent of each other, but we will need both.
We will need the Server to listen for the data coming down the websocket, and then Client to move the edited file to the Github repo.
Since step 1 above is done in-browser, it needs to be implemented in Javascript. I will not deal with that here, except to say, that when the content is fetched from Github, the sha of the file is saved. The in-browser code finally sends along a websocket a JSON object with the following fields:
The last three are not strictly needed, but can be used for some sanity testing.
Lets assume the web socket has a route suggestion_box, then the following is the code for a Cro application to get the data
use Cro::HTTP::Log::File;
use Cro::HTTP::Server;
use Cro::HTTP::Router;
use Cro::HTTP::Client;
use Cro::HTTP::Router::WebSocket;
use DateTime::strftime; # a helper to provide nice time formats
my $patch-limit = 5 * 2 ** 10; # 5k limit of chars
my $comment-limit = 1 * 2 ** 10; # 1k limit of chars
my $pr-update-duration = 10 * 60 * 60; # every ten minutes
my $host = '0.0.0.0';
my $port = 60005;
my @suggestions;
my $busy = False;
my Cro::Service $http = Cro::HTTP::Server.new(
http => <1.1>,
:$host,
:$port,
application => routes(),
after => [
Cro::HTTP::Log::File.new(logs => $*OUT, errors => $*ERR)
]
);
say strftime(DateTime.now, '%v %R') ~ ': starting up.';
$http.start; # this starts the server part of the application
# the following is an asynchronous structure which listens for events
# then does the block for that event. The main event is to stop
# the app when a control signal is raised.
react {
whenever signal(SIGINT) {
$http.stop;
say strftime(DateTime.now, '%v %R') ~ ': closing down.';
done;
}
whenever Supply.interval($pr-update-duration) {
# every pr-update-duration seconds, this block is run
# it calls the code for raising a PR
unless $busy {
$busy = True;
raise-pr( @suggestions.pop ) while @suggestions;
$busy = False;
}
}
}
# these routes are what define the application
sub routes() {
route {
get -> 'suggestion_box' { # the route for the websocket
web-socket :json, -> $incoming {
supply whenever $incoming -> $message {
my %json = await $message.body;
if %json<sha> { # no sha, no play
my $response = sanitise( $json );
# place limitations on the incoming data
# add 'cancel' to ignore data
@suggestions.push: $json.hash.clone
unless $json<cancel>;
# store the data to be sent as PR
emit({
:timestamp( strftime(DateTime.now, '%v %R')),
:$response
})
# send back to the websocket JSON with
# a time stamp and a reponse code
}
elsif $json<loaded> {
# send back a handshake when websocket opens
emit({ :connection<Confirmed> })
}
}
}
}
}
}
sub sanitise( %edit --> Str ) {
my $response = 'OK';
for %edit.keys {
when 'editor' {
%edit<editor> .= subst(/\W/, '_', :g)
.substr( ^21 )
}
when 'patch' {
if %edit<patch>.chars > $patch-limit {
%edit<cancel> = True;
$response = 'TooManyChanges'
}
}
when 'comment' { %edit<comment> .= substr(^$comment-limit) }
when <sha repo content>.any {}
default { %edit{ $_ }:delete }
# remove unwanted fields
}
$response
}
sub raise-pr( %an-edit ) { ... }
The Server code handles all the interaction between the browser and the 'Hallowed Circle'.
Now we execute the remaining steps ( 2 - 5 ) of the Github sequence.
sub raise-pr( %edit ) {
#| Define the secret token. When the container is run,
#| the token can be passed as an environment parameter.
#| Later, we can refactor to obtain it to identify the
#| user making the edits.
my $id-token = %*ENV<ID_TOKEN>;
my $base = 'https://api.github.com/repos';
# create a descriptive branch name
my $branch = strftime(DateTime.now, '%v')
~ "_{ %edit<editor> }";
# get the repo information
my $resp = await Cro::HTTP::Client.get(
"/{%edit<repo>}/git/ref/heads/main"
);
my %data = await $resp.body;
my $commit = %data<object><sha>;
# create a new branch
$resp = await Cro::HTTP::Client.post(
"$base/{%edit<repo>}/git/refs",
content-type => 'application/vnd.github+json',
auth => { bearer => $id-token },
headers => [ X-GitHub-Api-Version => '2022-11-28' ],
body => %(:sha($commit), :ref("refs/heads/$branch"))
);
%data = await $resp.body;
# update file into new branch
$resp = await Cro::HTTP::Client.put(
"$base/{%edit<repo>}/contents/{%edit<path>}",
content-type => 'application/vnd.github+json',
auth => { bearer => $id-token },
headers => [ X-GitHub-Api-Version => '2022-11-28' ],
body => %(
:sha(%edit<sha>),
:$branch,
:content(%edit<content>),
:message(%edit<comment>),
)
);
%data = await $resp.body;
# should check to make sure OK
# Raise a PR for the new branch
$resp = await Cro::HTTP::Client.post(
"$base/{%edit<repo>}/pulls",
content-type => 'application/vnd.github+json',
auth => { bearer => $id-token },
headers => [ X-GitHub-Api-Version => '2022-11-28' ],
body => %(
:title("Web edit of {%edit<path>}"),
:head($branch),
:base<main>,
:body("Edit suggested by 「{%edit<editor>}」 because 「{%edit<comment>」}"),
)
);
}
The Github documentation for the PR was particularly confusing because head, base, and body did not seem to be intuitive taken on their own.
I have documented my journey into and out of the woods using as little jargon as possible. My purpose in doing this was to describe it so I could understand it myself, and also in the hope that the gods of the internet (aka search engines) will guide someone else who may have a similar set of issues.
Naturally, the container is part of a bigger system, and it needs to be tested. But that raises more questions, so I will only be brief.
It is not so easy to test a websocket. My approach was:
localhost.I published my new book: A Language a Day, which is a collection of brief overviews to 21 programming languages.

This book provides a concise overview of 21 different programming languages. Each language is introduced using the same approach: solving several programming problems to showcase its features and capabilities. Languages covered in the book: C++, Clojure, Crystal, D, Dart, Elixir, Factor, Go, Hack, Hy, Io, Julia, Kotlin, Lua, Mercury, Nim, OCaml, Raku, Rust, Scala, and TypeScript.
Each chapter covers the essentials of a different programming language. To make the content more consistent and comparable, I use the same structure for each language, focusing on the following mini projects:
Each language description follows—where applicable—this pattern:
You can find all the code examples in this book on GitHub: github.com/ash/a-language-a-day.
You can buy it on Amazon or LeanPub as an electronic or Kindle edition, or as a paper hardcover or paperback version. More information with the links to the shops.
NOTE: There is an issue when opening existing Comma projects that were created in earlier versions. Please use New project from Existing Sources... rather than Open and make sure to select Yes when it prompts you about overwriting an existing .idea file in the project directory.
This release represents a major shift for the Comma project in many ways.
From the bottom of my heart, I want to express the deepest gratitude and thanks to Jonathan Worthington (jnthn++),
Edument, and all past and future contributors to the Comma project. There's been
so much effort put into this codebase and it was an honor to be able to work on it.
The most major change is the shift to the IntelliJ Platform Gradle Plugin 2.0. This
allows Comma to be built (as a plugin) without cloning the
intellij-community repo and downloading it's entire dependency tree!
This does seem to preclude building Comma as a standalone IDE, at least for the time being. That appears to be a different beast entirely and we will have to investigate that as the time and tuits allow.
Other major changes included updating the code to correct for broken and (some) deprecated
API changes, as well as the significant cosmetic adjustment of migrating Perl6 to Raku.
The latter should be almost entirely finished, but there might be some stragglers that I've
missed.
Building should be as simple as opening this repository in IntelliJ IDEA (using version 2024.2 or greater), and selecting
build > build from the Gradle build target options. Or, for more immediate gratification, you can select intellij platform > runIde.
Update: If you don't feel like building it yourself, you can now simply download the plugin zip from GitHub. From inside IntelliJ IDEA, open the Settings > Plugins, find the gear icon, and select Install Plugin from Disk....
Next steps:
<Your wishlists go here!>Happy hacking! :D
The question has been raised, how to get named arguments into sub EXPORT via a use-statement. The ever helpful raiph provided an answer, which in turn left me with the question, why he didn’t just use a Capture to move the data around. Well, because that doesn’t work. The compiler actually evaluates the expression \(:1a, :2b) into (1, 2) before passing it on to EXPORT.
If it’s hard, do it functional!
# foo.raku
use v6.d;
constant &transporter = sub { \(:1a, :2b); }
use foo &transporter;
# lib/foo.rakumod
use v6.d;
proto sub EXPORT(|) { * }
multi sub EXPORT(&transporter) {
&EXPORT(|transporter);
}
multi sub EXPORT(:$a, :$b) {
dd $a, $b;
Map.new
}The idea is to hand a function to use to be called by EXPORT, and then redispatch the value that is produced by that function, to take advantage of Raku´s excellent signature binding. The proto and refering to sub EXPORT explicitly is needed because there is also a predefined (and in this case hidden) package called EXPORT.
I’m passing on named arguments to EXPORT, but all kinds of stuff could be returned by &transporter. So long as everything is known pretty early on at compile-time. The use-statement is truly an early bird.
As the title states, I made Raku bigger because lol context (that’s how the Synopsis is calling **@) makes supporting feed operators fairly easy. I wonder if Larry added this syntax to Signature with that goal in mind. With PR#5532 the following becomes possible.
<abc bbc cbc> ==> trans('a' => 'x', 'b' => 'i') ==> say();
# OUTPUT: (xic iic cic)Armed with this I can make a script of mine a little simpler.
use MONKEY-TYPING;
augment class IO::Path {
method trans(|c) {
my $from = self.Str;
my $to = self.Str.trans(|c);
self.rename($to) unless $from eq $to
}
}
sub rename-whitespace(IO::Path $dir where *.d){
dir($dir).grep({ .d || .f && .rw })
==> trans("\c[space]" => "\c[no-break space]", "\c[apostrophe]" => "\c[prime]")
==> sub (*@a) { print '.' for @a}();
dir($dir).grep({ .d && .rw })».&?ROUTINE;
}
rename-whitespace('.'.IO);
put '';I don’t like spaces in filenames, as they are often found with audio or video files. Having auto-complete friendly names makes using a CLI less bumpy. By teaching IO::Path to rename files by providing rules, as they are understood by Str.trans, I can use a feed operator to get the job done. (I wouldn’t be surprised to learn, that anonymous subs DWIM here to be emergent behaviour in Raku.)
Having another PR that adds .trans to IO::Path is tempting but requires more thought.
A follow up to the Welsh dragon.
Firing up another localisation
Steps to Ryuu
Comments on the Raku program
More generally about localisation of coding
If you want to make Ryuu better?
In my previous blog about Y Ddraig, I created a localisation of the Raku Language in Welsh. During a recent conversation, someone mentioned there may be interest in a Japanese localisation, so I thought I would try the same techniques.
I do not speak or read or have ever studied Japanese. The localisation given below will be about as clunky and awkward as any can be. I imagine there may be some hilarious stupidities as well.
So to be clear, this article is about a proof of concept rather than a real effort to create a production-ready program.
However, it took me 40 minutes from start to finish, including setting up the github repo.
Since I like dragons, I named the Japanese cousin to Raku 'Ryuu'. It's a whimsy, not to be treated with much seriousness.
Basically I created a github repo, copied my existing Welsh localisation and changed CY to JA, and draig to ryuu.
Within the automation/ directory I used the translation technique explained for Welsh to create the JA file from the template. The translated.txt file needed some manual cleaning, because the English word for has multiple Japanese equivalents. I chose one more or less at random. In addition, Google translate did some strange things to the order of words and numbers in a line.
After adapting the files in the bin/ directory, and installing the distribution with Raku's zef utility, I ran tr2ryuu on the Raku program simple.raku.
A comment about my Welsh blog was that the program in Y Ddraig was not all in Welsh. And here the program is not all in Japanese.
Remember that the user-facing part of a program will be in the language of the user, in this case it is English. However, the coder-facing part of the program will be in the language of the coder. Below, the coder interface is in Japanese (or rather my ham-fisted attempt at Japanese).
The following is the result (which I put in a file called simple.ryuu):
私の $choice;
私の $continue;
私の @bad = <damn stupid nutcase>;
リピート {
$choice = プロンプト "Type something, like a number, or a string: ";
言う "You typed in 「" ~ ($choice ~~ 任意(@bad) ?? "*" × $choice.文字 !! $choice) ~ "」";
与えられた $choice {
いつ "dragon" {
言う "which is 'draig' in Welsh"
}
いつ 任意(@bad) {
言う "wash your mouth with soap"
}
いつ IntStr {
言う "which evaluates to an integer ", $choice
}
いつ RatStr {
言う "which evaluates to a rational number ", $choice
}
デフォルト {
言う "which does not evaluate to a number "
}
}
$continue = プロンプト "Try again? If not type N: "
} まで $continue 当量 任意(<N n>)
What is amazing to me is that when I ran ryuu simple.ryuu, the program ran without error.
The simple.raku program is obviously trivial, but what I wanted to show are some interesting Raku features. Note how I created an array of words with @bad = <damn stupid nutcase>;, and then later I tested to see whether an input word was one of the array elements.
The Raku idiom いつ 任意(@bad) or in English when any( @bad ) compares the topic variable, in this case the input value, with each array element and creates a junction of Boolean results. The 'any' effectively or's the result to collapse the junction.
Junctions are not common in programming languages, so I thought if there would be problems, then it would be there. So I was surprised to find my Raku program works without error in another language.
All the major coding languages are in English. There are, however, coders from all over the world, and the majority of those from non-English speaking nations would have needed to learn English before (or at the same time as) they learnt coding.
We are thus creating a new technological elite: those who can understand English (or some subset of it), and those who cannot. The more coding becomes an essential part of life, the greater the ability divide between coders (who speak English) and non-coders will become.
The aim of localising a programming language is to provide an entry into coding in a form that is more accessible to every human being, whatever their natural language.
However, the aim of this approach is not to eliminate English at every level of complexity, but to provide a sufficiently rich language for most normal coding and educational needs.
In addition, by having a canonical language (Raku, which is based on English) into which all localised languages can be translated, what we get is a universal auxiliary language together with a universality of being able to code.
Having a single auxiliary language means that a non-English speaking person writing in a localised coding language can translate the program with the problem into Raku, have a developer on the other side of the globe find the problem, and suggest a solution in code, then for that solution to be translated back into the local language.
Naturally, a person who wants to learn more about coding, or who needs to delve deeper into the workings of a module, will need to learn English. Learning wider to learn deeper is a normal part of the educational experience.
Ryuu or however it should be called, absolutely is in need of Tender loving care. Please feel free to use the github issues or PR processes to suggest better translations.
At some stage, Ryuu will join the official Raku localisations.
Over on Reddit zeekar wasn’t too happy about Raku’s love of Seq. It’s immutability can be hindering indeed.
my @nums = [ [1..10], ];
@nums[0] .= grep: * % 2;
@nums[0].push(11); # We can't push to a Seq.I provided a solution I wasn’t happy with. It doesn’t DWIM and is anything but elegant. So while heavily digesting on my sofa (it is this time of the year), the problem kept rolling around in my head. At first I wanted to wrap Array.grep(), but that would be rather intrusive and likely break Rakudo itself. After quite a bit of thinking, I ended up with the question. How can I have indexable container (aka Array) that will turn each value on assignment into an (sub-)Array?
my Array() @foo = [ 1..10, ];
dd @foo;
# Array[Array(Any)] @foo = Array[Array(Any)].new($[1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
@foo[0] .= grep: * % 2;
@foo[1] = 42;
dd @foo;
# Array[Array(Any)] @foo = Array[Array(Any)].new($[1, 3, 5, 7, 9], $[42])The answer is obvious. By telling the compiler what I want! Coersion-types have become really hard to distinguish from magic.
I wish you all a Merry Christmas and the very best questions for 2024.
Note: This post is also available as a gist if you find that format more readable.
This research was conducted while preparing an upcoming Raku Advent Calendar post. The Raku code uses a basic supply pipeline to feed $volume objects through a validation stage that requires a CRC32 check before going to the output sink, which prints the processing time of the validation stage.
The "reaction graph" is designed to simulate a stream processing flow, where inputs arrive and depart via Candycane™ queues (that's the name of Santa's Workshop Software's queueing service, in case you weren't familiar).
The entire scenario is contrived in that CRC32 was chosen due to native implementation availability in both Raku and Zig, allowing comparison. It's not an endorsement of using CRC32 in address validation to deliver Santa's, or anyone's, packages.
Also, thanks to the very helpful folks at ziggit.dev for answering my newbie question in depth.
The source code:
At larger volumes, Raku struggles with the initialization speed of the $volume objects that are instantiated. I replaced the native Raku class with one written in Zig, using the is repr('CStruct') trait in Raku and the extern struct qualifier in Zig.
In Zig I use a combination of an arena allocator (for the string passed from Raku) and a memory pool (designed to quicklymake copies of a single type, exactly fitting our use case) to construct Package objects.
Additionally, for Raku+Zig the CRC32 hashing routine from Zig's stdlib is used via a tiny wrapper function.
A --bad-packages option is provided by both Raku scripts, which makes 10% of the objects have a mismatched address/CRC32 pair.
The library tested was compiled with -Doptimize=ReleaseFast.
Batches are repeated $batch times, which defaults to 5.
All results from an M2 MacBook Pro.
This test and its is only intended to reflect the case where an object is constructed in Zig based on input from Raku. It is not intended to be a test of Zig's native speed in the creation of structs.
There is a call to sleep that gives time -- 0.001 seconds -- to get the react block up and running before emitting the first True on the $ticker-supplier. This affects overall runtime but not the batch or initialization metrics.
The speed of Raku+Zig was so fast that the tool used to measure these details (cmdbench) could not find results in ps for the execution because it had already finished. These are marked as Unmeasured.
In the next iteration of this research, there sould be two additional entries in the data tables below for:
| Volume | Edition | Runtime | Batch Time | Initialization | Max bytes |
|---|---|---|---|---|---|
| 10,000 | Raku | 1.072s | 1: 0.146596686s 2: 0.138983732s 3: 0.142380065s 4: 0.136050775s 5: 0.134760525s |
0.008991746s | 180240384 |
| 10,000 | Raku+Zig | 0.44s | 1: 0.010978411s 2: 0.006575705s 3: 0.004145623s 4: 0.004280415s 5: 0.00468929s |
0.020358033s | Unmeasured |
| 10,000 | Raku ( bad-packages) |
1.112s | 1: 0.157788932s 2: 0.149544686s 3: 0.156293433s 4: 0.151365477s 5: 0.147947436s |
0.008059955s | 196263936 |
| 10,000 | Raku+Zig ( bad-packages) |
0.463s | 1: 0.031300276s 2: 0.01006562s 3: 0.010693328s 4: 0.011056994s 5: 0.010770828s |
0.010954495s | Unmeasured |
The Raku+Zig solution wins in performance, but loses the initialization race. Raku is doing a decent showing in comparison to how far it has come performance-wise.
| Volume | Edition | Overall | Batch Time | Initialization | Max bytes |
|---|---|---|---|---|---|
| 100,000 | Raku | 7.163s | 1: 1.360029456s 2: 1.32534014s 3: 1.353072834s 4: 1.346668338s 5: 1.351110502s |
0.062402473s | 210173952 |
| 100,000 | Raku+Zig | 0.75s | 1: 0.079802007s 2: 0.073638176s 3: 0.053291894s 4: 0.05087652s 5: 0.050394687s |
0.05855585s | 241205248 |
| 100,000 | Raku ( bad-packages) |
7.89s | 1: 1.496982355s 2: 1.484494027s 3: 1.497365023s 4: 1.490810525s 5: 1.492416774s |
0.060026016s | 209403904 |
| 100,000 | Raku+Zig ( bad-packages) |
1.076s | 1: 0.16960934s 2: 0.111172493s 3: 0.110844786s 4: 0.113021202s 5: 0.111713535s |
0.051436311s | 242450432 |
We see Raku+Zig take first place in everything but memory consumption, which we can assume is a function of using the NativeCall bridge, not to mention my new-ness as a Zig programmer.
| Volume | Edition | Overall | Batch Time | Initialization | Max bytes |
|---|---|---|---|---|---|
| 1,000,000 | Raku | 68.081s | 1: 13.475302627s 2: 13.161153845s 3: 13.293998956s 4: 13.364662217s 5: 13.474755295s |
0.95481884s | 417103872 |
| 1,000,000 | Raku+Zig | 3.758s | 1: 0.788083286s 2: 0.509883905s 3: 0.492898873s 4: 0.500868284s 5: 0.498677495s |
0.575087671s | 514064384 |
| 1,000,000 | Raku+Zig ( bad-packages) |
75.796s | 1: 14.940173822s 2: 14.632683637s 3: 14.866796226s 4: 15.272903792s 5: 15.027481448s |
0.704549212s | 396656640 |
| 1,000,000 | Raku+Zig ( bad-packages) |
6.553s | 1: 1.362189763s 2: 1.061496504s 3: 1.069134685s 4: 1.062746049s 5: 1.061096044s |
0.528011288s | 462766080 |
Raku's native CRC32 performance is clearly lagging here. Raku+Zig keeps its domination except in the realm of memory usage. It would be hard to justify using the Raku native version strictly on its reduced memory usage, considering the performance advantage on display here
A "slow first batch" problem begins to affect Raku+Zig. Running with bad-packages enabled slows down the Raku+Zig crc32 loop, hinting that there might be some optimizations on either the Raku or the Zig/clang side of things that can't kick in when the looped data is heterogenous.
Dynamic runtime optimization sounds more like a Rakudo thing than a Zig thing, though.
| Volume | Edition | Runtime | Batch Time | Initialization | Max bytes |
|---|---|---|---|---|---|
| 10,000,000 | Raku | 704.852s | 1: 136.588638184s 2: 136.851019628s 3: 138.44696743s 4: 139.777040922s 5: 139.490784317s |
13.299274221s | 2055012352 |
| 10,000,000 | Raku+Zig | 38.505s | 1: 8.843459877s 2: 4.84300835s 3: 4.991842433s 4: 5.077245603s 5: 4.939533707s |
9.375436134s | 2881126400 |
| 10,000,000 | Raku ( bad-packages) |
792.1s | 1: 162.333803401s 2: 174.815386318s 3: 168.299796081s 4: 162.643428135s 5: 163.205406678s |
10.252639311s | 2124267520 |
| 10,000,000 | Raku+Zig ( bad-packages) |
65.174 | 1: 14.41616445s 2: 11.078961309s 3: 10.662389991s 4: 11.20240076s 5: 10.614430063s |
6.778600235s | 2861596672 |
Pure Raku really struggles with a volume of this order of magnitude. But if you add in just a little bit of Zig, you can reasonably supercharge Raku's capabilities.
The "slow first batch" for Raku+Zig has been appearing in more understated forms in other tests. Here the first batch is over double the runtime of the second batch. What is causing this?
This doesn't seem to work. At least, I'm not patient enough. The process seems to stall, growing and shrinking memory but never finishing.
This is a preliminary report in blog post form based on a contrived code sample written for another, entirely different blog post. More data and deeper analysis will have to come later.
Zig's C ABI compatibility is clearly no put on. It works seamlessly with Raku's NativeCall. Granted, we haven't really pushed the boundaries of what the C ABI can look like but one of the core takeaways is actually that with Zig we can design that interface. In other words, we are in charge of how ugly, or not, it gets. Considering how dead simple the extern struct <-> is repr('CStruct') support is, I don't think the function signatures need to get nearly as gnarly as they get in C.
Sussing the truth of that supposition out will take some time and effort in learning Zig. I'm looking forward to it. My first stop will probably be a JSON library that uses Zig. I'm also going to be looking into using Zig as the compiler for Rakudo, as it might simplify our releases significantly.
According to Larry, laziness is a programmers virtue. The best way to be lazy is having somebody else do it. By my request, SmokeMachine kindly did so. This is not fair. We both should have been lazy and offload the burden to the CORE-team.
Please consider the following code.
my @many-things = (1..10).List;
sub doing-one-thing-at-a-time($foo) { ... }
say doing-one-thing-at-a-time(@many-things.all);Rakudo goes out of it’s way to create the illusion that sub doing-one-thing-at-a-time can deal with a Junction. It can’t, the dispatcher does all the work of running code in parallel. There are tricks we can play to untangle a Junction, but there is no guarantee that all values are produced. Junctions are allowed to short-circuit.
This was bouncing around in my head for quite some time, until it collided with my thoughts about Range. We may be handling HyperSeq and RaceSeq wrong.
my @many-things = (1..10).List;
sub doing-one-thing-at-a-time($foo) { ... }
say doing-one-thing-at-a-time(@many-tings.hyper(:degree<10>));As with Junctions doing dispatch-magic to make hyper/race just work, moving the handling to the dispatcher would move the decision from the callee to the caller and, as such, from the author of a module to the user. We can do that by hand already with .hyper.grep(*.foo) or other forms of boilerplate. In Raku-land we should be able to do better and provide a generalisation of transforming calls with the help of the dispatcher.
I now know what to ask Santa for this year.
My version of JSON::Class is now released. The previous post explains why does this worth a note.
Lately, some unhappiness has popped up about Range and it’s incomplete numericaliness. Having just one blogpost about it is clearly not enough, given how big Ranges can be.
say (-∞..∞).elems;
# Cannot .elems a lazy list
in block <unit> at tmp/2021-03-08.raku line 2629I don’t quite agree with Rakudo here. There are clearly ∞ elements in that lazy list. This could very well be special-cased.
The argument has been made, that many operators in Raku tell you what type the returned value will have. Is that so? (This question is always silly or unnecessary.)
say (1 + 2&3).WHAT;
# (Junction)Granted, Junction is quite special. But so are Ranges. Yet, Raku covers the former everywhere but the latter feels uncompleted. Please consider the following code.
multi sub infix:<±>(Numeric \n, Numeric \variance --> Range) {
(n - variance) .. (n + variance)
}
say 2.6 > 2 ± 0.5;
# True
my @heavy-or-light = 25.6, 50.3, 75.4, 88.8;
@heavy-or-light.map({ $_ ≤ 75 ± 0.5 ?? „$_ is light“ !! „$_ is heavy“ }).say;
# (25.6 is heavy 50.3 is heavy 75.4 is heavy 88.8 is heavy)To me that looks like it should DWIM. It doesn’t, because &infix:«≤» defaults to coercing to Real and then comparing numerically.
This could easily be fixed by adding a few more multis and I don’t think it would break any production code. We already provide quite a few good tools for scientists. And those scientists do love their error bars — which are ranges. I would love for them to have another reason to use Raku over … that other language.
This will be a short one. I have recently released a family of WWW::GCloud modules for accessing Google Cloud services. Their REST API is, apparently, JSON-based. So, I made use of the existing JSON::Class. Unfortunately, it was missing some features critically needed for my work project. I implemented a couple of workarounds, but still felt like it’s not the way it has to be. Something akin to LibXML::Class would be great to have…
There was a big “but” in this. We already have XML::Class, LibXML::Class, and the current JSON::Class. All are responsible for doing basically the same thing: de-/serializing classes. If I wanted another JSON serializer then I had to take into account that JSON::Class is already taken. There are three ways to deal with it:
JSON::Class and re-implement it as a backward-incompatible version.The first two options didn’t appeal to me. The third one is now about to happen.
I expect it to be a stress-test for Raku ecosystem as, up to my knowledge, it’s going to be the first case where two different modules share the same name but not publishers.
As a little reminder:
JSON::Class:auth<zef:jonathanstowe> in their dependencies and, perhaps, in their use statement.JSON::Class:auth<zef:vrurg>.There is still some time before I publish it because the documentation is not ready yet.
Let’s 🤞🏻.
I was always concerned about making things easier.
No, not this way. A technology must be easy to start with, but also be easy in accessing its advanced or fine-tunable features. Let’s have an example of the former.
This post is a quick hack, no proof-reading or error checking is done. Please, feel free to report any issue.
Part of my ongoing project is to deal with JSON data and deserialize it into Raku classes. This is certainly a task
for JSON::Class. So far, so good.
The keys of JSON structures tend to use lower camel case which is OK, but we like
kebabing in Raku. Why not, there is
JSON::Name. But using it:
There are roles. At the point I came to the final solution I was already doing something like1:
class SomeStructure does JSONRecord {...}
Then there is AttrX::Mooish, which is my lifevest on many occasions:
use AttrX::Mooish;
class Foo {
has $.foo is mooish(:alias<bar>);
}
my $obj = Foo.new: bar => "the answer";
say $obj.foo; # the answer
Apparently, this way it would still be a lot of manual interaction with aliasing, and that’s what I was already doing for a while until realized that there is a bettter way. But be back to this later…
And, eventually, there are traits and MOP.
That’s the easiest part. What I want is to makeThisName look like make-this-name. Ha, big deal!
unit module JSONRecord::Utils;
our sub kebabify-attr(Attribute:D $attr) {
if $attr.name ~~ /<.lower><.upper>/ {
my $alias = (S:g/<lower><upper>/$<lower>-$<upper>/).lc given $attr.name.substr(2);
...
}
}
I don’t export the sub because it’s for internal use mostly. Would somebody need it for other purposes it’s a rare case where a long name like JSONRecord::Utils::kebabify-attr($attr) must not be an issue.
The sub is not optimal, it’s what I came up with while expermineting with the approach. The number of method calls and regexes can be reduced.
I’ll get back later to the yada-yada-yada up there.
Now we need a bit of MOP magic. To handle all attributes of a class we need to iterate over them and apply the aliasing. The first what comes to mind is to use role body because it is invoked at the early class composition times:
unit role JSONRecord;
for ::?CLASS.^attributes(:local) -> $attr {
# take care of it...
}
Note the word “early” I used above. It actually means that when role’s body is executed there are likely more roles waiting for their turn to be composed into the class. So, there are likely more attributes to be added to the class.
But we can override Metamodel::ClassHOW compose_attributes method of our target ::?CLASS and rest assured no one would be missed:
unit role JSONRecordHOW;
use JSONRecord::Utils;
method compose_attributes(Mu \obj, |) {
for self.attributes(obj, :local) -> $attr {
# Skip if it already has `is mooish` trait applied – we don't want to mess up with user's intentions.
next if $attr ~~ AttrX::Mooish::Attribute;
JSONRecord::Utils::kebabify-attr($attr);
}
nextsame
}
Basically, that’s all we currently need to finalize the solution. We can still use role’s body to implement the key elements of it:
unit role JSONRecord;
use JSONRecordHOW;
unless ::?CLASS.HOW ~~ JSONRecordHOW {
::?CLASS.HOW does JSONRecordHOW;
}
Job done! Don’t worry, I haven’t forgot about the yada-yada-yada above!
But…
The original record role name itself is even longer than JSONRecord, and it consists of three parts. I’m lazy. There are a lot of JSON structures and I want less typing per each. A trait? is jrecord?
unit role JSONRecord;
multi sub trait_mod:<is>(Mu:U \type, Bool:D :$jrecord) is export {
unless type.HOW ~~ JSONRecordHOW {
type.HOW does JSONRecordHOW
type.^add_role(::?ROLE);
}
}
Now, instead of class SomeRecord does JSONRecord I can use class SomeRecord is jrecord. In the original case the win is even bigger.
There is absolutely nothing funny about it. Just a common way to keep a reader interested!
Seriously.
The reason for the yada in that snippet is to avoid a distraction from the primary purpose of the example. Here is what is going on there:
I want AttrX::Mooish to do the dirty work for me. Eventually, what is needed is to apply the is mooish trait as shown above. But the traits are just subs. Therefore all is needed now is to:
&trait_mod:<is>($attr, :mooish(:$alias));
Because this is what Raku does internally when encounters is mooish(:alias(...)). The final version of the kebabifying sub is:
our sub kebabify-attr(Attribute:D $attr) {
if $attr.name ~~ /<.lower><.upper>/ {
my $alias = (S:g/<lower><upper>/$<lower>-$<upper>/).lc given $attr.name.substr(2);
&trait_mod:<is>($attr, :mooish(:$alias));
}
}
Since the sub is used by the HOW above, we can say that the &trait_mod<is> would be called at compile time2.
Now, it used to be:
class SomeRecord does JSONRecord {
has $.aLongAttrName is mooish(:alias<a-long-attr-name>);
has $.shortname;
}
Where, as you can see, I had to transfer JSON key names to attribute names, decide where aliasing is needed, add it, and make sure no mistakes were made or attributes are missed.
With the above rather simple tweaks:
class SomeRecord is jrecord {
has $.aLongAttrName;
has $.shortname;
}
Job done.
Before I came down to this solution I’ve got 34 record classes implemented using the old approach. Some are little, some are quite big. But it most certainly could’ve taken much less time would I have the trait at my disposal back then…
I have managed to finish one more article in the Advanced Raku For Beginners series, this time about type and object composition in Raku.
It’s likely to take a long before I can write another.
Once, long ago, coincidentally a few people were asking the same question: how do I get a method object of a class?
Answers to the question would depend on particular circumstances of the code where this functionality is needed. One
would be about using MOP methods like .^lookup, the other is to use method name and indirect resolution on invocant:
self."$method-name"(...). Both are the most useful, in my view. But sometimes declaring a method as our can be
helpful too:
class Foo {
our method bar {}
}
say Foo::<&bar>.raku;
Just don’t forget that this way we always get the method of class Foo, even if a subclass overrides method bar.
The first Raku Core Summit, a gathering of folks who work on “core” Raku things, was held on the first weekend of June, and I was one of those invited to attend. It’s certainly the case that I’ve been a lot less active in Raku things over the last 18 months, and I hesitated for a moment over whether to go. However, even if I’m not so involved day to day in Raku things at the moment, I’m still keen to see the language and its ecosystem move forward, and – having implemented no small amount of the compiler and runtime since getting involved in 2007 – I figured I’d find something useful to do there!
The area I was especially keen to help with is RakuAST, something I started, and that I’m glad I managed to bring far enough that others could see the potential and were excited enough to pick it up and run with it.
One tricky aspect of implementing Raku is the whole notion of BEGIN time (of course, this is also one of the things that makes Raku powerful and thus is widely used). In short, BEGIN time is about running code during the compile time, and in Raku there’s no separate meta-language; anything you can do at runtime, you can (in principle) do at compile time too. The problem at hand was what to do about references from code running at compile time to lexically scoped symbols in the surrounding scope. Of note, that lexical scope is still being compiled, so doesn’t really exist yet so far as the runtime is concerned. The current compiler deals with this by building up an entire flattened table of everything that is visible, and installing it as a fake outer scope while running the BEGIN-time code. This is rather costly, and the hope in RakuAST was to avoid this kind of approach in general.
A better solution seemed to be at hand by spotting such references during compilation, resolving them, and fixating them – that is, they get compiled as if they were lookups into a constant table. (This copies the suggested approach for quasiquoted code that references symbols in the lexical scope of where the quasiquoted code appears.) This seemed promising, but there’s a problem:
my $x = BEGIN %*ENV<DEBUG> ?? -> $x { note "Got $x"; foo($x) } !! -> $x { foo($x) };It’s fine to post-declare subs, and so there’s no value to fixate. Thankfully, the generalized dispatch mechanism can ride to the rescue; we can:
When compiling Raku code, timing is everything. I knew this and tried to account for it in the RakuAST design from the start, but a couple of things in particular turned out a bit awkward.
I got a decent way into this restructuring work during the core summit, and hope to find time soon to get it a bit further along (I’ve been a mix of busy, tired, and had an eye infection to boot since getting back from the summit, so thus far there’s not been time for it).
I also took part in various other discussions and helped with some other things; those that are probably most worth mentioning are:
Thanks goes to Liz for organizing the summit, to Wendy for keeping everyone so well fed and watered, to the rest of attendees for many interesting discussions over the three days, to TPRF and Rootprompt for sponsoring the event, and to Edument for supporting my attendance.
Hi hackers! Today the MoarVM JIT project is nearly 9 years old. I was inspired by Jonathan's presentation reflecting on the development of MoarVM, to do the same for the MoarVM JIT, for which I have been responsible.
For those who are unfamiliar, what is commonly understood as 'JIT compilation' for virtual machines is performed by two components in MoarVM.
This post refers only to the native code generation backend component. It, too, is split into two mostly-independent systems:
One one hand, as a result of my limited experience, time and resources, and on the other hand as a result of the design of MoarVM.
MoarVM was originally designed as a traditional interpreter for a high level language (much like the Perl interpreter). Meaning that it has a large number of different instructions and many instructions operate on high-level data structures like strings, arrays and maps (as opposed to pointers and machine words).
This is by no means a bad or outdated design. Frequently executed routines (string manipulation, hash table lookups etc.) are implemented using an efficient language (C) and driven by a language that is optimized for usability (Raku). This design is also used in modern machine learning frameworks. More importantly, this was a reasonable design because it is a good target for the Rakudo compiler.
For the JIT compiler, this means two things:
The machine code generated by the JIT compiler then will mostly consists of consecutive function calls to VM routines, which is not the type of code where a compiler can really improve performance much.
In other words, suppose 50% of runtime is spent in interpretation overhead (instruction decoding and dispatch), and 50% is spent in VM routines, then removing interpretation overhead via JIT compilation will at best result in a twofold increase in performance. For many programs, the observed performance increase will be even less.
Mind that I'm specifically refering to the improvement due to machine code generation, and not to those due to type specialization, inlining etc. (the domain of 'spesh'). These latter features have resulted in much more significant performance improvements.
For me personally, it was a tremendously valuable learning experience which led directly to my current career, writing SQL compilers for Google Cloud.
For the Raku community, even if we never realized the performance improvements that I might have hoped at the start, I hope that the JIT project (as it exists) has been valuable, if for no other reason than identifying the challenges of JIT compilation for MoarVM. A future effort may be able to do better based on what we learned; and I hope my blog posts are a useful resource from that perspective.
Assuming that time and resources were not an issue:
If any of this comes to pass, you'll find my report on it right here. Thanks for reasding and until then!
Around 18 months ago, I set about working on the largest set of architectural changes that Raku runtime MoarVM has seen since its inception. The work was most directly triggered by the realization that we had no good way to fix a certain semantic bug in dispatch without either causing huge performance impacts across the board or increasingly complexity even further in optimizations that were already riding their luck. However, the need for something like this had been apparent for a while: a persistent struggle to optimize certain Raku language features, the pain of a bunch of performance mechanisms that were all solving the same kind of problem but each for a specific situation, and a sense that, with everything learned since I founded MoarVM, it was possible to do better.
The result is the development of a new generalized dispatch mechanism. An overview can be found in my Raku Conference talk about it (slides, video); in short, it gives us a far more uniform architecture for all kinds of dispatch, allowing us to deliver better performance on a range of language features that have thus far been glacial, as well as opening up opportunities for new optimizations.
Today, this work has been merged, along with the matching changes in NQP (the Raku subset we use for bootstrapping and to implement the compiler) and Rakudo (the full Raku compiler and standard library implementation). This means that it will ship in the October 2021 releases.
In this post, I’ll give an overview of what you can expect to observe right away, and what you might expect in the future as we continue to build upon the possibilities that the new dispatch architecture has to offer.
The biggest improvements involve language features that we’d really not had the architecture to do better on before. They involved dispatch – that is, getting a call linked to a destination efficiently – but the runtime didn’t provide us with a way to “explain” to it that it was looking at a dispatch, let alone with the information needed to have a shot at optimizing it.
The following graph captures a number of these cases, and shows the level of improvement, ranging from a factor of 3.3 to 13.3 times faster.

Let’s take a quick look at each of these. The first, new-buf, asks how quickly we can allocate Bufs.
for ^10_000_000 {
Buf.new
}
Why is this a dispatch benchmark? Because Buf is not a class, but rather a role. When we try to make an instance of a role, it is “punned” into a class. Up until now, it works as follows:
new methodfind_method method would, if needed, create a pun of the role and cache it-> $role-discarded, |args { $pun."$name"(|args) }This had a number of undesirable consequences:
With the new dispatch mechanism, we have a means to cache constants at a given program location and to replace arguments. So the first time we encounter the call, we:
new method on the class punned from the roleFor the next thousands of calls, we interpret this dispatch program. It’s still some cost, but the method we’re calling is already resolved, and the argument list rewriting is fairly cheap. Meanwhile, after we get into some hundreds of iterations, on a background thread, the optimizer gets to work. The argument re-ordering cost goes away completely at this point, and new is so small it gets inlined – at which point the buffer allocation is determined dead and so goes away too. Some remaining missed opportunities mean we still are left with a loop that’s not quite empty: it busies itself making sure it’s really OK to do nothing, rather than just doing nothing.
Next up, multiple dispatch with where clauses.
multi fac($n where $n <= 1) { 1 }
multi fac($n) { $n * fac($n - 1) }
for ^1_000_000 {
fac(5)
}
These were really slow before, since:
where clause involvedwhere clauses twice in the event the candidate was chosen: once to see if we should choose that multi candidate, and once again when we entered itWith the new mechanism, we:
where clause, in a mode whereby if the signature fails to bind, it triggers a dispatch resumption. (If it does bind, it runs to completion)Once again, after the setup phase, we interpret the dispatch programs. In fact, that’s as far as we get with running this faster for now, because the specializer doesn’t yet know how to translate and further optimize this kind of dispatch program. (That’s how I know it currently stands no chance of turning this whole thing into another empty loop!) So there’s more to be had here also; in the meantime, I’m afraid you’ll just have to settle for a factor of ten speedup.
Here’s the next one:
proto with-proto(Int $n) { 2 * {*} }
multi with-proto(Int $n) { $n + 1 }
sub invoking-nontrivial-proto() {
for ^10_000_000 {
with-proto(20)
}
}
Again, on top form, we’d turn this into an empty loop too, but we don’t quite get there yet. This case wasn’t so terrible before: we did get to use the multiple dispatch cache, however to do that we also ended up having to allocate an argument capture. The need for this also blocked any chance of inlining the proto into the caller. Now that is possible. Since we cannot yet translate dispatch programs that resume an in-progress dispatch, we don’t yet get to further inline the called multi candidate into the proto. However, we now have a design that will let us implement that.
This whole notion of a dispatch resumption – where we start doing a dispatch, and later need to access arguments or other pre-calculated data in order to do a next step of it – has turned out to be a great unification. The initial idea for it came from considering things like callsame:
class Parent {
method m() { 1 }
}
class Child is Parent {
method m() { 1 + callsame }
}
for ^10_000_000 {
Child.m;
}
Once I started looking at this, and then considering that a complex proto also wants to continue with a dispatch at the {*}, and in the case a where clauses fails in a multi it also wants to continue with a dispatch, I realized this was going to be useful for quite a lot of things. It will be a bit of a headache to teach the optimizer and JIT to do nice things with resumes – but a great relief that doing that once will benefit multiple language features!
Anyway, back to the benchmark. This is another “if we were smart, it’d be an empty loop” one. Previously, callsame was very costly, because each time we invoked it, it would have to calculate what kind of dispatch we were resuming and the set of methods to call. We also had to be able to locate the arguments. Dynamic variables were involved, which cost a bit to look up too, and – despite being an implementation details – these also leaked out in introspection, which wasn’t ideal. The new dispatch mechanism makes this all rather more efficient: we can cache the calculated set of methods (or wrappers and multi candidates, depending on the context) and then walk through it, and there’s no dynamic variables involved (and thus no leakage of them). This sees the biggest speedup of the lot – and since we cannot yet inline away the callsame, it’s (for now) measuring the speedup one might expect on using this language feature. In the future, it’s destined to optimize away to an empty loop.
A module that makes use of callsame on a relatively hot path is OO::Monitors,, so I figured it would be interesting to see if there is a speedup there also.
use OO::Monitors;
monitor TestMonitor {
method m() { 1 }
}
my $mon = TestMonitor.new;
for ^1_000_000 {
$mon.m();
}
A monitor is a class that acquires a lock around each method call. The module provides a custom meta-class that adds a lock attribute to the class and then wraps each method such that it acquires the lock. There are certainly costly things in there besides the involvement of callsame, but the improvement to callsame is already enough to see a 3.3x speedup in this benchmark. Since OO::Monitors is used in quite a few applications and modules (for example, Cro uses it), this is welcome (and yes, a larger improvement will be possible here too).
I’ve seen some less impressive, but still welcome, improvements across a good number of other microbenchmarks. Even a basic multi dispatch on the + op:
my $i = 0;
for ^10_000_000 {
$i = $i + $_;
}
Comes out with a factor of 1.6x speedup, thanks primarily to us producing far tighter code with fewer guards. Previously, we ended up with duplicate guards in this seemingly straightforward case. The infix:<+> multi candidate would be specialized for the case of its first argument being an Int in a Scalar container and its second argument being an immutable Int. Since a Scalar is mutable, the specialization would need to read it and then guard the value read before proceeding, otherwise it may change, and we’d risk memory safety. When we wanted to inline this candidate, we’d also want to do a check that the candidate really applies, and so also would deference the Scalar and guard its content to do that. We can and do eliminate duplicate guards – but these guards are on two distinct reads of the value, so that wouldn’t help.
Since in the new dispatch mechanism we can rewrite arguments, we can now quite easily do caller-side removal of Scalar containers around values. So easily, in fact, that the change to do it took me just a couple of hours. This gives a lot of benefits. Since dispatch programs automatically eliminate duplicate reads and guards, the read and guard by the multi-dispatcher and the read in order to pass the decontainerized value are coalesced. This means less repeated work prior to specialization and JIT compilation, and also only a single read and guard in the specialized code after it. With the value to be passed already guarded, we can trivially select a candidate taking two bare Int values, which means there’s no further reads and guards needed in the callee either.
A less obvious benefit, but one that will become important with planned future work, is that this means Scalar containers escape to callees far less often. This creates further opportunities for escape analysis. While the MoarVM escape analyzer and scalar replacer is currently quite limited, I hope to return to working on it in the near future, and expect it will be able to give us even more value now than it would have been able to before.
The benchmarks shown earlier are mostly of the “how close are we to realizing that we’ve got an empty loop” nature, which is interesting for assessing how well the optimizer can “see through” dispatches. Here are a few further results on more “traditional” microbenchmarks:

The complex number benchmark is as follows:
my $total-re = 0e0;
for ^2_000_000 {
my $x = 5 + 2i;
my $y = 10 + 3i;
my $z = $x * $x + $y;
$total-re = $total-re + $z.re
}
say $total-re;
That is, just a bunch of operators (multi dispatch) and method calls, where we really do use the result. For now, we’re tied with Python and a little behind Ruby on this benchmark (and a surprising 48 times faster than the same thing done with Perl’s Math::Complex), but this is also a case that stands to see a huge benefit from escape analysis and scalar replacement in the future.
The hash read benchmark is:
my %h = a => 10, b => 12;
my $total = 0;
for ^10_000_000 {
$total = $total + %h<a> + %h<b>;
}
And the hash store one is:
my @keys = 'a'..'z';
for ^500_000 {
my %h;
for @keys {
%h{$_} = 42;
}
}
The improvements are nothing whatsoever to do with hashing itself, but instead look to be mostly thanks to much tighter code all around due to caller-side decontainerization. That can have a secondary effect of bringing things under the size limit for inlining, which is also a big help. Speedup factors of 2x and 1.85x are welcome, although we could really do with the same level of improvement again for me to be reasonably happy with our results.
The line-reading benchmark is:
my $fh = open "longfile";
my $chars = 0;
for $fh.lines { $chars = $chars + .chars };
$fh.close;
say $chars
Again, nothing specific to I/O got faster, but when dispatch – the glue that puts together all the pieces – gets a boost, it helps all over the place. (We are also decently competitive on this benchmark, although tend to be slower the moment the UTF-8 decoder can’t take it’s “NFG can’t possibly apply” fast path.)
I’ve also started looking at larger programs, and hearing results from others about theirs. It’s mostly encouraging:
Text::CSV benchmark test-t has seen roughly 20% improvement (thanks to lizmat for measuring)Cro::HTTP test application gets through about 10% more requests per secondCORE.setting, the standard library. However, a big pinch of salt is needed here: the compiler itself has changed in a number of places as part of the work, and there were a couple of things tweaked based on looking at profiles that aren’t really related to dispatch.One unpredicted (by me), but also welcome, improvement is that profiler output has become significantly smaller. Likely reasons for this include:
sink method when a value was in sink context. Now, if we see that the type simply inherits that method from Mu, we elide the call entirely (again, it would inline away, but a smaller call graph is a smaller profile).proto when the cache was missed, but would then not call an onlystar proto again when it got cache hits in the future. This meant the call tree under many multiple dispatches was duplicated in the profile. This wasn’t just a size issue; it was a bit annoying to have this effect show up in the profile reports too.To give an example of the difference, I took profiles from Agrammon to study why it might have become slower. The one from before the dispatcher work weighed in at 87MB; the one with the new dispatch mechanism is under 30MB. That means less memory used while profiling, less time to write the profile out to disk afterwards, and less time for tools to load the profiler output. So now it’s faster to work out how to make things faster.
I’m afraid so. Startup time has suffered. While the new dispatch mechanism is more powerful, pushes more complexity out of the VM into high level code, and is more conducive to reaching higher peak performance, it also has a higher warmup time. At the time of writing, the impact on startup time seems to be around 25%. I expect we can claw some of that back ahead of the October release.
Changes of this scale always come with an amount of risk. We’re merging this some weeks ahead of the next scheduled monthly release in order to have time for more testing, and to address any regressions that get reported. However, even before reaching the point of merging it, we have:
blin to run the tests of ecosystem modules. This is a standard step when preparing Rakudo releases, but in this case we’ve aimed it at the new-disp branches. This found a number of regressions caused by the switch to the new dispatch mechanism, which have been addressed.As I’ve alluded to in a number of places in this post, while there are improvements to be enjoyed right away, there are also new opportunities for further improvement. Some things that are on my mind include:
callsame one here is a perfect example! The point we do the resumption of a dispatch is inside callsame, so all the inline cache entries of resumptions throughout the program stack up in one place. What we’d like is to have them attached a level down the callstack instead. Otherwise, the level of callsame improvement seen in micro-benchmarks will not be enjoyed in larger applications. This applies in a number of other situations too.FALLBACK method could have its callsite easily rewritten to do that, opening the way to inlining.Ints (which needs a great deal of care in memory management, as they may box a big integer, not just a native integer).I would like to thank TPF and their donors for providing the funding that has made it possible for me to spend a good amount of my working time on this effort.
While I’m to blame for the overall design and much of the implementation of the new dispatch mechanism, plenty of work has also been put in by other MoarVM and Rakudo contributors – especially over the last few months as the final pieces fell into place, and we turned our attention to getting it production ready. I’m thankful to them not only for the code and debugging contributions, but also much support and encouragement along the way. It feels good to have this merged, and I look forward to building upon it in the months and years to come.
I recently wrote about the new MoarVM dispatch mechanism, and in that post noted that I still had a good bit of Raku’s multiple dispatch semantics left to implement in terms of it. Since then, I’ve made a decent amount of progress in that direction. This post contains an overview of the approach taken, and some very rough performance measurements.
Of all the kinds of dispatch we find in Raku, multiple dispatch is the most complex. Multiple dispatch allows us to write a set of candidates, which are then selected by the number of arguments:
multi ok($condition, $desc) {
say ($condition ?? 'ok' !! 'not ok') ~ " - $desc";
}
multi ok($condition) {
ok($condition, '');
}
Or the types of arguments:
multi to-json(Int $i) { ~$i }
multi to-json(Bool $b) { $b ?? 'true' !! 'false' }
And not just one argument, but potentially many:
multi truncate(Str $str, Int $chars) {
$str.chars < $chars ?? $str !! $str.substr(0, $chars) ~ '...'
}
multi truncate(Str $str, Str $after) {
with $str.index($after) -> $pos {
$str.substr(0, $pos) ~ '...'
}
else {
$str
}
}
We may write where clauses to differentiate candidates on properties that are not captured by nominal types:
multi fac($n where $n <= 1) { 1 }
multi fac($n) { $n * fac($n - 1) }
Every time we write a set of multi candidates like this, the compiler will automatically produce a proto routine. This is what is installed in the symbol table, and holds the candidate list. However, we can also write our own proto, and use the special term {*} to decide at which point we do the dispatch, if at all.
proto mean($collection) {
$collection.elems == 0 ?? Nil !! {*}
}
multi mean(@arr) {
@arr.sum / @arr.elems
}
multi mean(%hash) {
%hash.values.sum / %hash.elems
}
Candidates are ranked by narrowness (using topological sorting). If multiple candidates match, but they are equally narrow, then that’s an ambiguity error. Otherwise, we call narrowest one. The candidate we choose may then use callsame and friends to defer to the next narrowest candidate, which may do the same, until we reach the most general matching one.
Raku leans heavily on multiple dispatch. Most operators in Raku are compiled into calls to multiple dispatch subroutines. Even $a + $b will be a multiple dispatch. This means doing multiple dispatch efficiently is really important for performance. Given the riches of its semantics, this is potentially a bit concerning. However, there’s good news too.
The overwhelmingly common case is that we have:
where clausesprotocallsameThis isn’t to say the other cases are unimportant; they are really quite useful, and it’s desirable for them to perform well. However, it’s also desirable to make what savings we can in the common case. For example, we don’t want to eagerly calculate the full set of possible candidates for every single multiple dispatch, because the majority of the time only the first one matters. This is not just a time concern: recall that the new dispatch mechanism stores dispatch programs at each callsite, and if we store the list of all matching candidates at each of those, we’ll waste a lot of memory too.
The situation in Rakudo today is as follows:
proto holding a “dispatch cache”, a special-case mechanism implemented in the VM that uses a search tree, with one level per argument.proto, it’s not too bad either, though inlining isn’t going to be happening; it can still use the search tree, thoughwhere clauses, it’ll be slow, because the search tree only deals in finding one candidate per set of nominal types, and so we can’t use itcallsame; it’ll be slow tooEffectively, the situation today is that you simply don’t use where clauses in a multiple dispatch if its anywhere near a hot path (well, and if you know where the hot paths are, and know that this kind of dispatch is slow). Ditto for callsame, although that’s less commonly reached for. The question is, can we do better with the new dispatcher?
Let’s start out with seeing how the simplest cases are dealt with, and build from there. (This is actually what I did in terms of the implementation, but at the same time I had a rough idea where I was hoping to end up.)
Recall this pair of candidates:
multi truncate(Str $str, Int $chars) {
$str.chars < $chars ?? $str !! $str.substr(0, $chars) ~ '...'
}
multi truncate(Str $str, Str $after) {
with $str.index($after) -> $pos {
$str.substr(0, $pos) ~ '...'
}
else {
$str
}
}
We then have a call truncate($message, "\n"), where $message is a Str. Under the new dispatch mechanism, the call is made using the raku-call dispatcher, which identifies that this is a multiple dispatch, and thus delegates to raku-multi. (Multi-method dispatch ends up there too.)
The record phase of the dispatch – on the first time we reach this callsite – will proceed as follows:
raku-invoke dispatcher with the chosen candidate.When we reach the same callsite again, we can run the dispatch program, which quickly checks if the argument types match those we saw last time, and if they do, we know which candidate to invoke. These checks are very cheap – far cheaper than walking through all of the candidates and examining each of them for a match. The optimizer may later be able to prove that the checks will always come out true and eliminate them.
Thus the whole of the dispatch processes – at least for this simple case where we only have types and arity – can be “explained” to the virtual machine as “if the arguments have these exact types, invoke this routine”. It’s pretty much the same as we were doing for method dispatch, except there we only cared about the type of the first argument – the invocant – and the value of the method name. (Also recall from the previous post that if it’s a multi-method dispatch, then both method dispatch and multiple dispatch will guard the type of the first argument, but the duplication is eliminated, so only one check is done.)
Coming up with good abstractions is difficult, and therein lies much of the challenge of the new dispatch mechanism. Raku has quite a number of different dispatch-like things. However, encoding all of them directly in the virtual machine leads to high complexity, which makes building reliable optimizations (or even reliable unoptimized implementations!) challenging. Thus the aim is to work out a comparatively small set of primitives that allow for dispatches to be “explained” to the virtual machine in such a way that it can deliver decent performance.
It’s fairly clear that callsame is a kind of dispatch resumption, but what about the custom proto case and the where clause case? It turns out that these can both be neatly expressed in terms of dispatch resumption too (the where clause case needing one small addition at the virtual machine level, which in time is likely to be useful for other things too). Not only that, but encoding these features in terms of dispatch resumption is also quite direct, and thus should be efficient. Every trick we teach the specializer about doing better with dispatch resumptions can benefit all of the language features that are implemented using them, too.
Recall this example:
proto mean($collection) {
$collection.elems == 0 ?? Nil !! {*}
}
Here, we want to run the body of the proto, and then proceed to the chosen candidate at the point of the {*}. By contrast, when we don’t have a custom proto, we’d like to simply get on with calling the correct multi.
To achieve this, I first moved the multi candidate selection logic from the raku-multi dispatcher to the raku-multi-core dispatcher. The raku-multi dispatcher then checks if we have an “onlystar” proto (one that does not need us to run it). If so, it delegates immediately to raku-multi-core. If not, it saves the arguments to the dispatch as the resumption initialization state, and then calls the proto. The proto‘s {*} is compiled into a dispatch resumption. The resumption then delegates to raku-multi-core. Or, in code:
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-multi',
# Initial dispatch, only setting up resumption if we need to invoke the
# proto.
-> $capture {
my $callee := nqp::captureposarg($capture, 0);
my int $onlystar := nqp::getattr_i($callee, Routine, '$!onlystar');
if $onlystar {
# Don't need to invoke the proto itself, so just get on with the
# candidate dispatch.
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi-core', $capture);
}
else {
# Set resume init args and run the proto.
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-init-args', $capture);
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-invoke', $capture);
}
},
# Resumption means that we have reached the {*} in the proto and so now
# should go ahead and do the dispatch. Make sure we only do this if we
# are signalled to that it's a resume for an onlystar (resumption kind 5).
-> $capture {
my $track_kind := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_kind);
my int $kind := nqp::captureposarg_i($capture, 0);
if $kind == 5 {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi-core',
nqp::dispatch('boot-syscall', 'dispatcher-get-resume-init-args'));
}
elsif !nqp::dispatch('boot-syscall', 'dispatcher-next-resumption') {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-constant',
nqp::dispatch('boot-syscall', 'dispatcher-insert-arg-literal-obj',
$capture, 0, Nil));
}
});
Deferring to the next candidate (for example with callsame) and trying the next candidate because a where clause failed look very similar: both involve walking through a list of possible candidates. There’s some details, but they have a great deal in common, and it’d be nice if that could be reflected in how multiple dispatch is implemented using the new dispatcher.
Before that, a slightly terrible detail about how things work in Rakudo today when we have where clauses. First, the dispatcher does a “trial bind”, where it asks the question: would this signature bind? To do this, it has to evaluate all of the where clauses. Worse, it has to use the slow-path signature binder too, which interprets the signature, even though we can in many cases compile it. If the candidate matches, great, we select it, and then invoke it…which runs the where clauses a second time, as part of the compiled signature binding code. There is nothing efficient about this at all, except for it being by far more efficient on developer time, which is why it happened that way.
Anyway, it goes without saying that I’m rather keen to avoid this duplicate work and the slow-path binder where possible as I re-implement this using the new dispatcher. And, happily, a small addition provides a solution. There is an op assertparamcheck, which any kind of parameter checking compiles into (be it type checking, where clause checking, etc.) This triggers a call to a function that gets the arguments, the thing we were trying to call, and can then pick through them to produce an error message. The trick is to provide a way to invoke a routine such that a bind failure, instead of calling the error reporting function, will leave the routine and then do a dispatch resumption! This means we can turn failure to pass where clause checks into a dispatch resumption, which will then walk to the next candidate and try it instead.
This gets us most of the way to a solution, but there’s still the question of being memory and time efficient in the common case, where there is no resumption and no where clauses. I coined the term “trivial multiple dispatch” for this situation, which makes the other situation “non-trivial”. In fact, I even made a dispatcher called raku-multi-non-trivial! There are two ways we can end up there.
where clauses. As soon as we see this is the case, we go ahead and produce a full list of possible candidates that could match. This is a linked list (see my previous post for why).callsame happens, we end up in the trivial dispatch resumption handler, which – since this situation is now non-trivial – builds the full candidate list, snips the first item off it (because we already ran that), and delegates to raku-multi-non-trivial.Lost in this description is another significant improvement: today, when there are where clauses, we entirely lose the ability to use the MoarVM multiple dispatch cache, but under the new dispatcher, we store a type-filtered list of candidates at the callsite, and then cheap type guards are used to check it is valid to use.
I did a few benchmarks to see how the new dispatch mechanism did with a couple of situations known to be sub-optimal in Rakudo today. These numbers do not reflect what is possible, because at the moment the specializer does not have much of an understanding of the new dispatcher. Rather, they reflect the minimal improvement we can expect.
Consider this benchmark using a multi with a where clause to recursively implement factorial.
multi fac($n where $n <= 1) { 1 }
multi fac($n) { $n * fac($n - 1) }
for ^100_000 {
fac(10)
}
say now - INIT now;
This needs some tweaks (and to be run under an environment variable) to use the new dispatcher; these are temporary, until such a time I switch Rakudo over to using the new dispatcher by default:
use nqp;
multi fac($n where $n <= 1) { 1 }
multi fac($n) { $n * nqp::dispatch('raku-call', &fac, $n - 1) }
for ^100_000 {
nqp::dispatch('raku-call', &fac, 10);
}
say now - INIT now;
On my machine, the first runs in 4.86s, the second in 1.34s. Thus under the new dispatcher this runs in little over a quarter of the time it used to – a quite significant improvement already.
A case involving callsame is also interesting to consider. Here it is without using the new dispatcher:
multi fallback(Any $x) { "a$x" }
multi fallback(Numeric $x) { "n" ~ callsame }
multi fallback(Real $x) { "r" ~ callsame }
multi fallback(Int $x) { "i" ~ callsame }
for ^1_000_000 {
fallback(4+2i);
fallback(4.2);
fallback(42);
}
say now - INIT now;
And with the temporary tweaks to use the new dispatcher:
use nqp;
multi fallback(Any $x) { "a$x" }
multi fallback(Numeric $x) { "n" ~ new-disp-callsame }
multi fallback(Real $x) { "r" ~ new-disp-callsame }
multi fallback(Int $x) { "i" ~ new-disp-callsame }
for ^1_000_000 {
nqp::dispatch('raku-call', &fallback, 4+2i);
nqp::dispatch('raku-call', &fallback, 4.2);
nqp::dispatch('raku-call', &fallback, 42);
}
say now - INIT now;
On my machine, the first runs in 31.3s, the second in 11.5s, meaning that with the new dispatcher we manage it in a little over a third of the time that current Rakudo does.
These are both quite encouraging, but as previously mentioned, a majority of multiple dispatches are of the trivial kind, not using these features. If I make the most common case worse on the way to making other things better, that would be bad. It’s not yet possible to make a fair comparison of this: trivial multiple dispatches already receive a lot of attention in the specializer, and it doesn’t yet optimize code using the new dispatcher well. Of note, in an example like this:
multi m(Int) { }
multi m(Str) { }
for ^1_000_000 {
m(1);
m("x");
}
say now - INIT now;
Inlining and other optimizations will turn this into an empty loop, which is hard to beat. There is one thing we can already do, though: run it with the specializer disabled. The new dispatcher version looks like this:
use nqp;
multi m(Int) { }
multi m(Str) { }
for ^1_000_000 {
nqp::dispatch('raku-call', &m, 1);
nqp::dispatch('raku-call', &m, "x");
}
say now - INIT now;
The results are 0.463s and 0.332s respectively. Thus, the baseline execution time – before the specializer does its magic – is less using the new general dispatch mechanism than it is using the special-case multiple dispatch cache that we currently use. I wasn’t sure what to expect here before I did the measurement. Given we’re going from a specialized mechanism that has been profiled and tweaked to a new general mechanism that hasn’t received such attention, I was quite ready to be doing a little bit worse initially, and would have been happy with parity. Running in 70% of the time was a bigger improvement than I expected at this point.
I expect that once the specializer understands the new dispatch mechanism better, it will be able to also turn the above into an empty loop – however, since more iterations can be done per-optimization, this should still show up as a win for the new dispatcher.
With one relatively small addition, the new dispatch mechanism is already handling most of the Raku multiple dispatch semantics. Furthermore, even without the specializer and JIT really being able to make a good job of it, some microbenchmarks already show a factor of 3x-4x improvement. That’s a pretty good starting point.
There’s still a good bit to do before we ship a Rakudo release using the new dispatcher. However, multiple dispatch was the biggest remaining threat to the design: it’s rather more involved than other kinds of dispatch, and it was quite possible that an unexpected shortcoming could trigger another round of design work, or reveal that the general mechanism was going to struggle to perform compared to the more specialized one in the baseline unoptimized, case. So far, there’s no indication of either of these, and I’m cautiously optimistic that the overall design is about right.
My goodness, it appears I’m writing my first Raku internals blog post in over two years. Of course, two years ago it wasn’t even called Raku. Anyway, without further ado, let’s get on with this shared brainache.
I use “dispatch” to mean a process by which we take a set of arguments and end up with some action being taken based upon them. Some familiar examples include:
$basket.add($product, $quantity). We might traditionally call just $product and $qauntity the arguments, but for my purposes, all of $basket, the method name 'add', $product, and $quantity` are arguments to the dispatch: they are the things we need in order to make a decision about what we’re going to do.uc($youtube-comment). Since Raku sub calls are lexically resolved, in this case the arguments to the dispatch are &uc (the result of looking up the subroutine) and $youtube-comment.At first glance, perhaps the first two seem fairly easy and the third a bit more of a handful – which is sort of true. However, Raku has a number of other features that make dispatch rather more, well, interesting. For example:
wrap allows us to wrap any Routine (sub or method); the wrapper can then choose to defer to the original routine, either with the original arguments or with new argumentsproto routine that gets to choose when – or even if – the call to the appropriate candidate is madecallsame in order to defer to the next candidate in the dispatch. But what does that mean? If we’re in a multiple dispatch, it would mean the next most applicable candidate, if any. If we’re in a method dispatch then it means a method from a base class. (The same thing is used to implement going to the next wrapper or, eventually, to the originally wrapped routine too). And these can be combined: we can wrap a multi method, meaning we can have 3 levels of things that all potentially contribute the next thing to call!Thanks to this, dispatch – at least in Raku – is not always something we do and produce an outcome, but rather a process that we may be asked to continue with multiple times!
Finally, while the examples I’ve written above can all quite clearly be seen as examples of dispatch, a number of other common constructs in Raku can be expressed as a kind of dispatch too. Assignment is one example: the semantics of it depend on the target of the assignment and the value being assigned, and thus we need to pick the correct semantics. Coercion is another example, and return value type-checking yet another.
Dispatch is everywhere in our programs, quietly tieing together the code that wants stuff done with the code that does stuff. Its ubiquity means it plays a significant role in program performance. In the best case, we can reduce the cost to zero. In the worst case, the cost of the dispatch is high enough to exceed that of the work done as a result of the dispatch.
To a first approximation, when the runtime “understands” the dispatch the performance tends to be at least somewhat decent, but when it doesn’t there’s a high chance of it being awful. Dispatches tend to involve an amount of work that can be cached, often with some cheap guards to verify the validity of the cached outcome. For example, in a method dispatch, naively we need to walk a linearization of the inheritance graph and ask each class we encounter along the way if it has a method of the specified name. Clearly, this is not going to be terribly fast if we do it on every method call. However, a particular method name on a particular type (identified precisely, without regard to subclassing) will resolve to the same method each time. Thus, we can cache the outcome of the lookup, and use it whenever the type of the invocant matches that used to produce the cached result.
When one starts building a runtime aimed at a particular language, and has to do it on a pretty tight budget, the most obvious way to get somewhat tolerable performance is to bake various hot-path language semantics into the runtime. This is exactly how MoarVM started out. Thus, if we look at MoarVM as it stood several years ago, we find things like:
where comes at a very high cost)Sub object has a private attribute in it that holds the low-level code handle identifying the bytecode to run)These are all still there today, however are also all on the way out. What’s most telling about this list is what isn’t included. Things like:
$obj.SomeType::method-name())A few years back I started to partially address this, with the introduction of a mechanism I called “specializer plugins”. But first, what is the specializer?
When MoarVM started out, it was a relatively straightforward interpreter of bytecode. It only had to be fast enough to beat the Parrot VM in order to get a decent amount of usage, which I saw as important to have before going on to implement some more interesting optimizations (back then we didn’t have the kind of pre-release automated testing infrastructure we have today, and so depended much more on feedback from early adopters). Anyway, soon after being able to run pretty much as much of the Raku language as any other backend, I started on the dynamic optimizer. It gathered type statistics as the program was interpreted, identified hot code, put it into SSA form, used the type statistics to insert guards, used those together with static properties of the bytecode to analyze and optimize, and produced specialized bytecode for the function in question. This bytecode could elide type checks and various lookups, as well as using a range of internal ops that make all kinds of assumptions, which were safe because of the program properties that were proved by the optimizer. This is called specialized bytecode because it has had a lot of its genericity – which would allow it to work correctly on all types of value that we might encounter – removed, in favor of working in a particular special case that actually occurs at runtime. (Code, especially in more dynamic languages, is generally far more generic in theory than it ever turns out to be in practice.)
This component – the specializer, known internally as “spesh” – delivered a significant further improvement in the performance of Raku programs, and with time its sophistication has grown, taking in optimizations such as inlining and escape analysis with scalar replacement. These aren’t easy things to build – but once a runtime has them, they create design possibilities that didn’t previously exist, and make decisions made in their absence look sub-optimal.
Of note, those special-cased language-specific mechanisms, baked into the runtime to get some speed in the early days, instead become something of a liability and a bottleneck. They have complex semantics, which means they are either opaque to the optimizer (so it can’t reason about them, meaning optimization is inhibited) or they need special casing in the optimizer (a liability).
So, back to specializer plugins. I reached a point where I wanted to take on the performance of things like $obj.?meth (the “call me maybe” dispatch), $obj.SomeType::meth() (dispatch qualified with a class to start looking in), and private method calls in roles (which can’t be resolved statically). At the same time, I was getting ready to implement some amount of escape analysis, but realized that it was going to be of very limited utility because assignment had also been special-cased in the VM, with a chunk of opaque C code doing the hot path stuff.
But why did we have the C code doing that hot-path stuff? Well, because it’d be too espensive to have every assignment call a VM-level function that does a bunch of checks and logic. Why is that costly? Because of function call overhead and the costs of interpretation. This was all true once upon a time. But, some years of development later:
I solved the assignment problem and the dispatch problems mentioned above with the introduction of a single new mechanism: specializer plugins. They work as follows:
The vast majority of cases are monomorphic, meaning that only one set of guards are produced and they always succeed thereafter. The specializer can thus compile those guards into the specialized bytecode and then assume the given target invocant is what will be invoked. (Further, duplicate guards can be eliminated, so the guards a particular plugin introduces may reduce to zero.)
Specializer plugins felt pretty great. One new mechanism solved multiple optimization headaches.
The new MoarVM dispatch mechanism is the answer to a fairly simple question: what if we get rid of all the dispatch-related special-case mechanisms in favor of something a bit like specializer plugins? The resulting mechanism would need to be a more powerful than specializer plugins. Further, I could learn from some of the shortcomings of specializer plugins. Thus, while they will go away after a relatively short lifetime, I think it’s fair to say that I would not have been in a place to design the new MoarVM dispatch mechanism without that experience.
All the method caching. All the multi dispatch caching. All the specializer plugins. All the invocation protocol stuff for unwrapping the bytecode handle in a code object. It’s all going away, in favor of a single new dispatch instruction. Its name is, boringly enough, dispatch. It looks like this:
dispatch_o result, 'dispatcher-name', callsite, arg0, arg1, ..., argN
Which means:
dispatcher-nameresult(Aside: this implies a new calling convention, whereby we no longer copy the arguments into an argument buffer, but instead pass the base of the register set and a pointer into the bytecode where the register argument map is found, and then do a lookup registers[map[argument_index]] to get the value for an argument. That alone is a saving when we interpret, because we no longer need a loop around the interpreter per argument.)
Some of the arguments might be things we’d traditionally call arguments. Some are aimed at the dispatch process itself. It doesn’t really matter – but it is more optimal if we arrange to put arguments that are only for the dispatch first (for example, the method name), and those for the target of the dispatch afterwards (for example, the method parameters).
The new bootstrap mechanism provides a small number of built-in dispatchers, whose names start with “boot-“. They are:
boot-value– take the first argument and use it as the result (the identity function, except discarding any further arguments)boot-constant – take the first argument and produce it as the result, but also treat it as a constant value that will always be produced (thus meaning the optimizer could consider any pure code used to calculate the value as dead)boot-code – take the first argument, which must be a VM bytecode handle, and run that bytecode, passing the rest of the arguments as its parameters; evaluate to the return value of the bytecodeboot-syscall – treat the first argument as the name of a VM-provided built-in operation, and call it, providing the remaining arguments as its parametersboot-resume – resume the topmost ongoing dispatchThat’s pretty much it. Every dispatcher we build, to teach the runtime about some other kind of dispatch behavior, eventually terminates in one of these.
Teaching MoarVM about different kinds of dispatch is done using nothing less than the dispatch mechanism itself! For the most part, boot-syscall is used in order to register a dispatcher, set up the guards, and provide the result that goes with them.
Here is a minimal example, taken from the dispatcher test suite, showing how a dispatcher that provides the identity function would look:
nqp::dispatch('boot-syscall', 'dispatcher-register', 'identity', -> $capture {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-value', $capture);
});
sub identity($x) {
nqp::dispatch('identity', $x)
}
ok(identity(42) == 42, 'Can define identity dispatch (1)');
ok(identity('foo') eq 'foo', 'Can define identity dispatch (2)');
In the first statement, we call the dispatcher-register MoarVM system call, passing a name for the dispatcher along with a closure, which will be called each time we need to handle the dispatch (which I tend to refer to as the “dispatch callback”). It receives a single argument, which is a capture of arguments (not actually a Raku-level Capture, but the idea – an object containing a set of call arguments – is the same).
Every user-defined dispatcher should eventually use dispatcher-delegate in order to identify another dispatcher to pass control along to. In this case, it delegates immediately to boot-value – meaning it really is nothing except a wrapper around the boot-value built-in dispatcher.
The sub identity contains a single static occurrence of the dispatch op. Given we call the sub twice, we will encounter this op twice at runtime, but the two times are very different.
The first time is the “record” phase. The arguments are formed into a capture and the callback runs, which in turn passes it along to the boot-value dispatcher, which produces the result. This results in an extremely simple dispatch program, which says that the result should be the first argument in the capture. Since there’s no guards, this will always be a valid result.
The second time we encounter the dispatch op, it already has a dispatch program recorded there, so we are in run mode. Turning on a debugging mode in the MoarVM source, we can see the dispatch program that results looks like this:
Dispatch program (1 temporaries)
Ops:
Load argument 0 into temporary 0
Set result object value from temporary 0
That is, it reads argument 0 into a temporary location and then sets that as the result of the dispatch. Notice how there is no mention of the fact that we went through an extra layer of dispatch; those have zero cost in the resulting dispatch program.
Argument captures are immutable. Various VM syscalls exist to transform them into new argument captures with some tweak, for example dropping or inserting arguments. Here’s a further example from the test suite:
nqp::dispatch('boot-syscall', 'dispatcher-register', 'drop-first', -> $capture {
my $capture-derived := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-value', $capture-derived);
});
ok(nqp::dispatch('drop-first', 'first', 'second') eq 'second',
'dispatcher-drop-arg works');
This drops the first argument before passing the capture on to the boot-value dispatcher – meaning that it will return the second argument. Glance back at the previous dispatch program for the identity function. Can you guess how this one will look?
Well, here it is:
Dispatch program (1 temporaries)
Ops:
Load argument 1 into temporary 0
Set result string value from temporary 0
Again, while in the record phase of such a dispatcher we really do create capture objects and make a dispatcher delegation, the resulting dispatch program is far simpler.
Here’s a slightly more involved example:
my $target := -> $x { $x + 1 }
nqp::dispatch('boot-syscall', 'dispatcher-register', 'call-on-target', -> $capture {
my $capture-derived := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $capture, 0, $target);
nqp::dispatch('boot-syscall', 'dispatcher-delegate',
'boot-code-constant', $capture-derived);
});
sub cot() { nqp::dispatch('call-on-target', 49) }
ok(cot() == 50,
'dispatcher-insert-arg-literal-obj works at start of capture');
ok(cot() == 50,
'dispatcher-insert-arg-literal-obj works at start of capture after link too');
Here, we have a closure stored in a variable $target. We insert it as the first argument of the capture, and then delegate to boot-code-constant, which will invoke that code object and pass the other dispatch arguments to it. Once again, at the record phase, we really do something like:
And the resulting dispatch program? It’s this:
Dispatch program (1 temporaries)
Ops:
Load collectable constant at index 0 into temporary 0
Skip first 0 args of incoming capture; callsite from 0
Invoke MVMCode in temporary 0
That is, load the constant bytecode handle that we’re going to invoke, set up the args (which are in this case equal to those of the incoming capture), and then invoke the bytecode with those arguments. The argument shuffling is, once again, gone. In general, whenever the arguments we do an eventual bytecode invocation with are a tail of the initial dispatch arguments, the arguments transform becomes no more than a pointer addition.
All of the dispatch programs seen so far have been unconditional: once recorded at a given callsite, they shall always be used. The big missing piece to make such a mechanism have practical utility is guards. Guards assert properties such as the type of an argument or if the argument is definite (Int:D) or not (Int:U).
Here’s a somewhat longer test case, with some explanations placed throughout it.
# A couple of classes for test purposes
my class C1 { }
my class C2 { }
# A counter used to make sure we're only invokving the dispatch callback as
# many times as we expect.
my $count := 0;
# A type-name dispatcher that maps a type into a constant string value that
# is its name. This isn't terribly useful, but it is a decent small example.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'type-name', -> $capture {
# Bump the counter, just for testing purposes.
$count++;
# Obtain the value of the argument from the capture (using an existing
# MoarVM op, though in the future this may go away in place of a syscall)
# and then obtain the string typename also.
my $arg-val := nqp::captureposarg($capture, 0);
my str $name := $arg-val.HOW.name($arg-val);
# This outcome is only going to be valid for a particular type. We track
# the argument (which gives us an object back that we can use to guard
# it) and then add the type guard.
my $arg := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-guard-type', $arg);
# Finally, insert the type name at the start of the capture and then
# delegate to the boot-constant dispatcher.
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-constant',
nqp::dispatch('boot-syscall', 'dispatcher-insert-arg-literal-str',
$capture, 0, $name));
});
# A use of the dispatch for the tests. Put into a sub so there's a single
# static dispatch op, which all dispatch programs will hang off.
sub type-name($obj) {
nqp::dispatch('type-name', $obj)
}
# Check with the first type, making sure the guard matches when it should
# (although this test would pass if the guard were ignored too).
ok(type-name(C1) eq 'C1', 'Dispatcher setting guard works');
ok($count == 1, 'Dispatch callback ran once');
ok(type-name(C1) eq 'C1', 'Can use it another time with the same type');
ok($count == 1, 'Dispatch callback was not run again');
# Test it with a second type, both record and run modes. This ensures the
# guard really is being checked.
ok(type-name(C2) eq 'C2', 'Can handle polymorphic sites when guard fails');
ok($count == 2, 'Dispatch callback ran a second time for new type');
ok(type-name(C2) eq 'C2', 'Second call with new type works');
# Check that we can use it with the original type too, and it has stacked
# the dispatch programs up at the same callsite.
ok(type-name(C1) eq 'C1', 'Call with original type still works');
ok($count == 2, 'Dispatch callback only ran a total of 2 times');
This time two dispatch programs get produced, one for C1:
Dispatch program (1 temporaries)
Ops:
Guard arg 0 (type=C1)
Load collectable constant at index 1 into temporary 0
Set result string value from temporary 0
And another for C2:
Dispatch program (1 temporaries)
Ops:
Guard arg 0 (type=C2)
Load collectable constant at index 1 into temporary 0
Set result string value from temporary 0
Once again, no leftovers from capture manipulation, tracking, or dispatcher delegation; the dispatch program does a type guard against an argument, then produces the result string. The whole call to $arg-val.HOW.name($arg-val) is elided, the dispatcher we wrote encoding the knowledge – in a way that the VM can understand – that a type’s name can be considered immutable.
This example is a bit contrived, but now consider that we instead look up a method and guard on the invocant type: that’s a method cache! Guard the types of more of the arguments, and we have a multi cache! Do both, and we have a multi-method cache.
The latter is interesting in so far as both the method dispatch and the multi dispatch want to guard on the invocant. In fact, in MoarVM today there will be two such type tests until we get to the point where the specializer does its work and eliminates these duplicated guards. However, the new dispatcher does not treat the dispatcher-guard-type as a kind of imperative operation that writes a guard into the resultant dispatch program. Instead, it declares that the argument in question must be guarded. If some other dispatcher already did that, it’s idempotent. The guards are emitted once all dispatch programs we delegate through, on the path to a final outcome, have had their say.
Fun aside: those being especially attentive will have noticed that the dispatch mechanism is used as part of implementing new dispatchers too, and indeed, this ultimately will mean that the specializer can specialize the dispatchers and have them JIT-compiled into something more efficient too. After all, from the perspective of MoarVM, it’s all just bytecode to run; it’s just that some of it is bytecode that tells the VM how to execute Raku programs more efficiently!
A resumable dispatcher needs to do two things:
When a resumption happens, the resume callback will be called, with any arguments for the resumption. It can also obtain the resume initialization state that was set in the dispatch callback. The resume initialization state contains the things needed in order to continue with the dispatch the first time it is resumed. We’ll take a look at how this works for method dispatch to see a concrete example. I’ll also, at this point, switch to looking at the real Rakudo dispatchers, rather than simplified test cases.
The Rakudo dispatchers take advantage of delegation, duplicate guards, and capture manipulations all having no runtime cost in the resulting dispatch program to, in my mind at least, quite nicely factor what is a somewhat involved dispatch process. There are multiple entry points to method dispatch: the normal boring $obj.meth(), the qualified $obj.Type::meth(), and the call me maybe $obj.?meth(). These have common resumption semantics – or at least, they can be made to provided we always carry a starting type in the resume initialization state, which is the type of the object that we do the method dispatch on.
Here is the entry point to dispatch for a normal method dispatch, with the boring details of reporting missing method errors stripped out.
# A standard method call of the form $obj.meth($arg); also used for the
# indirect form $obj."$name"($arg). It receives the decontainerized invocant,
# the method name, and the the args (starting with the invocant including any
# container).
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call', -> $capture {
# Try to resolve the method call using the MOP.
my $obj := nqp::captureposarg($capture, 0);
my str $name := nqp::captureposarg_s($capture, 1);
my $meth := $obj.HOW.find_method($obj, $name);
# Report an error if there is no such method.
unless nqp::isconcrete($meth) {
!!! 'Error reporting logic elided for brevity';
}
# Establish a guard on the invocant type and method name (however the name
# may well be a literal, in which case this is free).
nqp::dispatch('boot-syscall', 'dispatcher-guard-type',
nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 0));
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal',
nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 1));
# Add the resolved method and delegate to the resolved method dispatcher.
my $capture-delegate := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $capture, 0, $meth);
nqp::dispatch('boot-syscall', 'dispatcher-delegate',
'raku-meth-call-resolved', $capture-delegate);
});
Now for the resolved method dispatcher, which is where the resumption is handled. First, let’s look at the normal dispatch callback (the resumption callback is included but empty; I’ll show it a little later).
# Resolved method call dispatcher. This is used to call a method, once we have
# already resolved it to a callee. Its first arg is the callee, the second and
# third are the type and name (used in deferral), and the rest are the args to
# the method.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call-resolved',
# Initial dispatch
-> $capture {
# Save dispatch state for resumption. We don't need the method that will
# be called now, so drop it.
my $resume-capture := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
$capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-init-args', $resume-capture);
# Drop the dispatch start type and name, and delegate to multi-dispatch or
# just invoke if it's single dispatch.
my $delegate_capture := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $capture, 1), 1);
my $method := nqp::captureposarg($delegate_capture, 0);
if nqp::istype($method, Routine) && $method.is_dispatcher {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi', $delegate_capture);
}
else {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-invoke', $delegate_capture);
}
},
# Resumption
-> $capture {
... 'Will be shown later';
});
There’s an arguable cheat in raku-meth-call: it doesn’t actually insert the type object of the invocant in place of the invocant. It turns out that it doesn’t really matter. Otherwise, I think the comments (which are to be found in the real implementation also) tell the story pretty well.
One important point that may not be clear – but follows a repeating theme – is that the setting of the resume initialization state is also more of a declarative rather than an imperative thing: there isn’t a runtime cost at the time of the dispatch, but rather we keep enough information around in order to be able to reconstruct the resume initialization state at the point we need it. (In fact, when we are in the run phase of a resume, we don’t even have to reconstruct it in the sense of creating a capture object.)
Now for the resumption. I’m going to present a heavily stripped down version that only deals with the callsame semantics (the full thing has to deal with such delights as lastcall and nextcallee too). The resume initialization state exists to seed the resumption process. Once we know we actually do have to deal with resumption, we can do things like calculating the full list of methods in the inheritance graph that we want to walk through. Each resumable dispatcher gets a single storage slot on the call stack that it can use for its state. It can initialize this in the first step of resumption, and then update it as we go. Or more precisely, it can set up a dispatch program that will do this when run.
A linked list turns out to be a very convenient data structure for the chain of candidates we will walk through. We can work our way through a linked list by keeping track of the current node, meaning that there need only be a single thing that mutates, which is the current state of the dispatch. The dispatch program mechanism also provides a way to read an attribute from an object, and that is enough to express traversing a linked list into the dispatch program. This also means zero allocations.
So, without further ado, here is the linked list (rather less pretty in NQP, the restricted Raku subset, than it would be in full Raku):
# A linked list is used to model the state of a dispatch that is deferring
# through a set of methods, multi candidates, or wrappers. The Exhausted class
# is used as a sentinel for the end of the chain. The current state of the
# dispatch points into the linked list at the appropriate point; the chain
# itself is immutable, and shared over (runtime) dispatches.
my class DeferralChain {
has $!code;
has $!next;
method new($code, $next) {
my $obj := nqp::create(self);
nqp::bindattr($obj, DeferralChain, '$!code', $code);
nqp::bindattr($obj, DeferralChain, '$!next', $next);
$obj
}
method code() { $!code }
method next() { $!next }
};
my class Exhausted {};
And finally, the resumption handling.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call-resolved',
# Initial dispatch
-> $capture {
... 'Presented earlier;
},
# Resumption. The resume init capture's first two arguments are the type
# that we initially did a method dispatch against and the method name
# respectively.
-> $capture {
# Work out the next method to call, if any. This depends on if we have
# an existing dispatch state (that is, a method deferral is already in
# progress).
my $init := nqp::dispatch('boot-syscall', 'dispatcher-get-resume-init-args');
my $state := nqp::dispatch('boot-syscall', 'dispatcher-get-resume-state');
my $next_method;
if nqp::isnull($state) {
# No state, so just starting the resumption. Guard on the
# invocant type and name.
my $track_start_type := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $init, 0);
nqp::dispatch('boot-syscall', 'dispatcher-guard-type', $track_start_type);
my $track_name := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $init, 1);
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_name);
# Also guard on there being no dispatch state.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_state);
# Build up the list of methods to defer through.
my $start_type := nqp::captureposarg($init, 0);
my str $name := nqp::captureposarg_s($init, 1);
my @mro := nqp::can($start_type.HOW, 'mro_unhidden')
?? $start_type.HOW.mro_unhidden($start_type)
!! $start_type.HOW.mro($start_type);
my @methods;
for @mro {
my %mt := nqp::hllize($_.HOW.method_table($_));
if nqp::existskey(%mt, $name) {
@methods.push(%mt{$name});
}
}
# If there's nothing to defer to, we'll evaluate to Nil (just don't set
# the next method, and it happens below).
if nqp::elems(@methods) >= 2 {
# We can defer. Populate next method.
@methods.shift; # Discard the first one, which we initially called
$next_method := @methods.shift; # The immediate next one
# Build chain of further methods and set it as the state.
my $chain := Exhausted;
while @methods {
$chain := DeferralChain.new(@methods.pop, $chain);
}
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-state-literal', $chain);
}
}
elsif !nqp::istype($state, Exhausted) {
# Already working through a chain of method deferrals. Obtain
# the tracking object for the dispatch state, and guard against
# the next code object to run.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
my $track_method := nqp::dispatch('boot-syscall', 'dispatcher-track-attr',
$track_state, DeferralChain, '$!code');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_method);
# Update dispatch state to point to next method.
my $track_next := nqp::dispatch('boot-syscall', 'dispatcher-track-attr',
$track_state, DeferralChain, '$!next');
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-state', $track_next);
# Set next method, which we shall defer to.
$next_method := $state.code;
}
else {
# Dispatch already exhausted; guard on that and fall through to returning
# Nil.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_state);
}
# If we found a next method...
if nqp::isconcrete($next_method) {
# Call with same (that is, original) arguments. Invoke with those.
# We drop the first two arguments (which are only there for the
# resumption), add the code object to invoke, and then leave it
# to the invoke or multi dispatcher.
my $just_args := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $init, 0),
0);
my $delegate_capture := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $just_args, 0, $next_method);
if nqp::istype($next_method, Routine) && $next_method.is_dispatcher {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi',
$delegate_capture);
}
else {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-invoke',
$delegate_capture);
}
}
else {
# No method, so evaluate to Nil (boot-constant disregards all but
# the first argument).
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-constant',
nqp::dispatch('boot-syscall', 'dispatcher-insert-arg-literal-obj',
$capture, 0, Nil));
}
});
That’s quite a bit to take in, and quite a bit of code. Remember, however, that this is only run for the record phase of a dispatch resumption. It also produces a dispatch program at the callsite of the callsame, with the usual guards and outcome. Implicit guards are created for the dispatcher that we are resuming at that point. In the most common case this will end up monomorphic or bimorphic, although situations involving nestings of multiple dispatch or method dispatch could produce a more morphic callsite.
The design I’ve picked forces resume callbacks to deal with two situations: the first resumption and the latter resumptions. This is not ideal in a couple of ways:
Only the second of these really matters. The reason for the non-uniformity is to make sure that the overwhelming majority of calls, which never lead to a dispatch resumption, incur no per-dispatch cost for a feature that they never end up using. If the result is a little more cost for those using the feature, so be it. In fact, early benchmarking shows callsame with wrap and method calls seems to be up to 10 times faster using the new dispatcher than in current Rakudo, and that’s before the specializer understands enough about it to improve things further!
Everything I’ve discussed above is implemented, except that I may have given the impression somewhere that multiple dispatch is fully implemented using the new dispatcher, and that is not the case yet (no handling of where clauses and no dispatch resumption support).
Getting the missing bits of multiple dispatch fully implemented is the obvious next step. The other missing semantic piece is support for callwith and nextwith, where we wish to change the arguments that are being used when moving to the next candidate. A few other minor bits aside, that in theory will get all of the Raku dispatch semantics at least supported.
Currently, all standard method calls ($obj.meth()) and other calls (foo() and $foo()) go via the existing dispatch mechanism, not the new dispatcher. Those will need to be migrated to use the new dispatcher also, and any bugs that are uncovered will need fixing. That will get things to the point where the new dispatcher is semantically ready.
After that comes performance work: making sure that the specializer is able to deal with dispatch program guards and outcomes. The goal, initially, is to get steady state performance of common calling forms to perform at least as well as in the current master branch of Rakudo. It’s already clear enough there will be some big wins for some things that to date have been glacial, but it should not come at the cost of regression on the most common kinds of dispatch, which have received plenty of optimization effort before now.
Furthermore, NQP – the restricted form of Raku that the Rakudo compiler and other bits of the runtime guts are written in – also needs to be migrated to use the new dispatcher. Only when that is done will it be possible to rip out the current method cache, multiple dispatch cache, and so forth from MoarVM.
An open question is how to deal with backends other than MoarVM. Ideally, the new dispatch mechanism will be ported to those. A decent amount of it should be possible to express in terms of the JVM’s invokedynamic (and this would all probably play quite well with a Truffle-based Raku implementation, although I’m not sure there is a current active effort in that area).
While my current focus is to ship a Rakudo and MoarVM release that uses the new dispatcher mechanism, that won’t be the end of the journey. Some immediate ideas:
handles (delegation) and FALLBACK (handling missing method call) mechanisms can be made to perform better using the new dispatcherassuming – used to curry or otherwise prime arguments for a routine – is not ideal, and an implementation that takes advantage of the argument rewriting capabilities of the new dispatcher would likely perform a great deal betterSome new language features may also be possible to provide in an efficient way with the help of the new dispatch mechanism. For example, there’s currently not a reliable way to try to invoke a piece of code, just run it if the signature binds, or to do something else if it doesn’t. Instead, things like the Cro router have to first do a trial bind of the signature, and then do the invoke, which makes routing rather more costly. There’s also the long suggested idea of providing pattern matching via signatures with the when construct (for example, when * -> ($x) {}; when * -> ($x, *@tail) { }), which is pretty much the same need, just in a less dynamic setting.
Working on the new dispatch mechanism has been a longer journey than I first expected. The resumption part of the design was especially challenging, and there’s still a few important details to attend to there. Something like four potential approaches were discarded along the way (although elements of all of them influenced what I’ve described in this post). Abstractions that hold up are really, really, hard.
I also ended up having to take a couple of months away from doing Raku work at all, felt a bit crushed during some others, and have been juggling this with the equally important RakuAST project (which will be simplified by being able to assume the presence of the new dispatcher, and also offers me a range of softer Raku hacking tasks, whereas the dispatcher work offers few easy pickings).
Given all that, I’m glad to finally be seeing the light at the end of the tunnel. The work that remains is enumerable, and the day we ship a Rakudo and MoarVM release using the new dispatcher feels a small number of months away (and I hope writing that is not tempting fate!)
The new dispatcher is probably the most significant change to MoarVM since I founded it, in so far as it sees us removing a bunch of things that have been there pretty much since the start. RakuAST will also deliver the greatest architectural change to the Rakudo compiler in a decade. Both are an opportunity to fold years of learning things the hard way into the runtime and compiler. I hope when I look back at it all in another decade’s time, I’ll at least feel I made more interesting mistakes this time around.
Many years back, Larry Wall shared his thesis on the nature of scripting. Since recently even Java gained 'script' support I thought it would be fitting to revisit the topic, and hopefully relevant to the perl and raku language community.
The weakness of Larry's treatment (which, to be fair to the author, I think is more intended to be enlightening than to be complete) is the contrast of scripting with programming. This contrast does not permit a clear separation because scripts are programs. That is to say, no matter how long or short, scripts are written commands for a machine to execute, and I think that's a pretty decent definition of a program in general.
A more useful contrast - and, I think, the intended one - is between scripts and other sorts of programs, because that allows us to compare scripting (writing scripts) with 'programming' (writing non-script programs). And to do that we need to know what other sorts of programs there are.
The short version of that answer is - systems and applications, and a bunch of other things that aren't really relevant to the working programmer, like (embedded) control algorithms, spreadsheets and database queries. (The definition I provided above is very broad, by design, because I don't want to get stuck on boundary questions). Most programmers write applications, some write systems, virtually all write scripts once in a while, though plenty of people who aren't professional programmers also write scripts.
I think the defining features of applications and systems are, respectively:
Consider for instance a mail client (like thunderbird) in comparison to a mailer daemon (like sendmail) - one provides an interface to read and write e-mails (the model) and the other provides functionality to send that e-mail to other servers.
Note that under this (again, broad) definition, libraries are also system software, which makes sense, considering that their users are developers (just as for, say, PostgreSQL) who care about things like performance, reliability, and correctness. Incidentally, libraries as well as 'typical' system software (such as database engines and operating system kernels) tend to be written in languages like C and C++ for much the same reasons.
What then, are the differences between scripts, applications, and systems? I think the following is a good list:
Obviously these distinctions aren't really binary - 'short' versus 'long', 'ad-hoc' versus 'general purpose' - and can't be used to conclusively settle the question whether something is a script or an application. (If, indeed, that question ever comes up). More important is that for the 10 or so scripts I've written over the past year - some professionally, some not - all or most of these properties held, and I'd be surprised if the same isn't true for most readers.
And - finally coming at the point that I'm trying to make today - these features point to a specific niche of programs more than to a specific technology (or set of technologies). To be exact, scripts are (mostly) short, custom programs to automate ad-hoc tasks, tasks that are either to specific or too small to develop and distribute another program for.
This has further implications on the preferred features of a scripting language (taken to mean, a language designed to enable the development of scripts). In particular:
This niche doesn't always exist. In computing environments where everything of interest is adequately captured by an application, or which lacks the ability to effectively automate ad-hoc tasks (I'm thinking in particular of Windows before PowerShell), the practice of scripting tends to not develop. Similarily, in a modern 'cloud' environment, where system setup is controlled by a state machine hosted by another organization, scripting doesn't really have much of a future.
To put it another way, scripting only thrives in an environment that has a lot of 'scriptable' tasks; meaning tasks for which there isn't already a pre-made solution available, environments that have powerful facilities available for a script to access, and whose users are empowered to automate those tasks. Such qualities are common on Unix/Linux 'workstations' but rather less so on smartphones and (as noted before) cloud computing environments.
Truth be told I'm a little worried about that development. I could point to, and expound on, the development and popularity of languages like go and rust, which aren't exactly scripting languages, or the replacement of Javascript with TypeScript, to make the point further, but I don't think that's necessary. At the same time I could point to the development of data science as a discipline to demonstrate that scripting is alive and well (and indeed perhaps more economically relevant than before).
What should be the conclusion for perl 5/7 and raku? I'm not quite sure, mostly because I'm not quite sure whether the broader perl/raku community would prefer their sister languages to be scripting or application languages. (As implied above, I think the Python community chose that they wanted Python 3 to be an application language, and this was not without consequences to their users).
Raku adds a number of features common to application languages (I'm thinking of it's powerful type system in particular), continuing a trend that perl 5 arguably pioneered. This is indeed a very powerful strategy - a language can be introduced for scripts and some of those scripts are then extended into applications (or even systems), thereby ensuring its continued usage. But for it to work, a new perl family language must be introduced on its scripting merits, and there must be a plentiful supply of scriptable tasks to automate, some of which - or a combination of which - grow into an application.
For myself, I would like to see scripting have a bright future. Not just because scripting is the most accessible form of programming, but also because an environment that permits, even requires scripting, is one were not all interesting problems have been solved, one where it's users ask it to do tasks so diverse that there isn't an app for that, yet. One where the true potential of the wonderful devices that surround is can be explored.
In such a world there might well be a bright future for scripting.
I’d like to thank everyone who voted for me in the recent Raku Steering Council elections. By this point, I’ve been working on the language for well over a decade, first to help turn a language design I found fascinating into a working implementation, and since the Christmas release to make that implementation more robust and performant. Overall, it’s been as fun as it has been challenging – in a large part because I’ve found myself sharing the journey with a lot of really great people. I’ve also tried to do my bit to keep the community around the language kind and considerate. Receiving a vote from around 90% of those who participated in the Steering Council elections was humbling.
Alas, I’ve today submitted my resignation to the Steering Council, on personal health grounds. For the same reason, I’ll be taking a step back from Raku core development (Raku, MoarVM, language design, etc.) Please don’t worry too much; I’ll almost certainly be fine. It may be I’m ready to continue working on Raku things in a month or two. It may also be longer. Either way, I think Raku will be better off with a fully sized Steering Council in place, and I’ll be better off without the anxiety that I’m holding a role that I’m not in a place to fulfill.

Hello everyone! In the last report I said that just a little bit of work on the heap snapshot portion of the UI should result in a useful tool.
Photo by Sticker Mule / Unsplash
Here's my report for the first useful pieces of the Heap Snapshot UI!
Last time you already saw the graphs showing how the number of instances of a given type or frame grow and shrink over the course of multiple snapshots, and how new snapshots can be requested from the UI.
The latter now looks a little bit different:
(Sorry, I lost the screenshot when I took down my blog the last time!)
Each snapshot now has a little button for itself, they are in one line instead of each snapshot having its own line, and the progress bar has been replaced with a percentage and a little "spinner".
There are multiple ways to get started navigating the heap snapshot. Everything is reachable from the "Root" object (this is the norm for reachability-based garbage collection schemes). You can just click through from there and see what you can find.
Another way is to look at the Type & Frame Lists, which show every type or frame along with the number of instances that exist in the heap snapshot, and the total size taken up by those objects.
(Sorry, I lost the screenshot when I took down my blog the last time!)
Clicking on a type, or the name or filename of a frame leads you to a list of all objects of that type, all frames with the given name, or all frames from the given file. They are grouped by size, and each object shows up as a little button with the ID:
(Sorry, I lost the screenshot when I took down my blog the last time!)
Clicking any of these buttons leads you to the Explorer.
Here's a screenshot of the explorer to give you an idea of how the parts go together that I explain next:
(Sorry, I lost the screenshot when I took down my blog the last time!)
The explorer is split into two identical panels, which allows you to compare two objects, or to explore in multiple directions from one given object.
There's an "Arrow to the Right" button on the left pane and an "Arrow to the Left" button on the right pane. These buttons make the other pane show the same object that the one pane currently shows.
On the left of each pane there's a "Path" display. Clicking the "Path" button in the explorer will calculate the shortest path to reach the object from the root. This is useful when you've got an object that you would expect to have already been deleted by the garbage collector, but for some reason is still around. The path can give the critical hint to figure out why it's still around. Maybe one phase of the program has ended, but something is still holding on to a cache that was put in as an optimization, and that still has your object in it? That cache in question would be on the path for your object.
The other half of each panel shows information about the object: Displayed at the very top is whether it is an object, a type object, an STable, or a frame.
Below that there is an input field where you can enter any ID belonging to a Collectable (the general term encompassing types, type objects, stables, and frames) to have a look.
The "Kind" field needs to have the number values replaced with human-readable text, but it's not the most interesting thing anyway.
The "Size" of the Collectable is split into two parts. One is the fixed size that every instance of the given type has. The other is any extra data an instance of this type may have attached to it, that's not a Collectable itself. This would be the case for arrays and hashes, as well as buffers and many "internal" objects.
Finally, the "References" field shows how many Collectables are referred to by the Collectable in question (outgoing references) and how many Collectables reference this object in question.
Below that there are two buttons, Path and Network. The former was explained further above, and the latter will get its own little section in this blog post.
Finally, the bottom of the panel is dedicated to a list of all references - outgoing or incoming - grouped by what the reference means, and what type it references.
(Sorry, I lost the screenshot when I took down my blog the last time!)
In this example you see that the frame of the function display from elementary2d.p6 on line 87 references a couple of variables ($_, $tv, &inv), the frame that called this frame (step), an outer frame (MAIN), and a code object. The right pane shows the incoming references. For incoming references, the name of the reference isn't available (yet), but you can see that 7 different objects are holding a reference to this frame.
The newest part of the heap snapshot UI is the Network View. It allows the user to get a "bird's eye" view of many objects and their relations to each other.
Here's a screenshot of the network view in action:
(Sorry, I lost the screenshot when I took down my blog the last time!)
The network view is split into two panes. The pane on the left lists all types present in the network currently. It allows you to give every type a different symbol, a different color, or optionally make it invisible. In addition, it shows how many of each type are currently in the network display.
The right pane shows the objects, sorted by how far they are from the root (object 0, the one in Layer 0, with the frog icon).
Each object has one three-piece button. On the left of the button is the icon representing the type, in the middle is the object ID for this particular object, and on the right is an icon for the "relation" this object has to the "selected" object:
This view was generated for object 46011 (in layer 4, with a hamburger as the icon). This object gets the little "map marker pin" icon to show that it's the "center" of the network. In layers for distances 3, 2, and 1 there is one object each with a little icon showing two map marker pins connected with a squiggly line. This means that the object is part of the shortest path to the root. The third kind of icon is an arrow pointing from the left into a square that's on the right. Those are objects that refer to the selected object.
There is also an icon that's the same but the arrow goes outwards from the square instead of inwards. Those are objects that are referenced by the selected object. However, there is currently no button to have every object referenced by the selected object put into the network view. This is one of the next steps I'll be working on.
Customizing the colors and visibility of different types can give you a view like this:
(Sorry, I lost the screenshot when I took down my blog the last time!)
And here's a view with more objects in it:
(Sorry, I lost the screenshot when I took down my blog the last time!)
Interesting observations from this image:
You have no doubt noticed that the buttons for collectables are very different between the network view and the type/frame lists and the explorer. The reason for that is that I only just started with the network view and wanted to display more info for each collectable (namely the icons to the left and right) and wanted them to look nicer. In the explorer there are sometimes thousands of objects in the reference list, and having big buttons like in the network view could be difficult to work with. There'll probably have to be a solution for that, or maybe it'll just work out fine in real-world use cases.
On the other hand, I want the colors and icons for types to be available everywhere, so that it's easier to spot common patterns across different views and to mark things you're interested in so they stand out in lists of many objects. I was also thinking of a "bookmark this object" feature for similar purposes.
Before most of that, the network viewer will have to become "navigable", i.e. clicking on an object should put it in the center, grab the path to the root, grab incoming references, etc.
There also need to be ways to handle references you're not (or no longer) interested in, especially when you come across an object that has thousands of them.
But until then, all of this should already be very useful!
Here's the section about the heap snapshot profiler from the original grant proposal:
Looking at the list, it seems like the majority of intended features are already available or will be very soon!
Until now the user had to download nodejs and npm along with a whole load of javascript libraries in order to compile and bundle the javascript code that powers the frontend of moarperf.
Fortunately, it was relatively easy to get travis-ci to do the work automatically and upload a package with the finished javascript code and the backend code to github.
You can now visit the releases page on github to grab a tarball with all the files you need! Just install all backend dependencies with zef install --deps-only . and run service.p6!
And with that I'm already done for this report!
It looks like the heap snapshot portion of the grant is quite a bit smaller than the profiler part, although a lot of work happened in moarvm rather than the UI. I'm glad to see rapid progress on this.
I hope you enjoyed this quick look at the newest pieces of moarperf!
- Timo
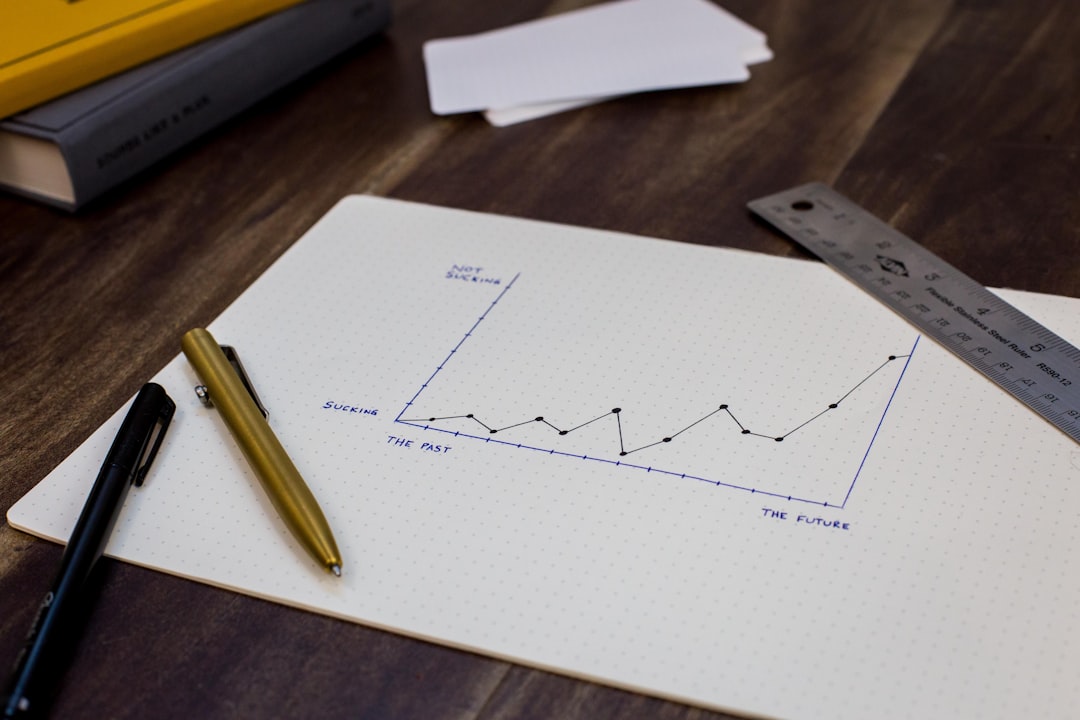
It has been a while since the last progress report, hasn't it?
Over the last few months I've been focusing on the MoarVM Heap Snapshot Profiler. The new format that I explained in the last post, "Intermediate Progress Report: Heap Snapshots", is available in the master branch of MoarVM, and it has learned a few new tricks, too.
The first thing I usually did when opening a Heap Snapshot in the heapanalyzer (the older command-line based one) was to select a Snapshot, ask for the summary, and then for the top objects by size, top objects by count, top frames by size, and/or top frames by count to see if anything immediately catches my eye. In order to make more sense of the results, I would repeat those commands for one or more other Snapshots.
Snapshot Heap Size Objects Type Objects STables Frames References
======== ================= ======= ============ ======= ====== ==========
0 46,229,818 bytes 331,212 686 687 1,285 1,146,426
25 63,471,658 bytes 475,587 995 996 2,832 1,889,612
50 82,407,275 bytes 625,958 1,320 1,321 6,176 2,741,066
75 97,860,712 bytes 754,075 1,415 1,416 6,967 3,436,141
100 113,398,840 bytes 883,405 1,507 1,508 7,837 4,187,184
Snapshot Heap Size Objects Type Objects STables Frames References
======== ================= ========= ============ ======= ====== ==========
125 130,799,241 bytes 1,028,928 1,631 1,632 9,254 5,036,284
150 145,781,617 bytes 1,155,887 1,684 1,685 9,774 5,809,084
175 162,018,588 bytes 1,293,439 1,791 1,792 10,887 6,602,449
Realizing that the most common use case should be simple to achieve, I first implemented a command summary all and later a command summary every 10 to get the heapanalyzer to give the summaries of multiple Snapshots at once, and to be able to get summaries (relatively) quickly even if there's multiple hundreds of snapshots in one file.
Sadly, this still requires the parser to go through the entire file to do the counting and adding up. That's obviously not optimal, even though this is an Embarrassingly Parallel task, and it can use every CPU core in the machine you have, it's still a whole lot of work just for the summary.
For this reason I decided to shift the responsibility for this task to MoarVM itself, to be done while the snapshot is taken. In order to record everything that goes into the Snapshot, MoarVM already differentiates between Object, Type Object, STable, and Frame, and it stores all references anyway. I figured it shouldn't have a performance impact to just add up the numbers and make them available in the file.
The result is that the summary table as shown further above is available only milliseconds after loading the heap snapshot file, rather than after an explicit request and sometimes a lengthy wait period.
The next step was to see if top objects by size and friends could be made faster in a similar way.
I decided that adding an optional "statistics collection" feature inside of MoarVM's heap snapshot profiler would be worthwhile. If it turns out that the performance impact of summing up sizes and counts on a per-type and per-frame basis makes capturing a snapshot too slow, it could be turned off.
> snapshot 50
Loading that snapshot. Carry on...
> top frames by size
Wait a moment, while I finish loading the snapshot...
Name Total Bytes
==================================== =============
finish_code_object (World.nqp:2532) 201,960 bytes
moarop_mapper (QAST.nqp:1764) 136,512 bytes
!protoregex (QRegex.nqp:1625) 71,760 bytes
new_type (Metamodel.nqp:1345) 40,704 bytes
statement (Perl6-Grammar.nqp:951) 35,640 bytes
termish (Perl6-Grammar.nqp:3641) 34,720 bytes
<anon> (Perl6-BOOTSTRAP.c.nqp:1382) 29,960 bytes
EXPR (Perl6-Grammar.nqp:3677) 27,200 bytes
<mainline> (Perl6-BOOTSTRAP.c.nqp:1) 26,496 bytes
<mainline> (NQPCORE.setting:1) 25,896 bytes
EXPR (NQPHLL.nqp:1186) 25,760 bytes
<anon> (<null>:1) 25,272 bytes
declarator (Perl6-Grammar.nqp:2189) 23,520 bytes
<anon> (<null>:1) 22,464 bytes
<anon> (<null>:1) 22,464 bytes
Showing the top objects or frame for a single snapshot is fairly straight-forward in the commandline based UI, but how would you display how a type or frame develops its value across many snapshots?
Instead of figuring out the best way to display this data in the commandline, I switched focus to the Moarperf Web Frontend. The most obvious way to display data like this is a Line Graph, I believe. So that's what we have now!

And of course you also get to see the data from each snapshot's Summary in graph format:

And now for the reason behind this blog post's Title.
Using Jonathan's module Concurrent::Progress (with a slight modification) I sprinkled the code to parse a snapshot with matching calls of .increment-target and .increment. The resulting progress reports (throttled to at most one per second) are then forwarded to the browser via the WebSocket connection that already delivers many other bits of data.
The result can be seen in this tiny screencast:

The recording is rather choppy because the heapanalyzer code was using every last drop of performance out of my CPU while it was trying to capture my screen.
There's obviously a lot still missing from the heap snapshot analyzer frontend GUI, but I feel like this is a good start, and even provides useful features already. The graphs for the summary data are nicer to read than the table in the commandline UI, and it's only in this UI that you can get a graphical representation of the "highscore" lists.
I think a lot of the remaining features will already be useful after just the initial pieces are in place, so a little work should go a long way.
I didn't spend the whole time between the last progress report and now to work directly on the features shown here. Apart from Life Intervening™, I worked on fixing many frustrating bugs related to both of the profilers in MoarVM. I added a small subsystem I call VMEvents that allows user code to be notified when GC runs happen and other interesting bits from inside MoarVM itself. And of course I've been assisting other developers by answering questions and looking over their contributions. And of course there's the occasional video-game-development related experiment, for example with the GTK Live Coding Tool.
Finally, here's a nice little screencap of that same tool displaying a hilbert curve:

That's already everything I have for this time. A lot has (had to) happen behind the scenes to get to this point, but now there was finally something to look at (and touch, if you grab the source code and go through the needlessly complicated build process yourself).
Thank you for reading and I hope to see you in the next one!
- Timo
 |
| Both ADD and SUB refer to the same LOAD node |
 |
| The DO node is inserted for the LET operator. It ensures that the value of the LOAD node is computed before the reference in either branch |
I want to revive Carl Mäsak's Coding Contest as a crowd-sourced contest.
The contest will be in four phases:
For the first phase, development of tasks, I am looking for volunteers who come up with coding tasks collaboratively. Sadly, these volunteers, including myself, will be excluded from participating in the second phase.
I am looking for tasks that ...
This is non-trivial, so I'd like to have others to discuss things with, and to come up with some more tasks.
If you want to help with task creation, please send an email to [email protected], stating your intentions to help, and your freenode IRC handle (optional).
There are other ways to help too:
In these cases you can use the same email address to contact me,
or use IRC (moritz on freenode) or twitter.

After a perilous drive up a steep, narrow, winding road from Lake Geneva we arrived at an attractive Alpine village (Villars-sur-Ollon) to meet with fellow Perl Mongers in a small restaurant. There followed much talk and a little clandestine drinking of exotic spirits including Swiss whisky. The following morning walking to the conference venue there was an amazing view of mountain ranges. On arrival I failed to operate the Nespresso machine which I later found was due to it simply being off. Clearly software engineers should never try to use hardware. At least after an evening of drinking.
Wendy’s stall was piled high with swag including new Bailador (Perl 6 dancer like framework) stickers, a Shadowcat booklet about Perl 6 and the new O’Reilly “Thinking in Perl 6″. Unfortunately she had sold out of Moritz’s book “Perl 6 Fundamentals” (although there was a sample display copy present). Thankfully later that morning I discovered I had a £3 credit on Google Play Books so I bought the ebook on my phone.
The conference started early with Damian Conway’s Three Little Words. These were “has”, “class” and “method” from Perl 6 which he liked so much that he had added them to Perl 5 with his “Dios” – “Declarative Inside-Out Syntax” module. PPI wasn’t fast enough so he had to replace it with a 50,000 character regex PPR. Practical everyday modules mentioned included Regexp::Optimizer and Test::Expr. If the video doesn’t appear shortly on youtube a version of his talk dating from a few weeks earlier is available at https://www.youtube.com/watch?v=ob6YHpcXmTg
Jonathan Worthington returned with his Perl 6 talk on “How does deoptimization help us go faster?” giving us insight into why Perl 6 was slow at the Virtual Machine level (specifically MoarVM). Even apparently simple and fast operations like indexing an array were slow due to powerful abstractions, late binding and many levels of Multiple Dispatch. In short the flexibility and power of such an extensible language also led to slowness due to the complexity of code paths. The AST optimizer helped with this at compile time but itself took time and it could be better to do this at a later compile time (like Just In Time). Even with a simple program reading lines from a file it was very hard to determine statically what types were used (even with type annotations) and whether it was worth optimizing (since the file could be very short).
The solution to these dynamic problems was also dynamic but to see what was happening needed cheap logging of execution which was passed to another thread. This logging is made visible by setting the environment variable MVM_SPESH_LOG to a filename. Better tooling for this log would be a good project for someone.
For execution planning we look for hot (frequently called) code, long blocks of bytecode (slow to run) and consider how many types are used (avoiding “megamorphic” cases with many types which needs many versions of code). Also analysis of the code flow between different code blocks and SSA. Mixins made the optimization particularly problematic.
MoarVM’s Spesh did statistical analysis of the code in order to rewrite it in faster, simpler ways. Guards (cheap check for things like types) were placed to catch cases where it got it wrong and if these were triggered (infrequently) it would deoptimize as well, hence the counterintuitive title since “Deoptimization enables speculation” The slides are at http://jnthn.net/papers/2017-spw-deopt.pdf with the video at https://www.youtube.com/watch?v=3umNn1KnlCY The older and more dull witted of us (including myself) might find the latter part of the video more comprehensible at 0.75 Youtube speed.
After a superb multi-course lunch (the food was probably the best I’d had at any Perl event) we returned promptly to hear Damian talk of “Everyday Perl 6”. He pointed out that it wasn’t necessary to code golf obfuscated extremes of Perl 6 and that the average Perl 5 programmer would see many things simpler in Perl 6. Also a rewrite from 5 to 6 might see something like 25% fewer lines of code since 6 was more expressive in syntax (as well as more consistent) although performance problems remained (and solutions in progress as the previous talk had reminded us).
Next Liz talked of a “gross” (in the numerical sense of 12 x 12 rather than the American teen sense) of Perl 6 Weeklies as she took us down memory lane to 2014 (just about when MoarVM was launched and when unicode support was poor!) with some selected highlights and memories of Perl 6 developers of the past (and hopefully future again!). Her talk was recorded at https://www.youtube.com/watch?v=418QCTXmvDU

Cal then spoke of Perl 6 maths which he thought was good with its Rats and FatRats but not quite good enough and his ideas of fixing it. On the following day he showed us he had started some TDD work on TrimRats. He also told us that Newton’s Method wasn’t very good but generated a pretty fractal. See https://www.youtube.com/watch?v=3na_Cx-anvw
Lee spoke about how to detect Perl 5 memory leaks with various CPAN modules and his examples are at https://github.com/leejo/Perl_memory_talk
The day finished with Lightning Talks and a barbecue at givengain — a main sponsor.
On the second day I noticed the robotic St Bernards dog in a tourist shop window had come to life.

Damian kicked off the talks with my favourite of his talks, “Standing on the Shoulders of Giants”, starting with the Countess of Lovelace and her Bernoulli number program. This generated a strange sequence with many zeros. The Perl 6 version since it used rational numbers not floating point got the zeros right whereas the Perl 5 version initially suffered from floating point rounding errors (which are fixable).
Among other things he showed us how to define a new infix operator in Perl 6. He also showed us a Perl 6 sort program that looked exactly like LISP even down to the Lots of Irritating Superfluous Parentheses. I think this was quicksort (he certainly showed us a picture of Sir Tony Hoare at some point). Also a very functional (Haskell-like) equivalent with heavy use of P6 Multiple Dispatch. Also included was demonstration of P6 “before” as a sort of typeless/multi-type comparison infix. Damian then returned to his old favourite of Quantum Computing.
My mind and notes got a bit jumbled at this point but I particularly liked the slide that explained how factorisation could work by observing the product of possible inputs since this led to a collapse that revealed the factors. To do this on RSA etc., of course, needs real hardware support which probably only the NSA and friends have (?). Damian’s code examples are at http://www.bit.do/Perl6SOG with an earlier version of his talk at https://www.youtube.com/watch?v=Nq2HkAYbG5o Around this point there was a road race of classic cars going on outside up the main road into the village and there were car noises in the background that strangely were more relaxing than annoying.

After Quantum Chaos Paul Johnson brought us all back down to ground with an excellent practical talk on modernising legacy Perl 5 applications based on his war stories. Hell, of course, is “Other People’s Code”, often dating from Perl’s early days and lacking documentation and sound engineering.
Often the original developers had long since departed or, in the worse cases, were still there. Adding tests and logging (with stack traces) were particularly useful. As was moving to git (although its steep learning curve meant mentoring was needed) and handling CPAN module versioning with pinto. Many talks had spoken of the Perl 6 future whereas this spoke of the Perl 5 past and present and the work many of us suffer to pay the bills. It’s at https://www.youtube.com/watch?v=4G5EaUNOhR0

Jonathan then spoke of reactive distributed software. A distributed system is an async one where “Is it working?” means “some of it is working but we don’t know which bits”. Good OO design is “tell don’t ask” — you tell remote service to do something for you and not parse the response and do it yourself thus breaking encapsulation. This is particularly important in building well designed distributed systems since otherwise the systems are less responsive and reliable. Reactive (async) works better for distributed software than interactive (blocking or sync).
We saw a table that used a Perl 6 promise for one value and a supply for many values for reactive (async) code and the equivalent (one value) and a Perl 6 Seq for interactive code. A Supply could be used for pub/sub and the Observer Pattern. A Supply could either be live (like broadcast TV) or, for most Perl 6 supplies, on-demand (like Netflix). Then samples of networking (socket) based code were discussed including a web client, web server and SSH::LibSSH (async client bindings often very useful in practical applications like port forwarding)
https://github.com/jnthn/p6-ssh-libssh
Much of the socket code had a pattern of “react { whenever {” blocks with “whenever” as a sort of async loop.He then moved on from sockets to services (using a Supply pipeline) and amazed us by announcing the release of “cro”, a microservices library that even supports HTTP/2 and Websockets, at http://mi.cro.services/. This is installable using Perl 6 by “zef install –/test cro”.
Slides at http://jnthn.net/papers/2017-spw-sockets-services.pdf and video at https://www.youtube.com/watch?v=6CsBDnTUJ3A
Next Lee showed Burp Scanner which is payware but probably the best web vulnerabilities scanner. I wondered if anyone had dare run it on ACT or the hotel’s captive portal.
Wendy did some cheerleading in her “Changing Image of Perl”. An earlier version is at https://www.youtube.com/watch?v=Jl6iJIH7HdA
Sue’s talk was “Spiders, Gophers, Butterflies” although the latter were mostly noticeably absent. She promises me that a successor version of the talk will use them more extensively. Certainly any Perl 6 web spidering code is likely to fit better on one slide than the Go equivalent.
During the lightning talks Timo showed us a very pretty Perl 6 program using his SDL2::Raw to draw an animated square spiral with hypnotic colour cycling type patterns. Also there was a talk by the author about https://bifax.org/bif/— a distributed bug tracking system (which worked offline like git).
Later in the final evening many of us ate and chatted in another restaurant where we witnessed a dog fight being narrowly averted and learnt that Wendy didn’t like Perl 5’s bless for both technical and philosophical reasons.
Time for some old man's reminiscence. Or so it feels when I realize that I've spent more than 10 years involved with the Perl 6 community.
It was February 2007.
I was bored. I had lots of free time (crazy to imagine that now...), and I spent some of that answering (Perl 5) questions on perlmonks. There was a category of questions where I routinely had no good answers, and those were related to threads. So I decided to play with threads, and got frustrated pretty quickly.
And then I remember that a friend in school had told me (about four years earlier) that there was this Perl 6 project that wanted to do concurrency really well, and even automatically parallelize some stuff. And this was some time ago, maybe they had gotten anywhere?
So I searched the Internet, and found out about Pugs, a Perl 6 compiler written in Haskell. And I wanted to learn more, but some of the links to the presentations were dead. I joined the #perl6 IRC channel to report the broken link.
And within three minutes I got a "thank you" for the report, the broken links were gone, and I had an invitation for a commit bit to the underlying SVN repo.
I stayed.
Those were they wild young days of Perl 6 and Pugs. Audrey Tang was pushing Pugs (and Haskell) very hard, and often implemented a feature within 20 minutes after somebody mentioned it. Things were unstable, broken often, and usually fixed quickly. No idea was too crazy to be considered or even implemented.
We had bots that evaluated Perl 6 and Haskell code, and gave the result directly on IRC. There were lots of cool (and sometimes somewhat frightening) automations, for example for inviting others to the SVN repo, to the shared hosting system (called feather), for searching SVN logs and so on. Since git was still an obscure and very unusable, people tried to use SVK, an attempt to implement a decentralized version control system on top of of the SVN protocol.
Despite some half-hearted attempts, I didn't really make inroads into compiler developments. Having worked with neither Haskell nor compilers before proved to be a pretty steep step. Instead I focused on some early modules, documentation, tests, and asking and answering questions. When the IRC logger went offline for a while, I wrote my own, which is still in use today.
I felt at home in that IRC channel and the community. When the community asked for mentors for the Google Summer of Code project, I stepped up. The project was a revamp of the Perl 6 test suite, and to prepare for mentoring task, I decided to dive deeper. That made me the maintainer of the test suite.
I can't recount a full history of Perl 6 projects during that time range, but I want to reflect on some projects that I considered my pet projects, at least for some time.
It is not quite clear from this (very selected) timeline, but my Perl 6 related activity dropped around 2009 or 2010. This is when I started to work full time, moved in with my girlfriend (now wife), and started to plan a family.
The technologies and ideas in Perl 6 are fascinating, but that's not what kept me. I came for the technology, but stayed for the community.
There were and are many great people in the Perl 6 community, some of whom I am happy to call my friends. Whenever I get the chance to attend a Perl conference, workshop or hackathon, I find a group of Perl 6 hackers to hang out and discuss with, and generally have a good time.
Four events stand out in my memory. In 2010 I was invited to the Open Source Days in Copenhagen. I missed most of the conference, but spent a day or two with (if memory serve right) Carl Mäsak, Patrick Michaud, Jonathan Worthington and Arne Skjærholt. We spent some fun time trying to wrap our minds around macros, the intricacies of human and computer language, and Japanese food. (Ok, the last one was easy). Later the same year, I attended my first YAPC::EU in Pisa, and met most of the same crowd again -- this time joined by Larry Wall, and over three or four days. I still fondly remember the Perl 6 hallway track from that conference. And 2012 I flew to Oslo for a Perl 6 hackathon, with a close-knit, fabulous group of Perl 6 hackers. Finally, the Perl Reunification Summit in the beautiful town of Perl in Germany, which brought together Perl 5 and Perl 6 hackers in a very relaxed atmosphere.
For three of these four events, different private sponsors from the Perl and Perl 6 community covered travel and/or hotel costs, with their only motivation being meeting folks they liked, and seeing the community and technology flourish.
The Perl 6 community has evolved a lot over the last ten years, but it is still a very friendly and welcoming place. There are lots of "new" folks (where "new" is everybody who joined after me, of course :D), and a surprising number of the old guard still hang around, some more involved, some less, all of them still very friendly and supportive
I anticipate that my family and other projects will continue to occupy much of my time, and it is unlikely that I'll be writing another Perl 6 book (after the one about regexes) any time soon. But the Perl 6 community has become a second home for me, and I don't want to miss it.
In the future, I see myself supporting the Perl 6 community through infrastructure (community servers, IRC logs, running IRC bots etc.), answering questions, writing a blog article here and there, but mostly empowering the "new" guard to do whatever they deem best.
After about nine months of work, my book Perl 6 Fundamentals is now available for purchase on apress.com and springer.com.
The ebook can be purchased right now, and comes in the epub and PDF formats (with watermarks, but DRM free). The print form can be pre-ordered from Amazon, and will become ready for shipping in about a week or two.
I will make a copy of the ebook available for free for everybody who purchased an earlier version, "Perl 6 by Example", from LeanPub.
The book is aimed at people familiar with the basics of programming; prior
Perl 5 or Perl 6 knowledge is not required. It features a practical example in most chapters (no mammal hierarchies or class Rectangle inheriting from class Shape), ranging from simple input/output and text formatting to plotting with python's matplotlib libraries. Other examples include date and time conversion, a Unicode search tool and a directory size visualization.
I use these examples to explain subset of Perl 6, with many pointers to more
documentation where relevant. Perl 6 topics include the basic lexicographic
structure, testing, input and output, multi dispatch, object orientation, regexes and grammars, usage of modules, functional programming and interaction
with python libraries through Inline::Python.
Let me finish with Larry Wall's description of this book, quoted from his foreword:
It's not just a reference, since you can always find such materials online. Nor is it just a cookbook. I like to think of it as an extended invitation, from a well-liked and well-informed member of our circle, to people like you who might want to join in on the fun. Because joy is what's fundamental to Perl. The essence of Perl is an invitation to love, and to be loved by, the Perl community. It's an invitation to be a participant of the gift economy, on both the receiving and the giving end.
The Perl 6 naming debate has started again. And I guess with good reason. Teaching people that Perl 6 is a Perl, but not the Perl requires too much effort. Two years ago, I didn't believe. Now you're reading a tired man's words.
I'm glad that this time, we're not discussing giving up the "Perl" brand, which still has very positive connotations in my mind, and in many other minds as well.
And yet, I can't bring myself to like "Rakudo Perl 6" as a name. There are two vary shallow reasons for that: Going from two syllables, "Perl six", to five of them, seems a step in the wrong direction. And two, I remember the days when the name was pretty young, and people would misspell it all the time. That seems to have abated, though I don't know why.
But there's also a deeper reason, probably sentimental old man's reason. I remember the days when Pugs was actively developed, and formed the center of a vibrant community. When kp6 and SMOP and all those weird projects were around. And then, just when it looked like there was only a single compiler was around, Stefan O'Rear conjured up niecza, almost single-handedly, and out of thin air. Within months, it was a viable Perl 6 compiler, that people on #perl6 readily recommended.
All of this was born out of the vision that Perl 6 was a language with no single, preferred compiler. Changing the language name to include the compiler name means abandoning this vision. How can we claim to welcome alternative implementations when the commitment to one compiler is right in the language name?
However I can't weigh this loss of vision against a potential gain in popularity. I can't decide if it's my long-term commitment to the name "Perl 6" that makes me resent the new name, or valid objections. The lack of vision mirrors my own state of mind pretty well.
I don't know where this leaves us. I guess I must apologize for wasting your time by publishing this incoherent mess.
Perl 6 is innovative in many ways, and sometimes we don't fully appreciate all the implications, for good or for bad.
There's one I stumbled upon recently: The use of fancy Unicode symbols for built-in stuff. In this case: the `.gist` output of Match objects. For example
my token word { \w+ } say 'abc=def' ~~ /<word> '=' <word>/;produces this output:
「abc=def」 word => 「abc」 word => 「def」
And that's where the problems start. In my current quest to write a book on Perl 6 regexes, I noticed that the PDF that LeanPub generates from my Markdown sources don't correctly display those pesky 「」 characters, which are
$ uni -c 「」 「 - U+0FF62 - HALFWIDTH LEFT CORNER BRACKET 」 - U+0FF63 - HALFWIDTH RIGHT CORNER BRACKET
When I copied the text from the PDF and pasted into my editor, they showed up correctly, which indicates that the characters are likely missing from the monospace font.
The toolchain allows control over the font used for displaying code, so I tried all the monospace fonts that were available. I tried them in alphabetical order. Among the earlier fonts I tried was Deja Vu Sans Mono, which I use in my terminal, and which hasn't let me down yet. No dice. I arrived at Noto, a font designed to cover all Unicode codepoints. And it didn't work either. So it turns out these two characters are part of some Noto Sans variants, but not of the monospace font.
My terminal, and even some font viewers, use some kind of fallback where they use glyphs from other fonts to render missing characters. The book generation toolchain does not.
The Google Group for Leanpub was somewhat helpful: if I could recommend an Open Source mono space font that fit my needs, they'd likely include it in their toolchain.
So I searched and searched, learning more about fonts than I wanted to know. My circle of geek friends came up with several suggestions, one of them being Iosevka, which actually contains those characters. So now I wait for others to step up, either for LeanPub to include that font, or for the Noto maintainers to create a monospace variant of those characters (and then LeanPub updating their version of the font).
And all of that because Perl 6 was being innovative, and used two otherwise little-used characters as delimiters, in an attempt to avoid collisions between delimiters and content.
(In the mean time I've replaced the two offending characters with ones that look similar. It means the example output is technically incorrect, but at least it's readable).
At YAPC::EU 2010 in Pisa I received a business card with "Rakudo Star" and the
date July 29, 2010 which was the date of the first release -- a week earlier
with a countdown to 1200 UTC. I still have mine, although it has a tea stain
on it and I refreshed my memory over the holidays by listening again to Patrick
Michaud speaking about the launch of Rakudo Star (R*):
https://www.youtube.com/watch?v=MVb6m345J-Q
R* was originally intended as first of a number of distribution releases (as
opposed to a compiler release) -- useable for early adopters but not initially production
Quality. Other names had been considered at the time like Rakudo Beta (rejected as
sounding like "don't use this"!) and amusingly Rakudo Adventure Edition.
Finally it became Rakudo Whatever and Rakudo Star (since * means "whatever"!).
Well over 6 years later and we never did come up with a better name although there
was at least one IRC conversation about it and perhaps "Rakudo Star" is too
well established as a brand at this point anyway. R* is the Rakudo compiler, the main docs, a module installer, some modules and some further docs.
However, one radical change is happening soon and that is a move from panda to
zef as the module installer. Panda has served us well for many years but zef is
both more featureful and more actively maintained. Zef can also install Perl
6 modules off CPAN although the CPAN-side support is in its early days. There
is a zef branch (pull requests welcome!) and a tarball at:
http://pl6anet.org/drop/rakudo-star-2016.12.zef-beta2.tar.gz
Panda has been patched to warn that it will be removed and to advise the use of
zef. Of course anyone who really wants to use panda can reinstall it using zef
anyway.
The modules inside R* haven't changed much in a while. I am considering adding
DateTime::Format (shown by ecosystem stats to be widely used) and
HTTP::UserAgent (probably the best pure perl6 web client library right now).
Maybe some modules should also be removed (although this tends to be more
controversial!). I am also wondering about OpenSSL support (if the library is
available).
p6doc needs some more love as a command line utility since most of the focus
has been on the website docs and in fact some of these changes have impacted
adversely on command line use, eg. under Windows cmd.exe "perl 6" is no longer
correctly displayed by p6doc. I wonder if the website generation code should be
decoupled from the pure docs and p6doc command line (since R* has to ship any
new modules used by the website). p6doc also needs a better and faster search
(using sqlite?). R* also ships some tutorial docs including a PDF generated from perl6intro.com.
We only ship the English one and localisation to other languages could be
useful.
Currently R* is released roughly every three months (unless significant
breakage leads to a bug fix release). Problems tend to happen with the
less widely used systems (Windows and the various BSDs) and also with the
module installers and some modules. R* is useful in spotting these issues
missed by roast. Rakudo itself is still in rapid development. At some point a less frequently
updated distribution (Star LTS or MTS?) will be needed for Linux distribution
packagers and those using R* in production). There are also some question
marks over support for different language versions (6.c and 6.d).
Above all what R* (and Rakudo Perl 6 in general) needs is more people spending
more time working on it! JDFI! Hopefully this blog post might
encourage more people to get involved with github pull requests.
https://github.com/rakudo/star
Feedback, too, in the comments below is actively encouraged.
There is a Release Candidate for Rakudo Star 2016.11 (currently RC2) available at
http://pl6anet.org/drop/
This includes binary installers for Windows and Mac.
Usually Star is released about every three months but last month's release didn't include a Windows installer so there is another release.
I'm hoping to release the final version next weekend and would be grateful if people could try this out on as many systems as possible.
Any feedback email steve *dot* mynott *at* gmail *dot* com
Full draft announce at
https://github.com/rakudo/star/blob/master/docs/announce/2016.11.md
We turned up in Cluj via Wizz Air to probably one of the best pre YAPC parties ever located on three levels on the rooftop of Evozon’s plush city centre offices. We were well supplied with excellent wine, snacks and the local Ursus beer and had many interesting conversations with old friends.
On the first day Tux spoke about his Text::CSV modules for both Perl 5 and 6 on the first day and I did a short talk later in the day on benchmarking Perl 6. Only Nicholas understood my trainspotter joke slide with the APT and Deltic! Sadly my talk clashed with Lee J talking about Git which I wanted to see so I await the youtube version! Jeff G then spoke about Perl 6 and parsing languages such as JavaScript. Sadly I missed Leon T’s Perl 6 talk which I also plan on watching on youtube. Tina M gave an excellent talk on writing command line tools. She also started the lightning talks with an evangelical talk about how tmux was better than screen. Geoffrey A spoke about configuring sudo to run restricted commands in one directory which seemed a useful technique to me. Dave C continued his conference tradition of dusting off his Perl Vogue cover and showing it again. The age of the image was emphasised by the amazingly young looking mst on it. And Stefan S ended with a call for Perl unification.
The main social event was in the courtyard of the main museum off the central square with free food and beer all evening and an impressive light show on the slightly crumbling facade. There were some strange chairs which resembled cardboard origami but proved more comfortable than they looked when I was finally able to sit in one. The quality of the music improved as the evening progressed (or maybe the beer helped) I was amazed to see Perl Mongers actually dancing apparently inspired by the younger Cluj.pm members.
Day Two started with Sawyer’s State of the Velociraptor which he had, sensibly, subcontracted to various leading lights of the Perl Monger community. Sue S (former London.pm leader) was up first with a short and sweet description of London.pm. Todd R talked about Houston.pm. Aaron Crane spoke about the new improved friendlier p5p. Tina about Berlin.pm and the German Perl community site she had written back in the day. This new format worked very well and it was obvious Perl Mongers groups could learn much from each other. Max M followed with a talk about using Perl and ElasticSearch to index websites and documents and Job about accessibility.
1505 had, from the perspective of London.pm, one of the most unfortunate scheduling clashes at YAPC::EU ever, with three titans of London.pm (all former leaders) battling for audience share. I should perhaps tread carefully here lest bias become apparent but the heavyweight Sue Spence was, perhaps treacherously, talking about Go in the big room and Dave Cross and Tom talking about Perl errors and HTML forms respectively in the other rooms. This momentous event should be reproducible by playing all three talks together in separate windows once they are available.
Domm did a great talk on Postgres which made me keen to use this technology again. André W described how he got Perl 6 running on his Sailfish module phone while Larry did a good impression of a microphone stand. I missed most of Lance Wick’s talk but the bit I caught at the end made me eager to watch the whole thing.
Guinevere Nell gave a fascinating lightning talk about agent based economic modelling. Lauren Rosenfield spoke of porting (with permission) a “Python for CS” book to perl 6. Lukas Mai described his journey from Perl to Rust. Lee J talked about photography before Sue encouraged people to break the London.pm website. Outside the talk rooms on their stall Liz and Wendy had some highly cool stuffed toy Camelia butterflies produced by the Beverly Hills Teddy Bear Company and some strange “Camel Balls” bubblegum. At the end of the day Sue cat herded many Mongers to eat at the Enigma Steampunk Bar in central Cluj with the cunning ploy of free beer money (recycled from the previous year’s Sherry money).
The third day started with Larry’s Keynote in which photographs of an incredible American house “Fallingwater” and Chinese characters (including “arse rice”) featured heavily. Sweth C gave a fast and very useful introduction to swift. Nicholas C then confused a room of people for an hour with a mixture of real Perl 5 and 6 and an alternative timeline compete with T shirts. The positive conclusion was that even if the past had been different the present isn’t likely to have been much better for the Perl language family than it is now! Tom spoke about Code Review and Sawyer about new features in Perl 5.24. Later I heard Ilya talk about running Perl on his Raspberry PI Model B and increasing the speed of his application very significantly to compensate for its low speed! And we finished with lightning talks where we heard about the bug tracker OTRS (which was new to me), Job spoke about assistive tech and Nine asked us to ask our bosses for money for Perl development amongst several other talks. We clapped a lot in thanks, since this was clearly a particularly well organised YAPC::EU (due to Amalia and her team!) and left to eat pizza and fly away the next day. Some stayed to visit a salt mine (which looked most impressive from the pictures!) and some stayed longer due to Lufthansa cancelling their flights back!
The meeting first night was in a large beer bar in the centre of Nuremberg.
We went back to the Best Western to find a certain exPumpkin already resident in the bar.
Despite several of the well named Bitburgers we managed to arrive at the
conference venue on time the following morning. Since my knowledge of German was
limited to a C grade 'O' Level last century my review talks will be mostly
limited to English talks. Apologies in advance to those giving German talks
(not unreasonable considering the country). Hopefully other blog posts will
cover these.
Masak spoke about the dialectic between planning (like physics) and chaos (like
biology) in software development.
http://masak.org/carl/gpw-2016-domain-modeling/talk.pdf
Tobias gave a good beginners guide to Perl 6 in German and I was able to follow
most of the slides since I knew more Perl 6 than German and even learnt a thing
or two.
After lunch Stefan told us he was dancing around drunk and naked on the turn of
the 2000s and also about communication between Perl 6 and Perl 5 and back again
via his modules Inline::Perl5 (from Perl 6) -- the most important take away
being that "use Foo::Bar:from<Perl5>" can be used from Perl 6 and "use
Inline::Perl6" from Perl 5. The modules built bridges like those built in the
old school computer game "Lemmings".
http://niner.name/talks/Perl%205%20and%20Perl%206%20-%20a%20great%20team/Perl%205%20and%20Perl%206%20-%20a%20great%20team.odp
Max told us (in German) about his Dancer::SearchApp search
engine which has based on Elastic Search but I was able to follow along on the
English version of his slides on the web.
http://corion.net/talks/dancer-searchapp/dancer-searchapp.en.html
Sue got excited about this. Tina showed us some slides in Vim and her module
to add command line tab completion to script arguments using zsh and bash. I
wondered whether some of her code could be repurposed to add fish shell man
page parsing autocompletion to zsh. She also had a good lightening talk about
Ingy's command line utility for github.
https://github.com/perlpunk/myslides/tree/master/app-spec
Second day started early with Moritz talking about Continuous Delivery which
could mean just delivering to a staging server. He was writing a book about it
at deploybook.com with slides at:
https://deploybook.com/talks/gpw2016-continuous-delivery.pdf
Salve wanted us to write elegant code as a reply to the Perl Jam guy at CCC in
a self confessed "rant".
Sawyer described writing Ref::Util to optimise things like "ref $foo" in a
Hardcore Perl 5 XS/Core talk and Masak told us about his little 007 language
written in Perl 6 as a proof of concept playroom for future Perl 6 extended
macro support and demonstrated code written over lunch in support of this.
http://masak.org/carl/gpw-2016-big-hairy-yaks/talk.pdf
Stefan gave a great talk about CURLI and explained the complexity of what was
intended.
I gave my talk on "Simple Perl 6 Fractals and Concurrency" on Friday. It
started badly with AV issues my side but seemed well received. It was useful
speaking with people about it and I managed to speed things up *after* the talk
and I should have new material for a 2.0 version.
There were very good talks on extracting data from PDFs and writing JSON apis.
https://github.com/mickeyn/PONAPI
looked very interesting and would have saved me much coding at a recent job.
There were some great lightening talks at th end of the day. Sawyer wanted
people to have English slides and gave his talk in Hebrew to stress this.
Things ended Friday night with great food and beer in a local bar.
To me It seemed a particularly good FOSDEM for both for Perl5/6 and
other talks although very crowded as usual and I didn't see the usual
*BSD or Tor stalls. I was stuck by the statistic that there were
about 500 speakers from many thousands of people so of the order of
one speaker per tens of attendees which is very high.
Videos are already starting to appear at
On Saturday I started with Poettering and systemd which was a keynote
and perhaps a little disappointing since he usually is a better
speaker and the audio was a little indistinct. systemd had won being
used by all distros except gentoo and slackware. They were now working
on a dns resolver component which supported DNSSEC although in
practice validating signed zone files would slow down browsing and
currently only 2% of websites had it activated. He didn't mention
strong criticisms of its security by crypto experts such as DJB.
The most amusing talk was Stark's retro running of Postgres on
NetBSD/VAX which exposed some obscure OS bugs and was livened up by a
man in an impressive Postgres Elephant costume appearing. We later
spoke to Mr Elephant who said he was both blind and very hot at the
time. I then went to the Microkernel room to hear about GNU/Hurd
progress from Thibault since this room is usually "OPEN" and he's an
excellent speaker. I noticed even this obscure room was quite crowded
as compared with previous years so I'd guess total attendees this year
were high. He stressed the advantages of running device drivers in
userspace as allowing more user "freedom" to mount fs etc. without
root and improving kernel stability since the drivers could crash and
restart without bringing down the kernel. In previous years he had
talked of his DDE patches allowing linux 2.6 hardware drivers on Hurd
and this year he was using the NetBSD Rump kernel under Hurd to add
sound support with USB support promised. His demo was RMS singing his
song on his Hurd laptop. The irony was he needed to use BSD code on a
GNU/BSD/Hurd system to do it! There had been some work on X86-64 Hurd
but it wasn't there yet since he needed more help from the community.
I then saw some lightening talks (actually 20 mins long) including a
good one on C refactoring.
The Perl dinner on Saturday night featured the usual good food and
conversation and the devroom was on Sunday. Ovid spoke about Perl 6
and its advantages (such as being able to perform maths on floats
correctly). I had a python guy sitting next to me who admitted he had
never been to a Perl talk before so that was a success in reaching
someone new. Will Braswell spoke next about his "Rperl" compiler
which translated his own quite restricted subset (no regexps yet and
no $_) of Perl 5 line by line into C++ in order to run some of the
language shootups benchmarks (a graphical animation of planetary
motion) at increased speed. I'd not seen Will before and he was an
excellent speaker who left me more impressed than I'd expected and I
hope he gets to YAPC::EU in the summer. I saw some non-Perl stuff
next for variety including a good one on the Go debugger Delve which
was aware of the go concurrency and could be used as a basic REPL. I
returned to Perl to see Bart explain some surprisingly simple X86-64
assembly language to do addition and ROT13 which he interfaced with
Perl 6 using NativeCall (although it stuck me that the
CPAN P5NCI module on Perl 5 would have also worked).
Again an excellent talk and a good start to the a
run of some of the best Perl talks I'd ever seen. Stevan Little's talk
was one of the his most amusing ever and perl wasn't really dead.
Sawyer also did an excellent promotion of Perl 5 targeted at the
people who maybe hadn't used it since the early 2000s explaining what
had changed. Liz finished with her autobiographical account of Perl
development and some nice short Perl 6 examples. We all ate again in
the evening together my only regrets being I'd missed the odd talk or
two (which I should be able to watch on video).
MetaCPAN, like the rest of "CPAN", was built assuming the sole context of Perl5. Which is cool until we want to use it for Perl6 and avoid the troubles associated with different namespaces, dist mgmt, etc... To largely avoid and more easily handle these issues for MetaCPAN it's been suggested that we have separate instances. The existing Perl5 instance only needs to be changed to ignore Perl6 distributions. There has already been some breakage because it didn't ignore a Perl6 dist of mine which exists in the Perl5 world:( And the new Perl6 instance will do just the opposite and only look at Perl6 distributions.
In contrast, and relatedly, on CPAN we've designated a special spot for Perl6 distributions in order to keep them separate from the Perl5 dists. This reserved place is a Perl6 subdir in an author's dir (/author/id/*/*/*/Perl6/). Any dists in or under that spot on the fs will be considered a Perl6 dist; valid or invalid. So this is where the Perl6 MetaCPAN will look and the Perl5 instance will not.
Current development is being done on these temporary branches:
And the main dev instance is running on hack.p6c.org. The web end is at http://hack.p6c.org:5001 and the api is at http://hack.p6c.org:5000.
So far the idea has been to iterate on the aforementioned branches and instance until we have something that works sufficiently well. At that point we'll tidy up the branches and submit them for merging. Shortly after that time the hope is that we'll be able to stand up the official Perl6 instance.
The list of requirements for being adequately cooked is:
All of these have been hacked in and are at various degrees of completeness. Next up is testing and fixing bugs until nothing major is left. To that end I've recently loaded up the dev instance with all the distributions from modules.perl6.org. The dist files were generated, very hackily, with https://github.com/jdv/cpan-api/blob/master/test_p6_eco_to_p6_cpan.pl. I also just loaded them all under one user, mine, for simplicity. That load looks like it has problems of its own as well as revealing a bunch of issues. So in the coming days I hope to get that all sorted out.
In the Perl5 world, just in case anyone is unaware, CPAN is a major factor. Its basically the hub of the Perl5 world.
What I am referring to here as CPAN is not just the mirrored collection of 32K+ distributions. Its the ecosystem that's built up around that collection. This ecosystem has many parts, some more important than others depending on who you talk to, but the most important parts to me are:
These are the 5 aspects of "CPAN" that I'd like to see happen for Perl6. One way to get that would be to write the whole thing from scratch in Perl6. While it may sound cool in some sort of dogfoody and/or bootstrappy kind of way to some, it sounds like a lot of work to me and we're a bit strapped for developer resources. Another way would be to add support for Perl6 to the existing CPAN bits. The hope there being, primarily, that it'd be a lot less work. The latter approach is what I've been working on lately. And if we want to refactor ourselves off the Perl5 bits in the future we can take our time doing it; later.
At this time we have:So we can publish Perl6 distributions to CPAN and search that collection. Well, sort of on that last bit. The metacpan prototype instance is not currently tracking CPAN. Its actually been loaded up with Perl6 distributions from the Perl6 module ecosystem (modules.perl6.org) for testing. But hopefully soon we'll have an official Perl6 metacpan instance, separate from the Perl5 instance, that will track CPAN's Perl6 content as it should.
What we need next is:If anyone is interested in working on any of this stuff please stop by #perl6 on freenode. If nobody else is able to help you I'll (jdv79) do my best.
Thanks to those on Freenode IRC/perl6 for help.
Further corrections and expansions welcome either on iRC via pull request to https://github.com/stmuk/glr-html
| pre GLR | GLR |
|
| LIST IS NOW PARCEL |
> say (1,2,3).WHAT (Parcel) |
> say (1,2,3).WHAT (List) |
| LACK OF IMPLICIT LIST FLATTENING |
> my @array = 1,(2,3),4 1 2 3 4 > @array.elems 4 |
my @array = 1,(2,3),4 [1 (2 3) 4] > @array.elems 3 to flatten> my @list := 1, [2, 3], 4 (1 [2 3] 4) > dd @list.flat.list (1, 2, 3, 4) or> my @array = (1,(2,3),4).flat [1 2 3 4] or more complex structures (jnthn++)say gather [[[[["a", "b"], "c"], "a"], "d"], "e"].deepmap(*.take) |
| .lol METHOD REMOVED |
> dd (1,2,3).lol (1; 2; 3) |
|
| SINGLE ARG RULE |
> dd (1,) (1,) > dd [1,] $ = [1] > dd [[1,]] $ = [[1]] |
> dd (1,) (1) > dd [1,] [1] > dd [[1],] [[1],] |
| LIST NOW IMMUTABLE |
> my @array = 1,2,3 1 2 3 > @array.shift 1 > dd @array @array = [2, 3]<> |
> my @list := 1,2,3 (1 2 3) > @list.shift Method 'shift' not found for invocant of class 'List' > @list[0] 1 > dd @list (1, 2, 3) |
| ARRAY IS MUTABLE AND A SUBCLASS OF LIST |
> my @array = 1,2,3 [1 2 3] > @array[0]=0 0 > dd @array @array = [0, 2, 3] >say (Array).^mro ((Array) (List) (Cool) (Any) (Mu)) |
|
| SLIP SUBCLASS OF LIST |
> my @a = 1, (2, 3).Slip, 4 [1 2 3 4] > my $slip = slip(2,3) (2 3) > dd $slip Slip $slip = $(2, 3) > my @array = 1,$slip,4 [1 2 3 4] > (1,$(2,3),4) (1 (2 3) 4) > (1,|(2,3),4) (1 2 3 4) |
|
| SEQUENCE |
> my $grep = (1..4).grep(*>2); dd $grep>>.Int; (3, 4) > dd $grep>>.Int; This Seq has already been iterated, and its values consumed in block prevent consumption> my $grep = (1..4).grep(*>2); my $cache=$grep.cache (3 4) > say $cache>>.Int (3 4) > say $cache>>.Int (3 4) > my @array = 1,(2,3),4 [1 (2 3) 4] > dd @array.flat (1, $(2, 3), 4).Seq > dd @array.flat.list (1, $(2, 3), 4) |


So we are anticipating a long rollout cycle for PHP 6, and we did not want to take the same route that the Perl project did, with project contributors still working on Perl 6 I think six years later. People make fun of Microsoft, but take a look at Perl 6. . . .
Sure, PHP 6 may have a shorter release cycle than Perl 6 has, but at the end of it all, we'll have Perl 6, and you'll still have PHP.So how did those predictions work out? Well, after a little over six years of development, we discovered that we were never going to see a PHP 6 at all. Having seen how long Perl 6 had taken, and how long PHP 6 was taking, the number 6 is associated with failure. So they cancelled PHP 6 and voted to change the name to PHP 7. Problem solved! No, really, this is some of the actual reasoning given by people on the 6 to 7 RFC. (Someone should tell the ES6 folks before the curse strikes our browsers!)
Just sayin'.
xoxo,
Andy
print removed in favor of function print(), ostensibly to make a consistent API but really just to mess with people.At FOSDEM 2015, Larry announced that there will likely be a Perl 6 release candidate in 2015, possibly around the September timeframe. What we’re aiming for is concurrent publication of a language specification that has been implemented and tested in at least one usable compilation environment — i.e., Rakudo Perl 6.
So, for the rest of 2015, we can expect the Rakudo development team to be highly focused on doing only those things needed to prepare for the Perl 6 release later in the year. And, from previous planning and discussion, we know that there are three major areas that need work prior to release: the Great List Refactor (GLR), Native Shaped Arrays (NSA), and Normalization Form Grapheme (NFG).
…which brings us to Parrot. Each of the above items is made significantly more complicated by Rakudo’s ongoing support for Parrot, either because Parrot lacks key features needed for implementation (NSA, NFG) or because a lot of special-case code is being used to maintain adequate performance (lists and GLR).
At present most of the current userbase has switched over to MoarVM as the backend, for a multitude of reasons. And more importantly, there currently aren’t any Rakudo or NQP developers on hand that are eager to tackle these problems for Parrot.
In order to better focus our limited resources on the tasks needed for a Perl 6 language release later in the year, we’re expecting to suspend Rakudo’s support for the Parrot backend sometime shortly after the 2015.02 release.
Unfortunately the changes that need to be made, especially for the GLR, make it impractical to simply leave existing Parrot support in place and have it continue to work at a “degraded” level. Many of the underlying assumptions will be changing. It will instead be more effective to (re)build the new systems without Parrot support and then re-establish Parrot as if it is a new backend VM for Rakudo, following the techniques that were used to create JVM, MoarVM, and other backends for Rakudo.
NQP will continue to support Parrot as before; none of the Rakudo refactorings require any changes to NQP.
If there are people that want to work on refactoring Rakudo’s support for Parrot so that it’s more consistent with the other VMs, we can certainly point them in the right direction. For the GLR this will mainly consists of migrating parrot-specific code from Rakudo into NQP’s APIs. For the NSA and NFG work, it will involve developing a lot of new code and feature capabilities that Parrot doesn’t possess.
This past weekend I attended the 2014 Austrian Perl Workshop and Hackathon in Salzburg, which turned out to be an excellent way for me to catch up on recent changes to Perl 6 and Rakudo. I also wanted to participate directly in discussions about the Great List Refactor, which has been a longstanding topic in Rakudo development.
What exactly is the “Great List Refactor” (GLR)? For several years Rakudo developers and users have identified a number of problems with the existing implementation of list types — most notably performance. But we’ve also observed the need for user-facing changes in the design, especially in generating and flattening lists. So the term GLR now encompasses all of the list-related changes that seem to want to be made.
It’s a significant (“great”) refactor because our past experience has shown that small changes in the list implementation often have far-reaching effects. Almost any bit of rework of list fundamentals requires a fairly significant refactor throughout much of the codebase. This is because lists are so fundamental to how Perl 6 works internally, just like the object model. So, as the number of things that are desirable to fix or change has grown, so has the estimated size of the GLR effort, and the need to try to achieve it “all at once” rather than piecemeal.
The pressure to make progress on the GLR has been steadily increasing, and APW2014 was significant in that a lot of the key people needed for that would be in the same location. Everyone I’ve talked to agrees that APW2014 was a smashing success, and I believe that we’ve now resolved most of the remaining GLR design issues. The rest of this post will describe that.
This is an appropriate moment to recognize and thank the people behind the APW effort. The organizers did a great job. The Techno-Z and ncm.at venues were fantastic locations for our meetings and discussions, and I especially thank ncm.at, Techno-Z, yesterdigital, and vienna.pm for their generous support in providing venues and food at the event.
So, here’s my summary of GLR issues where we were able to reach significant progress and consensus.
(Be sure to visit our gift shop!)
Much of the GLR discussion at APW2014 concerned flattening list context in Perl 6. Over the past few months and years Perl 6 has slowly but steadily reduced the number of functions and operators that flatten by default. In fact, a very recent (and profound) change occurred within the last couple of months, when the .[] subscript operator for Parcels switched from flattening to non-flattening. To illustrate the difference, the expression
(10,(11,12,13),(14,15)).[2]
previously would flatten out the elements to return 12, but now no longer flattens and produces (14,15). As a related consequence, .elems no longer flattens either, changing from 6 to 3.
Unfortunately, this change created a inconsistency between Parcels and Lists, because .[] and .elems on Lists continued to flatten. Since programmers often don’t know (or care) when they’re working with a Parcel or a List, the inconsistency was becoming a significant pain point. Other inconsistencies were increasing as well: some methods like .sort, .pick, and .roll have become non-flattening, while other methods like .map, .grep, and .max continue to flatten. There’s been no really good guideline to know or decide which should do which.
Flattening behavior is great when you want it, which is a lot of the time. After all, that’s what Perl 5 does, and it’s a pretty popular language. But once a list is flattened it’s hard to get the original structure if you wanted that — flattening discards information.
So, after many animated discussions, review of lots of code snippets, and seeking some level of consistency, the consensus on Perl 6 flattening behavior seems to be:
[ ] array constructor are unchanged; they continue to flatten their input elements. (Arrays are naturally flat.)for @a,@b { ... } flattens @a,@b and applies the block to each element of @a followed by each element of @b. Note that flattening can easily be suppressed by itemization, thus for @a, $@b { ... } flattens @a but does all of @b in a single iteration..map, .grep, and .first… the programmer will have to use .flat.grep and .flat.first to flatten the list invocant. Notably, .map will no longer flatten its invocant — a significant change — but we’re introducing .for as a shortcut for .flat.map to preserve a direct isomorphism with the for statement.There’s ongoing conjecture of creating an operator or syntax for flattening, likely a postfix of some sort, so that something like .|grep would be a convenient alternative to .flat.grep, but it doesn’t appear that decision needs to be made as part of the GLR itself.((1,2), 3, (4,5)).map({...}) # iterates over three elements
map {...}, ((1,2),3,(4,5)) # iterates over five elements
(@a, @b, @c).pick(1) # picks one of three arrays
pick 1, @a, @b, @c # flatten arrays and pick one element
As a result of improvements in flattening consistency and behavior, it appears that we can eliminate the Parcel type altogether. There was almost unanimous agreement and enthusiasm at this notion, as having both the Parcel and List types is quite confusing.
Parcel was originally conceived for Perl 6 as a “hidden type” that programmers would rarely encounter, but it didn’t work out that way in practice. It’s nice that we may be able to hide it again — by eliminating it altogether. 
Thus infix:<,> will now create Lists directly. It’s likely that comma-Lists will be immutable, at least in the initial implementation. Later we may relax that restriction, although immutability also provides some optimization benefits, and Jonathan points out that may help to implement fixed-size Arrays.
Speaking of optimization, eliminating Parcel may be a big boost to performance, since Rakudo currently does a fair bit of converting Parcels to Lists and vice-versa, much of which goes away if everything is a List.
During a dinner discussion Jonathan reminded me that Synopsis 4 has all of the looping constructs as list generators, but Rakudo really only implements for at the moment. He also pointed out that if the loop generators are implemented, many functions that currently use gather/take could potentially use a loop instead, and this could be much more performant. After thinking on it a bit, I think Jonathan is on to something. For example, the code for IO::Handle.lines() currently does something like:
gather {
until not $!PIO.eof {
$!ins = $!ins + 1;
take self.get;
}
}
With a lazy while generator, it could be written as
(while not $!PIO.eof { $!ins++; self.get });
This is lazily processed, but doesn’t involve any of the exception or continuation handling that gather/take requires. And since while might choose to not be strictly lazy, but lines() definitely should be, we may also use the lazy statement prefix:
lazy while not $!PIO.eof { $!ins++; self.get };
The lazy prefix tells the list returned from the while that it’s to generate as lazily as it possibly can, only returning the minimum number of elements needed to satisfy each request.
So as part of the GLR, we’ll implement the lazy list forms of all of the looping constructs (for, while, until, repeat, loop). In the process I also plan to unify them under a single LoopIter type, which can avoid repetition and be heavily optimized.
This new loop iterator pattern should also make it possible to improve performance of for statements when performed in sink context. Currently for statements always generate calls to .map, passing the body of the loop as a closure. But in sink context the block of a for statement could potentially be inlined. This is the way blocks in most other loops are currently generated. Inlining the block of the body could greatly increase performance of for loops in sink context (which are quite common).
Many people are aware of the problem that constructs such as for and map aren’t “consuming” their input during processing. In other words, if you’re doing .map on a temporary list containing a million elements, the entire list stays around until all have been processed, which could eat up a lot of memory.
Naive solutions to this problem just don’t work — they carry lots of nasty side effects related to binding that led us to design immutable Iterators. We reviewed a few of them at the hackathon, and came back to the immutable Iterator we have now as the correct one. Part of the problem is that the current implementation is a little “leaky”, so that references to temporary objects hang around longer than we’d like and these keep the “processed” elements alive. The new implementation will plug some of the leaks, and then some judicious management of temporaries ought to take care of the rest.
In the past year much work has been done to improve sink context to Rakudo, but I’ve never felt the implementation we have now is what we really want. For one, the current approach bloats the codegen by adding a call to .sink after every sink-context statement (i.e., most of them). Also, this only handles sink for the object returned by a Routine — the Routine itself has no way of knowing it’s being called in sink context such that it could optimize what it produces (and not bother to calculate or return a result).
We’d really like each Routine to know when it’s being called in sink context. Perl 5 folks will instantly say “Hey, that’s wantarray!”, which we long ago determined isn’t generally feasible in Perl 6.
However, although a generalized wantarray is still out of reach, we can provide it for the limited case of detecting sink contexts that we’re generating now, since those are all statically determined. This means a Routine can check if it’s been called in sink context, and use that to select a different codepath or result. Jonathan speculates that the mechanism will be a flag in the callsite, and I further speculate the Routine will have a macro-like keyword to check that flag.
Even with detecting context, we still want any objects returned by a Routine to have .sink invoked on them. Instead of generating code for this after each sink-level statement, we can do it as part of the general return handler for Routines; a Routine in sink context invokes .sink on the object it would’ve otherwise returned to the caller. This directly leads to other potential optimizations: we can avoid .sink on some objects altogether by checking their type, and the return handler probably doesn’t need to do any decontainerizing on the return value.
As happy as I am to have discovered this way to pass sink context down into Routines, please don’t take this as opening an easy path to lots of other wantarray-like capabilities in Perl 6. There may be others, and we can look for them, but I believe sink context’s static nature (as well as the fact that a false negative generally isn’t harmful) makes it quite a special case.
One area that has always been ambiguous in the Synopses is determining when various contextualizing methods must return a copy or are allowed to return self. For example, if I invoke .values on a List object, can I just return self, or must I return a clone that can be modified without affecting the original? What about .list and .flat on an already-flattened list?
The ultra-safe answer here is probably to always return a copy… but that can leave us with a lot of (intermediate) copies being made and lying around. Always returning self leads to unwanted action-at-a-distance bugs.
After discussion with Larry and Jonathan, I’ve decided that true contextualizers like .list and .flat are allowed to return self, but other method are generally obligated to return an independent object. This seems to work well for all of the methods I’ve considered thus far, and may be a general pattern that extends to contextualizers outside of the GLR.
(small matter of programming and documentation)
The synopses — especially Synopsis 7 — have always been problematic in describing how lists work in Perl 6. The details given for lists have often been conjectural ideas that quickly prove to epic fail in practice. The last major list implementation was done in Summer 2010, and Synopsis 7 was supposed to be updated to reflect this design. However, the ongoing inconsistencies (that have led to the GLR) really precluded any meaningful update to the synopses.
With the progress recently made at APW2014, I’m really comfortable about where the Great List Refactor is leading us. It won’t be a trivial effort; there will be significant rewrite and refactor of the current Rakudo codebase, most of which will have to be done in a branch. And of course we’ll have to do a lot of testing, not only of the Perl 6 test suite but also the impact on the module ecosystem. But now that much of the hard decisions have been made, we have a roadmap that I hope will enable most of the GLR to be complete and documented in the synopses by Thanksgiving 2014.
Stay tuned.
"I'm just happy that the two of you liked my work." -- vanstynAlthough he was talking about DBIx, I think that captures the spirit of conference as a whole. All of us here -- from the n00bs to the pumpkings -- want to share our work and make something useful for others. It's not an organization where we wait for pronouncements from on high, but one where users create endless variations and share them. Not an organization so much as a family.
"We have faith, hope, and love, but the most awesome of these is love." -- Larry WallA line like this might seem a bit hokey out of context, but it was actually moving when I heard it. We have faith that we can use Perl to solve our problems. We have hope that Perl 5 and 6 will continue to get better. And we love Perl, unconditionally, despite all of her flaws. And as Wil Wheaton says about us geeks, we just want to love our special thing the best we can, and go the extra mile to share it with others.
[This is a response to the Russian Perl Podcast transcribed by Peter Rabbitson and discussed at blogs.perl.org.]
I found this translation and podcast to be interesting and useful, thanks to all who put it together.
Since there seems to have been some disappointment that Perl 6 developers didn’t join in the discussions about “Perl 7” earlier this year, and in the podcast I’m specifically mentioned by name, I thought I’d go ahead and comment now and try to improve the record a bit.
While I can’t speak for the other Perl 6 developers, in my case I didn’t contribute to the discussion because nearly all the things I would’ve said were already being said better by others such as Larry, rjbs, mst, chromatic, etc. I think a “Perl 7” rebrand is the wrong approach, for exactly the reasons they give.
A couple of statements in the podcast refer to “hurting the feelings of Perl 6 developers” as being a problem resulting from a rebrand to Perl 7. I greatly appreciate that people are concerned with the possible impact of a Perl 5 rebrand on Perl 6 developers and our progress. I believe that Perl 6’s success or failure at this point will have little to do with the fact that “6 is larger than 5”. I don’t find the basic notion of “Perl 7” offensive or directly threatening to Perl 6.
But I fully agree with mst that “you can’t … have two successive numbers in two brands and not expect people to be confused.” We already have problems explaining “5” and “6” — adding more small integers to the explanation would just make an existing problem even worse, and wouldn’t do anything to address the fundamental problems Perl 6 was intended to resolve.
Since respected voices in the community were already saying the things I thought about the name “Perl 7”, I felt that adding my voice to that chorus could only be more distracting than helpful to the discussion. My involvement would inject speculations on the motivations of Perl 6 developers into what is properly a discussion about how to promote progress with Perl 5. I suspect that other Perl 6 developers independently arrived at similar conclusions and kept silent as well (Larry being a notable exception).
I’d also like to remark on a couple of @sharifulin’s comments in the podcast (acknowledging that the transcribed comments may be imprecise in the translation from Russian):
First, I’m absolutely not the “sole developer” of Perl 6 (13:23 in the podcast), or even the sole developer of Rakudo Perl 6. Frankly I think it’s hugely disrespectful to so flippantly ignore the contributions of others in the Perl 6 development community. Let’s put some actual facts into this discussion… in the past twelve months there have been over 6,500 commits from over 70 committers to the various Perl 6 related repositories (excluding module repositories), less than 4% (218) of those commits are from me. Take a look at the author lists from the Perl 6 commit logs and you may be a little surprised at some of the people you find listed there.
Second, there is not any sense in which I think that clicking “Like” on a Facebook posting could be considered “admitting defeat” (13:39 in the podcast). For one, my “Like” was actually liking rjbs’ reply to mst’s proposal, as correctly noted in the footnotes (thanks Peter!).
But more importantly, I just don’t believe that Perl 5 and Perl 6 are in a battle that requires there to be a conquerer, a vanquished, or an admission of defeat.
Pm
$foo->WHAT can tell you if you have a Str, Int, or IO::Handle. $path =~ s/^([a-z]:)/\l$1/s;//server/share) that OS2.pm had only half-implemented. And so a huge block of code cruft bit the dust.sub _tmpdir {
my $self = shift;
my @dirlist = @_;
my $tmpdir;
foreach (@dirlist) {
next unless defined && -d && -w _;
$tmpdir = $_;
last;
}
return $self->canonpath($tmpdir);
}$_, @_, and shift.method !tmpdir( *@dirlist ) {
my $tmpdir = first { .defined && .IO.w && .IO.d }, @dirlist;
return self.canonpath($tmpdir);
}$tmpdir to the first defined writable directory in @dirlist." Less, easier to read code is easier to maintain.if( $foo ) to if $foo, etc.git, and make -- enough to commit to repositories and build a software package, anyway.git clone it to on your own machine.rakudo directory. There are a few setup things that you'll want to do. First of all, go ahead and build Rakudo, using the normal steps: perl ./Configure.pl --gen-parrot
make
make install$PATH environment variable. Which, if you don't know how to do it -- well here's Google. In particular, you'll need to add the full path to the rakudo/install/bin directory. make spectestt/spec before hitting ^C. You will need these tests later to make sure you didn't break anything. git remote add upstream git://github.com/rakudo/rakudo.git git clone git://github.com/tadzik/panda.git
cd panda
perl6 bootstrap.pl git checkout -b mynewbranchnamerakudo/src folder, so this is where you'll want to edit the contents.vm directory contains files specific to the virtual machines Rakudo runs under. At this time of this writing, there's only one thing in there, parrot, but very soon there will also be a jvm directory. Exciting! Most of the purpose of this code is to map functions to lower-level operations, in either Parrot or Java.Perl6 directory contains the grammar and actions used to build the language, as well as the object metamodel. The contents of this folder are written in NQP, or Not Quite Perl. This section determines how the language is parsed.core directory contains the files that will be built into the core setting. You'll find classes or subroutines in here for just about everything in Perl: strings, operators like eq, filehandles, sets, and more. Individual files look similar to modules, but these are "modules" that are available to every Perl 6 program.gen directory contains files that are created in the compliation process. The core setting lives here, creatively named CORE.setting. And if you look at it, it's just a concatenation of the files in core, put together in the order specified in rakudo/tools/build/Makefile.in. While these files can and do get overwritten in the build process, it's often a good idea to keep a copy of CORE.setting open so you can find what you're looking for faster -- and then go edit it in core.git bisect for problems later. And push your edits to Github as a free backup. If you get stuck, drop by #perl6 on irc.freenode.net and ask questions. git fetch upstream
git merge upstream/nom
perl Configure.pl
make
make spectest #?pugs 1 skip 'reason'
#?niecza 1 skip 'reason'rakudo/t/spectest.data. If your code fixes broken tests, then you'll want to *unfudge* by removing the #?rakudo skip lines above the relevant tests. perl6 panda/rebootstrap.plgit commit; git push will add it to the ticket. If there aren't any problems, someone will just merge it in a couple days.At YAPC::NA 2012 in Madison, WI I gave a lightning talk about basic improvements in Rakudo’s performance over the past couple of years. Earlier today the video of the lightning talks session appeared on YouTube; I’ve clipped out my talk from the session into a separate video below. Enjoy!
A couple of weeks ago I entered the Dallas Personal Robotics Group Roborama 2012a competition, and managed to come away with first place in the RoboColumbus event and Line Following event (Senior Level). For my robot I used one of the LEGO Mindstorms sets that we’ve been acquiring for use by our First Lego League team, along with various 3rd party sensors.
The goal of the RoboColumbus event was to build a robot that could navigate from a starting point to an ending point placed as far apart as possible; robots are scored on distance to the target when the robot stops. If multiple robots touch the finish marker (i.e., distance zero), then the time needed to complete the course determines the rankings. This year’s event was in a long hall with the target marked by an orange traffic cone.

HiTechnic IR ball and IRSeeker sensor
Contestants are allowed to make minor modifications to the course to aid navigation, so I equipped my robot with a HiTechnic IRSeeker sensor and put an infrared (IR) electronic ball on top of the traffic cone. The IRSeeker sensor reports the relative direction to the ball (in multiples of 30 degrees), so the robot simply traveled forward until the sensor picked up the IR signal, then used the IR to home in on the traffic cone. You can see the results of the winning run in the video below, especially around the 0:33 mark when the robot makes its first significant IR correction:
http://youtu.be/x1GvpYAArfY
My first two runs of RoboColumbus didn’t do nearly as well; the robot kept curving to the right for a variety of reasons, and so it never got a lock on the IR ball. Some quick program changes at the contest and adjustments to the starting direction finally made for the winning run.
For the Line Following contest, the course consisted of white vinyl tiles with electrical tape in various patterns, including line gaps and sharp angles. I used a LineLeader sensor from mindsensors.com for basic line following, with some heuristics for handling the gap conditions. The robot performed fine on my test tiles at home, but had difficulty with the “gap S curve” tiles used at the contest. However, my robot was the only one that successfully navigated the right angle turns, so I still ended up with first place.
Matthew and Anthony from our FLL robotics team also won other events in the contest, and there are more videos and photos available. The contest was a huge amount of fun and I’m already working on new robot designs for the next competition.
Many thanks to DPRG and the contest sponsors for putting on a great competition!

{kind=link}
{kind=link}